Module LLM
SKU:M140










Description
Module LLM is an integrated offline large language model (LLM) inference module, designed for terminal devices that require efficient and intelligent interaction. Whether in smart homes, voice assistants, or industrial control, Module LLM can provide you with a smooth and natural AI experience without relying on the cloud, ensuring privacy, security, and stability.
This module integrates the StackFlow framework, and with the Arduino/UiFlow library, you can easily achieve edge-side intelligence with just a few lines of code. Equipped with the AX630C SoC processor, it integrates a 3.2TOPs high-efficiency NPU, natively supporting Transformer models, and can easily handle complex AI tasks. It comes with 4GB LPDDR4 memory (1GB for user use, 3GB dedicated to hardware acceleration) and 32GB eMMC storage, supporting parallel loading and serial inference of multiple models, ensuring smooth multitasking. The operating power consumption is only about 1.5W, much lower than similar products, making it energy-efficient and suitable for long-term operation.
Module LLM integrates a microphone, speaker, TF storage card, USB OTG, and RGB status light, meeting diverse application needs and easily enabling voice interaction and data transmission. In terms of flexible expansion, the onboard SD card slot supports firmware cold/hot upgrades, and the UART communication interface simplifies connection and debugging, ensuring continuous optimization and expansion of module functions. The USB port supports automatic master/slave switching, serving as both a debugging port and allowing connection to more USB devices such as cameras. Paired with the LLM debugging kit, it can expand to a 100M Ethernet port and kernel serial port, functioning as an SBC.
