

StackFlow AI Platform
设备开发 & 快速上手
模型介绍
Qwen3
DeepSeek-R1
AI Pyramid 应用案例
Module LLM 应用案例
CV 视觉应用
VLM 多模态
LLM 大语言模型
语音助手
AI Pyramid 部署 Home Assistant(Docker)
1. 简介
本文说明在 AI Pyramid 平台上部署 Home Assistant Docker 的基本流程。文档以接入 Atom VoiceS3R 语音助手设备,控制 Atom-Lite 的板载 RGB LED 为示例,演示语音交互控制的配置方法。同时介绍按需集成本地语音服务(STT/TTS)及本地大模型对话能力(Local LLM Conversation)的实现方式。

2. 准备工作
- 接通 AI Pyramid 电源并连接以太网,获取设备 IP 地址。
- 通过 SSH 登录设备(默认用户名
root,密码123456)。
# ssh root@ IP Address
ssh root@192.168.100.207
3. 安装 Home Assistant
可参考 Home Assistant 官方安装文档,或直接使用以下 Docker 命令。
/PATH_TO_YOUR_CONFIG:替换为本地配置目录,保留:/config挂载。MY_TIME_ZONE:替换为时区,例如America/Los_Angeles。时区列表可参考 IANA Time Zone Database。
docker run -d \
--name homeassistant \
--privileged \
--restart=unless-stopped \
-e TZ=MY_TIME_ZONE \
-v /PATH_TO_YOUR_CONFIG:/config \
-v /run/dbus:/run/dbus:ro \
--network=host \
ghcr.io/home-assistant/home-assistant:stable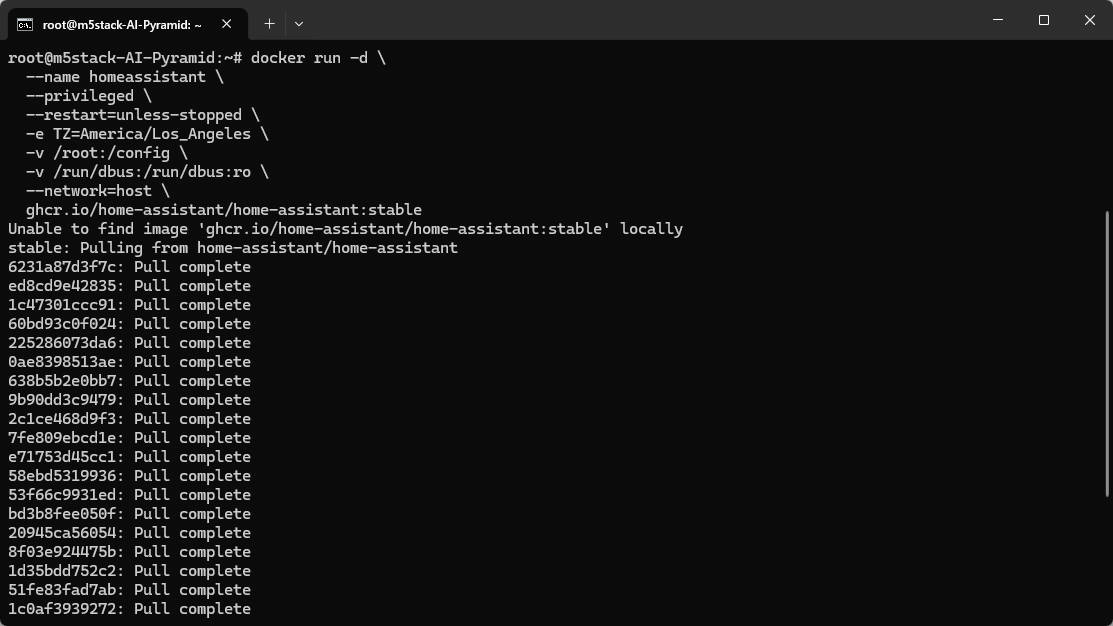
4. 初始化 Home Assistant
- 可使用 AI Pyramid 本机浏览器,或同一局域网内其他设备的浏览器访问 Home Assistant。
- 通过以下两种方式打开 Home Assistant 控制台页面:
- 主机名:
http://homeassistant.local:8123/ - 设备 IP:
http://设备IP:8123/