This module is compatible with multiple models and comes pre-installed with the Qwen2.5-0.5B large language model, featuring built-in KWS (wake word), ASR (speech recognition), LLM (large language model), and TTS (text-to-speech) functions, supporting separate calls or pipeline automatic flow, making development convenient. It will later support Qwen2.5-1.5B, Llama3.2-1B, and InternVL2-1B, among other edge-side LLM/VLM models, supporting hot updates to keep up with community trends and adapt to AI tasks of varying complexity. In terms of visual recognition capabilities, it supports CLIP, YoloWorld, and other Open world models, with future updates including DepthAnything, SegmentAnything, and other advanced models, empowering intelligent recognition and analysis.
Module LLM is plug-and-play, paired with M5 hosts, enabling a plug-and-play AI interaction experience. Users can integrate it into existing smart devices without complicated setups, quickly enabling intelligent functions and enhancing device intelligence. This product is suitable for offline voice assistants, text-to-speech conversion, smart home control, interactive robots, and more.
Tutorial


Features
- Offline inference, 3.2T@INT8 precision computing power
- Integrated KWS (wake word), ASR (speech recognition), LLM (large language model), TTS (text-to-speech)
- Multiple model parallelism
- Onboard 32GB eMMC storage and 4GB LPDDR4 memory
- Onboard microphone and speaker
- Serial communication
- SD card firmware upgrade
- Supports ADB debugging
- RGB indicator light
- Built-in Ubuntu system
- Supports OTG function
- Supports Arduino/UIFlow
Includes
- 1 x Module LLM

Debugging board included with the product (limited to initial release)
Applications
- Offline voice assistant