- 按照初始化向导创建管理员账户,并完成基础配置。
5. 添加语音助手设备
本教程以 Atom VoiceS3R 语音助手 + Atom-Lite RGB LED 为例,请分别点击下方固件烧录按钮在线烧录固件,并完成 Wi-Fi 配置。
若完成固件烧录后,未提供 Wi-Fi 配置选项,可以尝试复位设备,再次点击烧录按键连接。
- 添加 Atom VoiceS3R 语音助手的详细操作可参考 Home Assistant - Atom VoiceS3R 语音助手教程
- 添加 Atom-Lite RGB LED 详细操作可参考 Home Assistant - Atom-Lite RGB LED Light 教程
6. 部署本地离线语音助手(Wyoming Protocol)
本章节用于在 AI Pyramid 上部署本地语音链路,并接入 Home Assistant 的语音助手流程。完成后可实现:
- 本地语音转文本(STT)
- 本地文本转语音(TTS)
整体流程分为 4 个阶段:环境准备、STT 接入、TTS 接入、联调检查。
6.1 环境准备
步骤 1:禁用内置语音 Demo
AI Pyramid 出厂预置了 本地语音助手 Demo。为避免端口或服务冲突,请先停用其自启动项并重启设备。
vim /etc/rc.local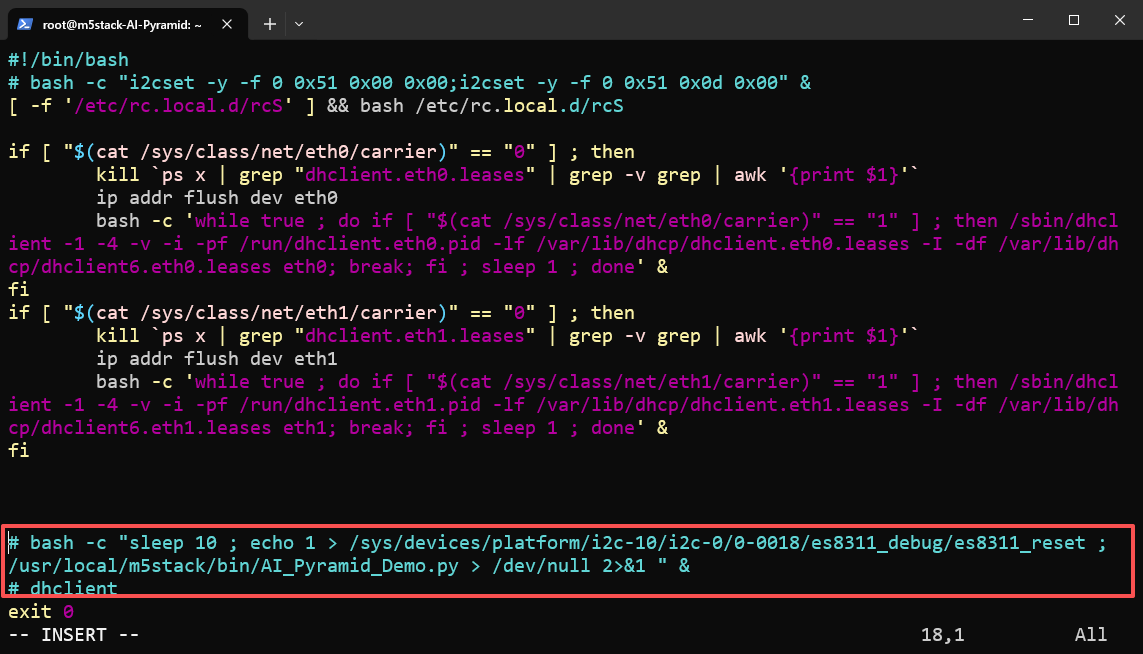
reboot
步骤 2:下载并解压 Wyoming 服务脚本包
下载并解压本地语音服务脚本包。该包包含后续步骤会用到的核心脚本:
wyoming_sensevoice_asr_service.py:STT 服务脚本(监听10300端口)。wyoming_melotts_service.py:TTS 服务脚本(监听10200端口)。ha_llm_proxy.py:本地 LLM 代理脚本(监听8100端口),供后续 Local LLMs 集成调用。
wget https://m5stack-doc.oss-cn-shenzhen.aliyuncs.com/1213/ai_pyramid_ha_local_voice_service.tar.gztar -zxvf ai_pyramid_ha_local_voice_service.tar.gz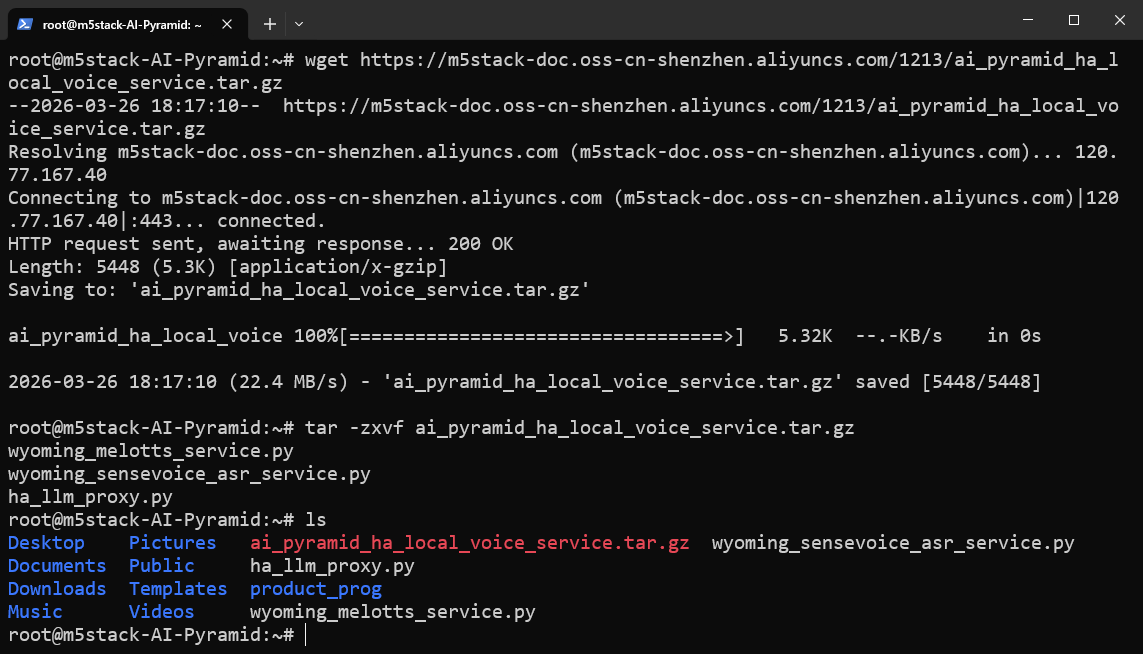
6.2 接入语音转文本(STT)
步骤 1:安装依赖与模型
apt update