- Text-to-speech conversion
- Smart home control
- Interactive robots
Specifications
| Specification | Parameter |
|---|---|
| Processor SoC | AX630C@Dual Cortex A53 1.2 GHz MAX.12.8 TOPS @INT4, and 3.2 TOPS @INT8 |
| Memory | 4GB LPDDR4 (1GB system memory + 3GB dedicated to hardware acceleration) |
| Storage | 32GB eMMC5.1 |
| Communication Interface | Serial communication, default baud rate 115200@8N1 (adjustable) |
| Microphone | MSM421A |
| Audio Driver | AW8737 |
| Speaker | 8Ω@1W, size: 2014 cavity speaker |
| Built-in Functional Units | KWS (wake word), ASR (speech recognition), LLM (large language model), TTS (text-to-speech) |
| RGB Light | 3x RGB LED@2020 driven by LP5562 (status indicator) |
| Power Consumption | Idle: 5V@0.5W, Full load: 5V@1.5W |
| Button | Used for entering download mode for firmware upgrade |
| Upgrade Interface | SD card/Type C port |
| Operating Temperature | 0-40°C |
| Product Size | 54.0 x 54.0 x 13.0mm |
| Product Weight | 17.1g |
| Package Size | 132.0 x 95.0 x 16.0mm |
| Gross Weight | 30.7g |
Schematics

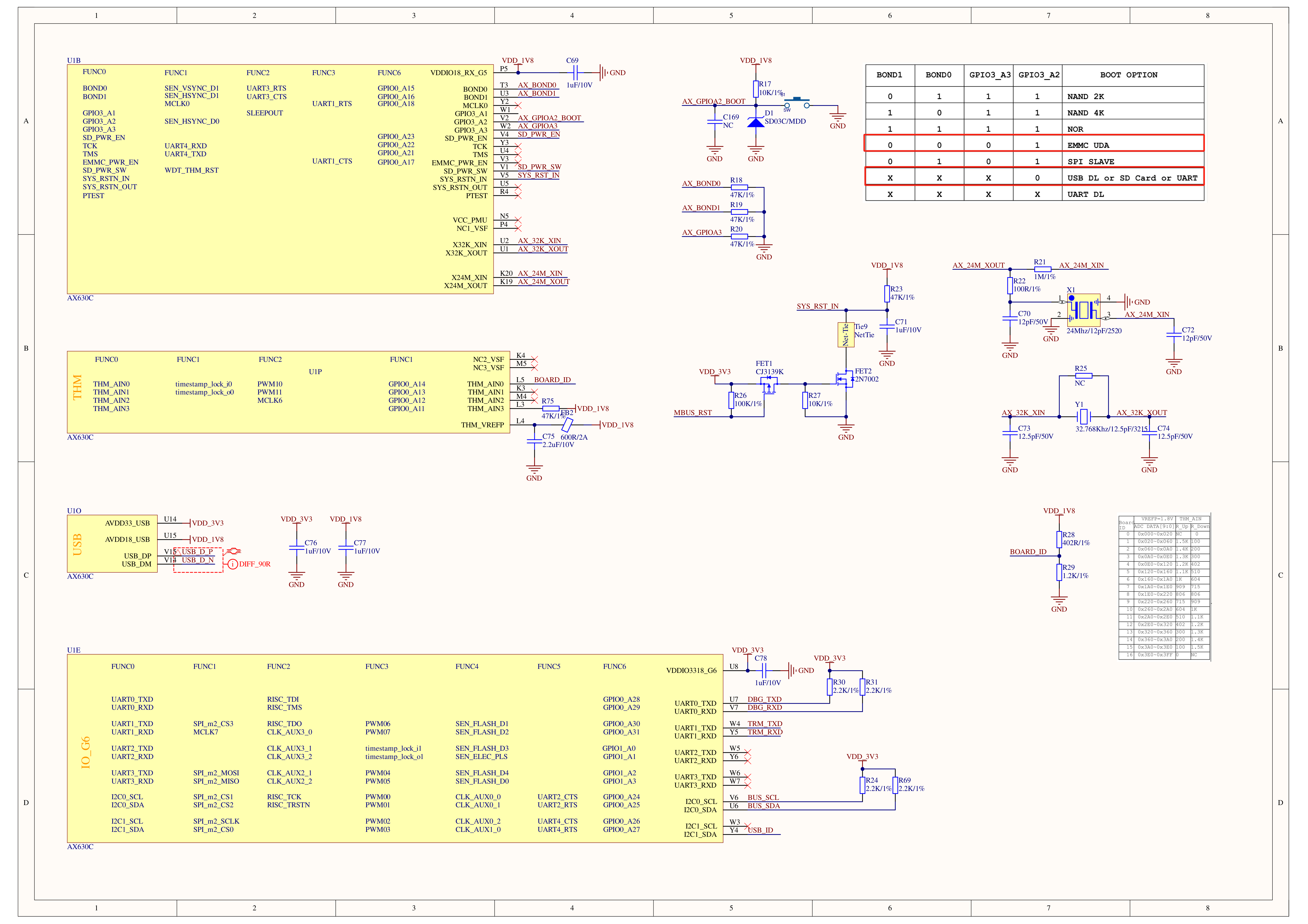
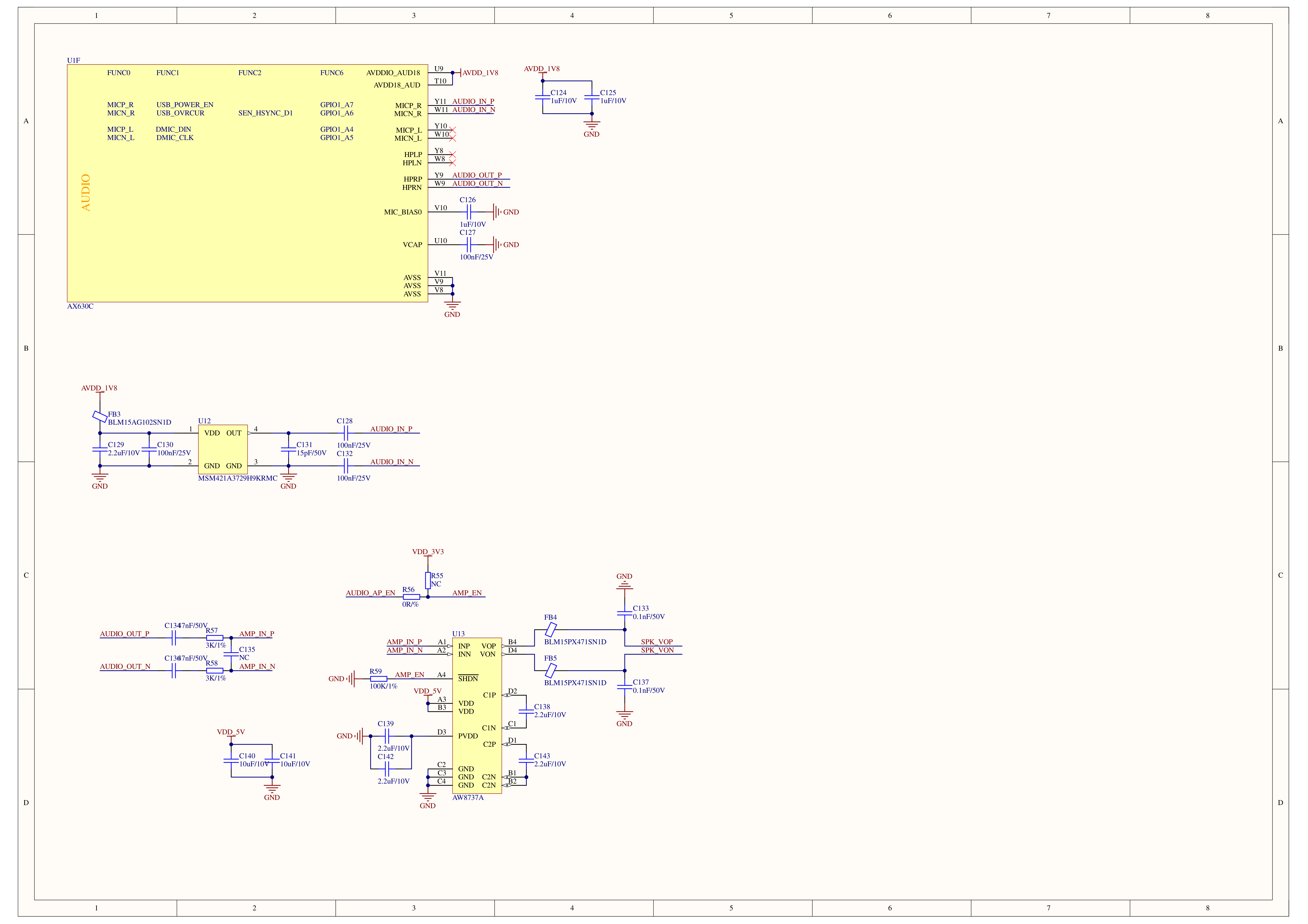
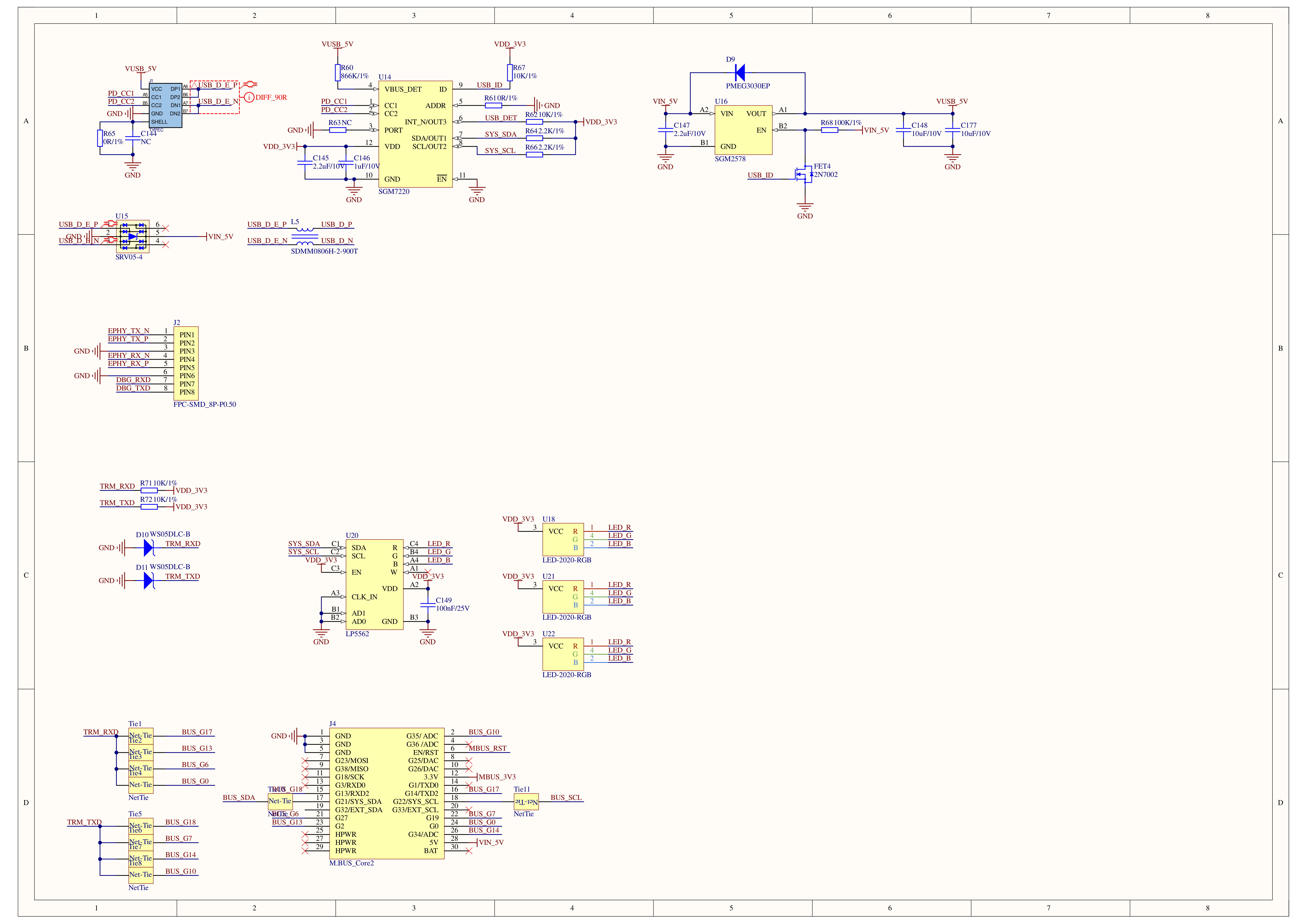

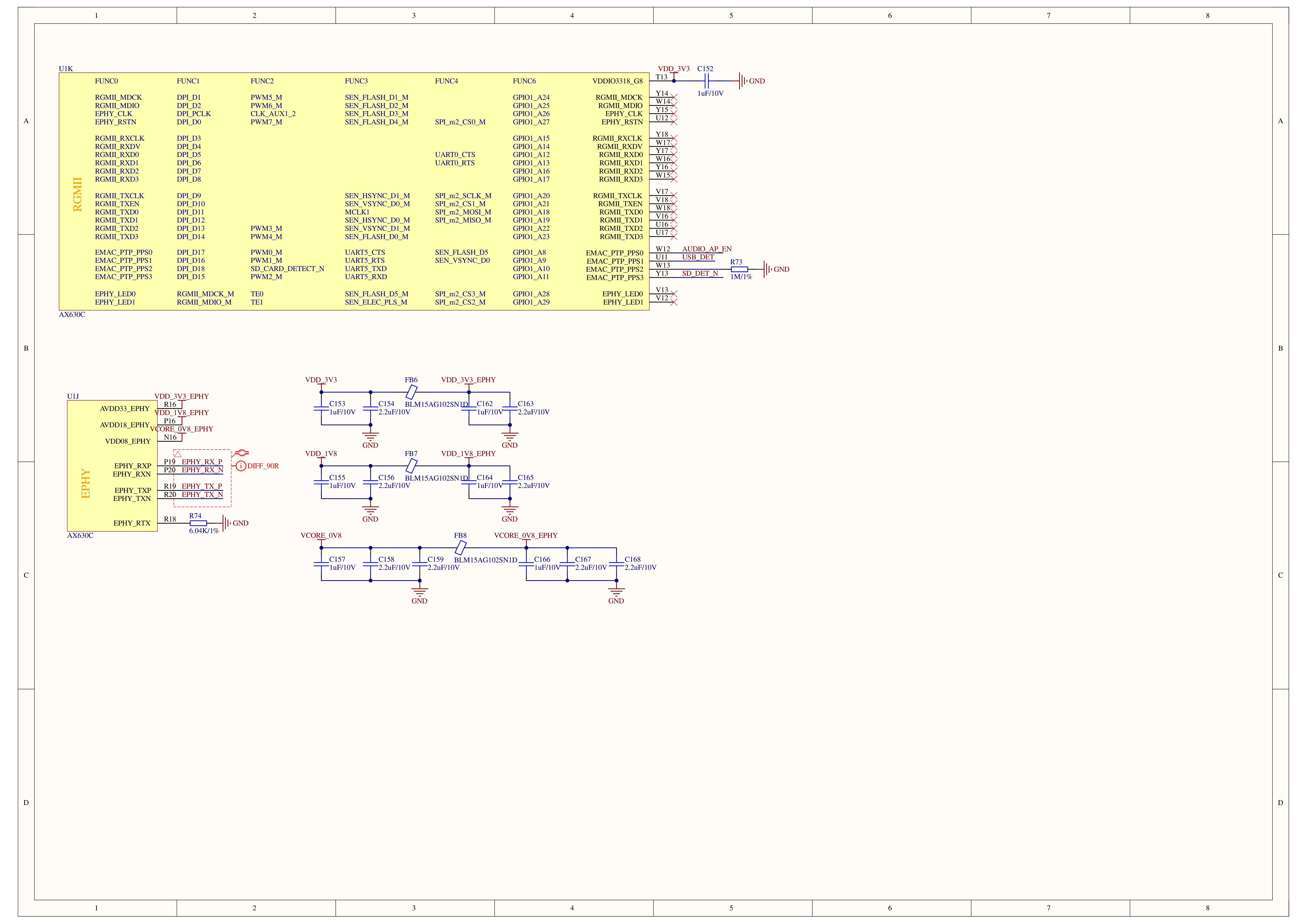
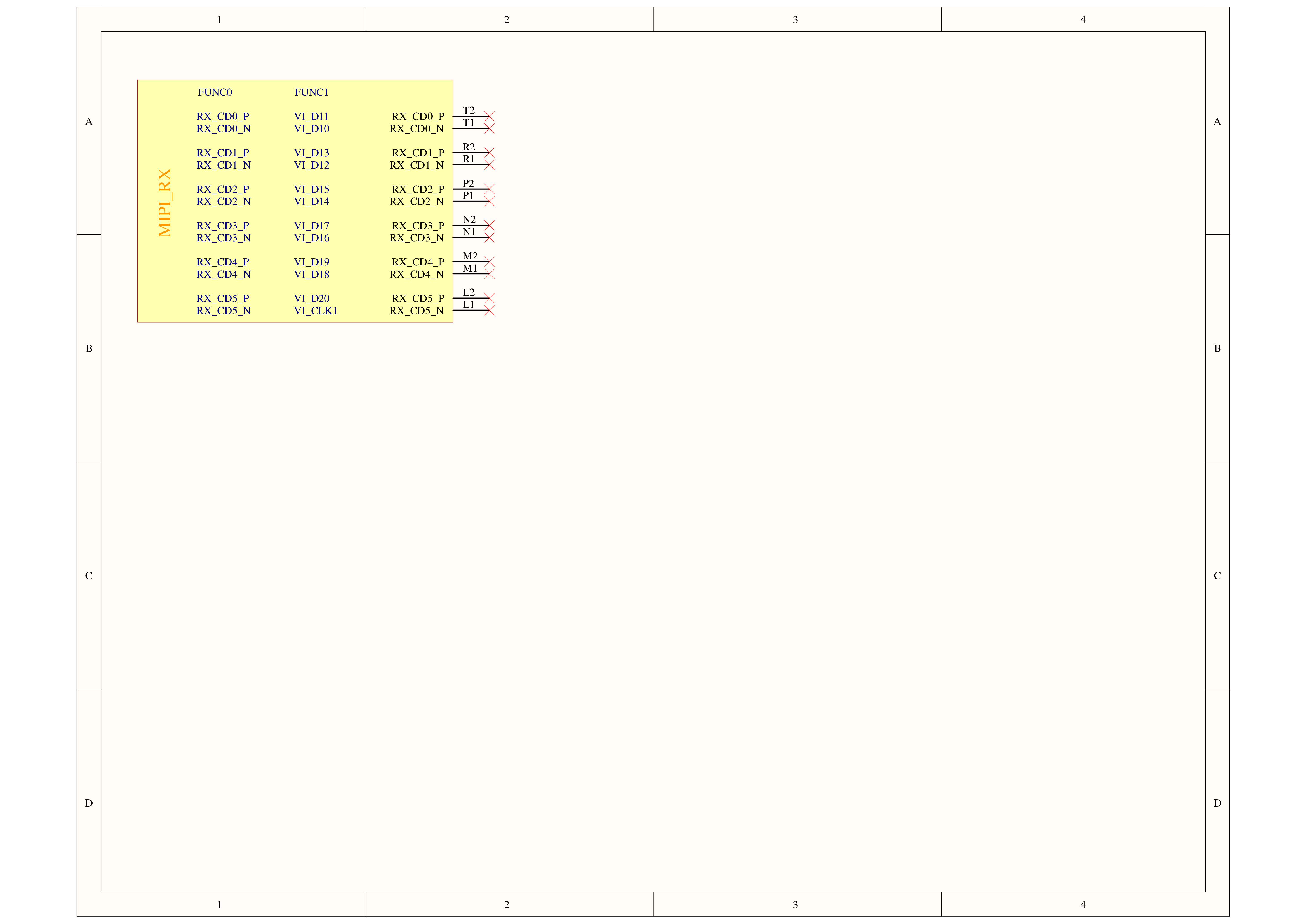
PinMap

Taking CoreS3 as an example, the first column (left green box) is the TX pin for serial communication. Users can choose one of four options (from top to bottom representing pins G18, G7, G14, G10). The default is the IO18 pin. If you need to switch to another pin, cut the pad connection (red line) (recommended to use a blade), and then connect to one of the three pins below. The second column (right green box) is the RX pin switching, as described above, also a four-option operation.
M5-Bus
NT in the M5-Bus table below can be switched via the above operation to adapt to different main control devices.| PIN | LEFT | RIGHT | PIN |
|---|---|---|---|
| GND | 1 | 2 | TRM_TXD(NT) |
| GND | 3 | 4 | |
| GND | 5 | 6 | RST |
| 7 | 8 | ||
| 9 | 10 | ||
| 11 | 12 | 3V3 | |
| 13 | 14 | ||
| TRM_TXD(NT) | 15 | 16 | TRM_RXD(NT) |
| SoC_SDA | 17 | 18 | SoC_SCL |
| 19 | 20 | ||
| TRM_RXD(NT) | 21 | 22 | TRM_TXD(NT) |
| TRM_RXD(NT) | 23 | 24 | TRM_RXD(NT) |
| 25 | 26 | TRM_TXD(NT) | |
| 27 | 28 | 5V | |
| 29 | 30 |
Model Size

Datasheets
Softwares
Quick Start
Module LLM Status Indicator:
- Red: Device initializing
- Green: Device initialization complete
Module LLM Application Upgrade Status Indicator:
- Blue blinking: Application package updating
- Red: Application package upgrade failed
- Green: Application package upgrade successful
Arduino
UiFlow1
UiFlow2
OpenAI API
Development Framework
Development Resources
- AX630C Databrief
- Module LLM JSON API Documentation
- Module LLM AX630C API Docs
- Module LLM AX620E MSP/Sample
- Module LLM Linux Kernel 4.19.125-head
- AXERA LLM Example
- AXERA CV Example
- Module LLM Large Model Compilation Guide
Video
- Module LLM Product Introduction and Example Demonstration
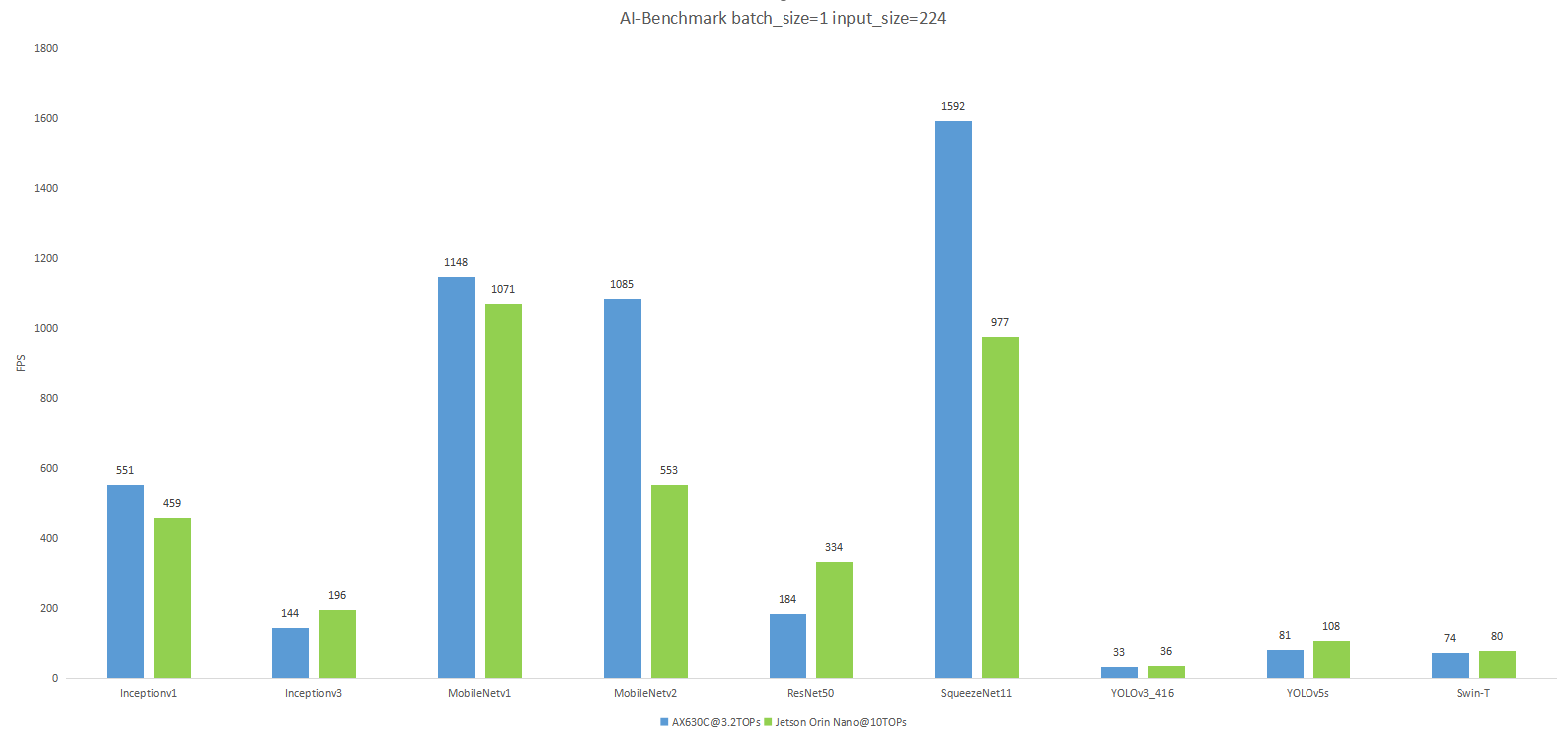
Product Comparison
AI Benchmark Comparison