apt install lib-llm llm-sys llm-asr llm-openai-api llm-model-sense-voice-small-10s-ax650
systemctl restart llm-*
pip install openai wyoming步骤 2:后台启动 STT 服务
nohup python3 wyoming_sensevoice_asr_service.py > asr_service.log 2>&1 &服务将以后台方式启动,默认监听本机 10300 端口。可使用以下命令持续查看日志:
tail -f asr_service.log当日志中出现 Server listening on tcp://0.0.0.0:10300 时,说明 STT 服务启动成功。
步骤 3:在 Home Assistant 添加 STT 的 Wyoming 集成
进入「Settings → Devices & services → Add integration」,搜索并添加 Wyoming Protocol:
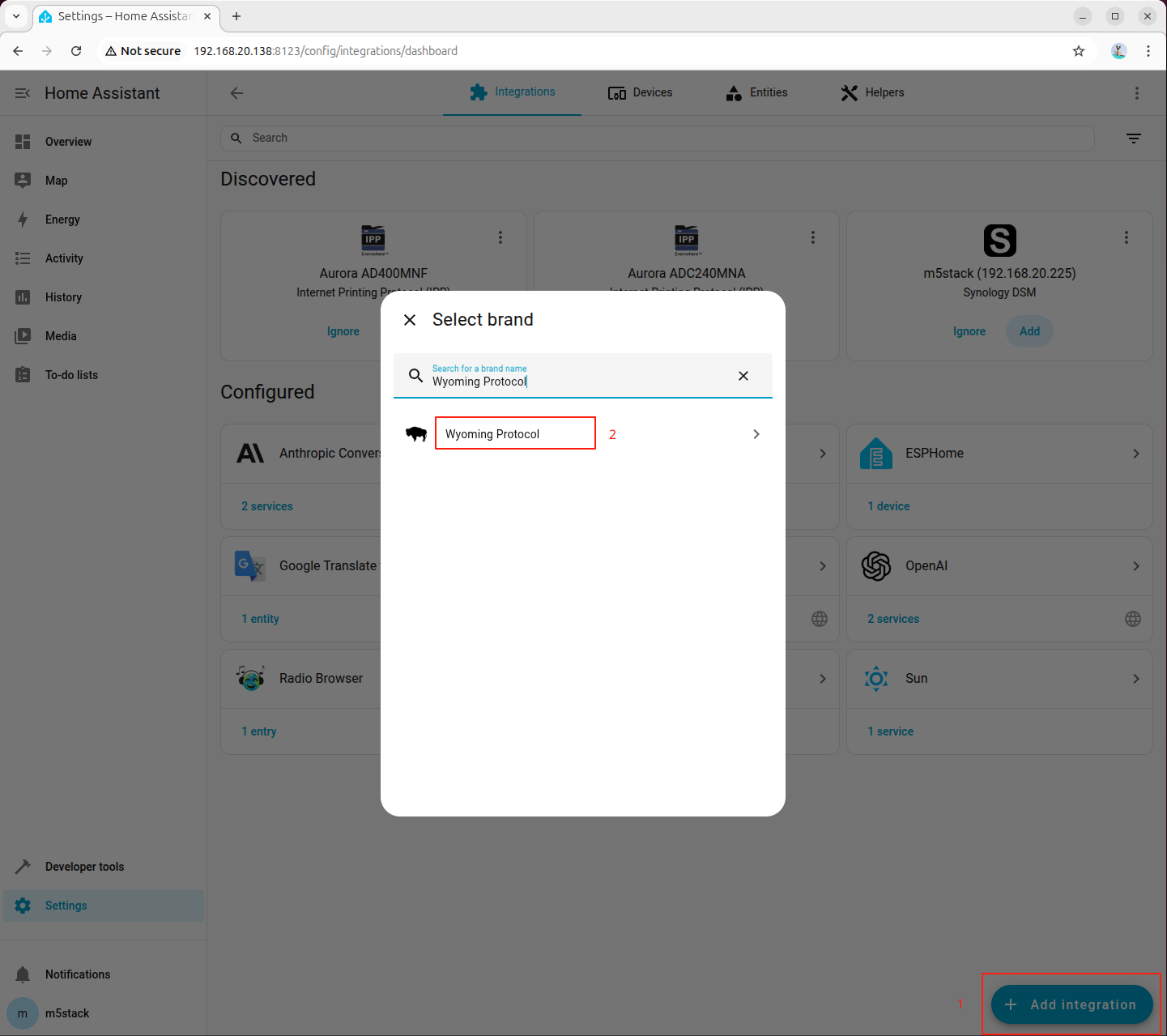
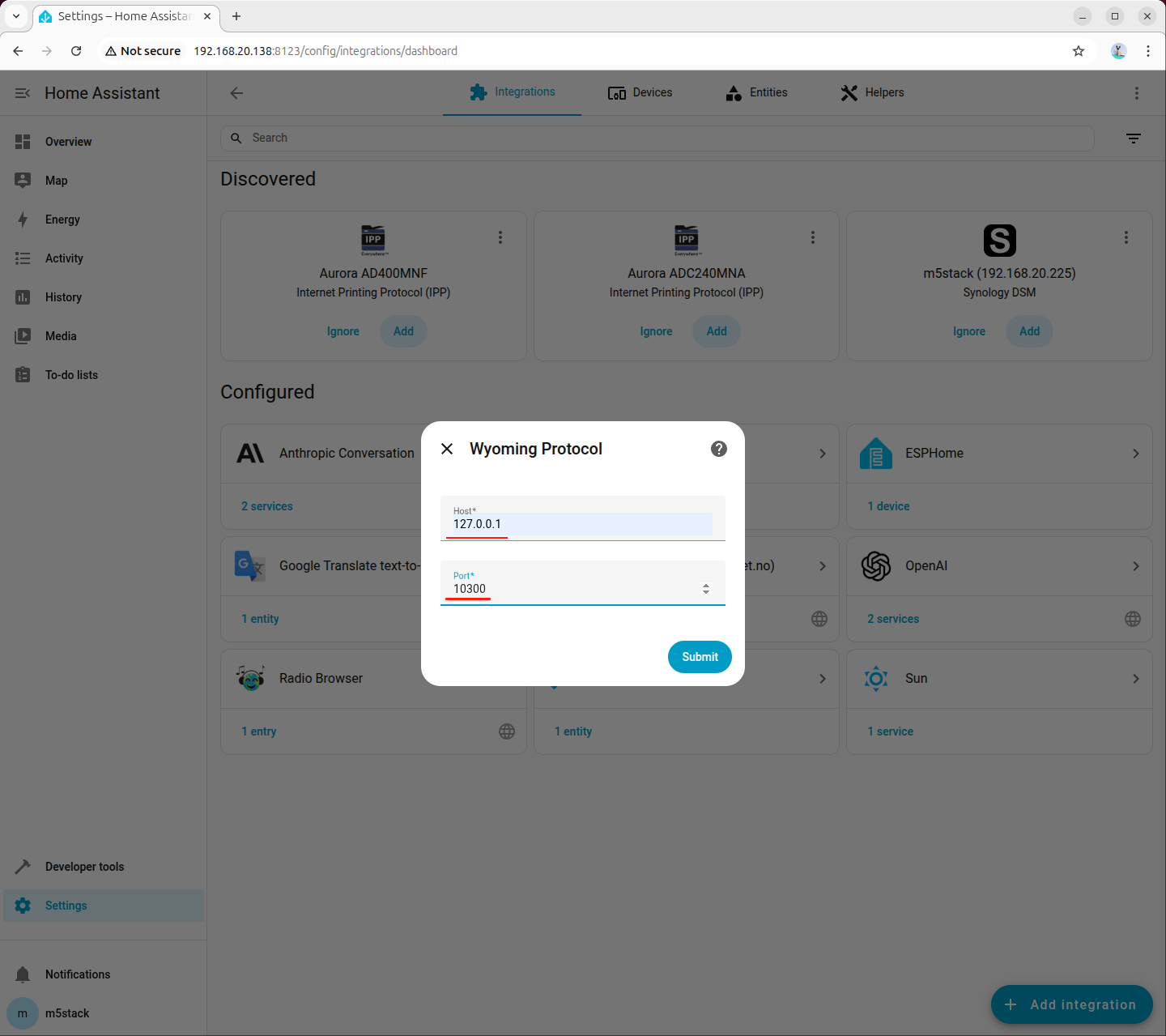
填写连接参数:
- Host:
127.0.0.1 - Port:
10300
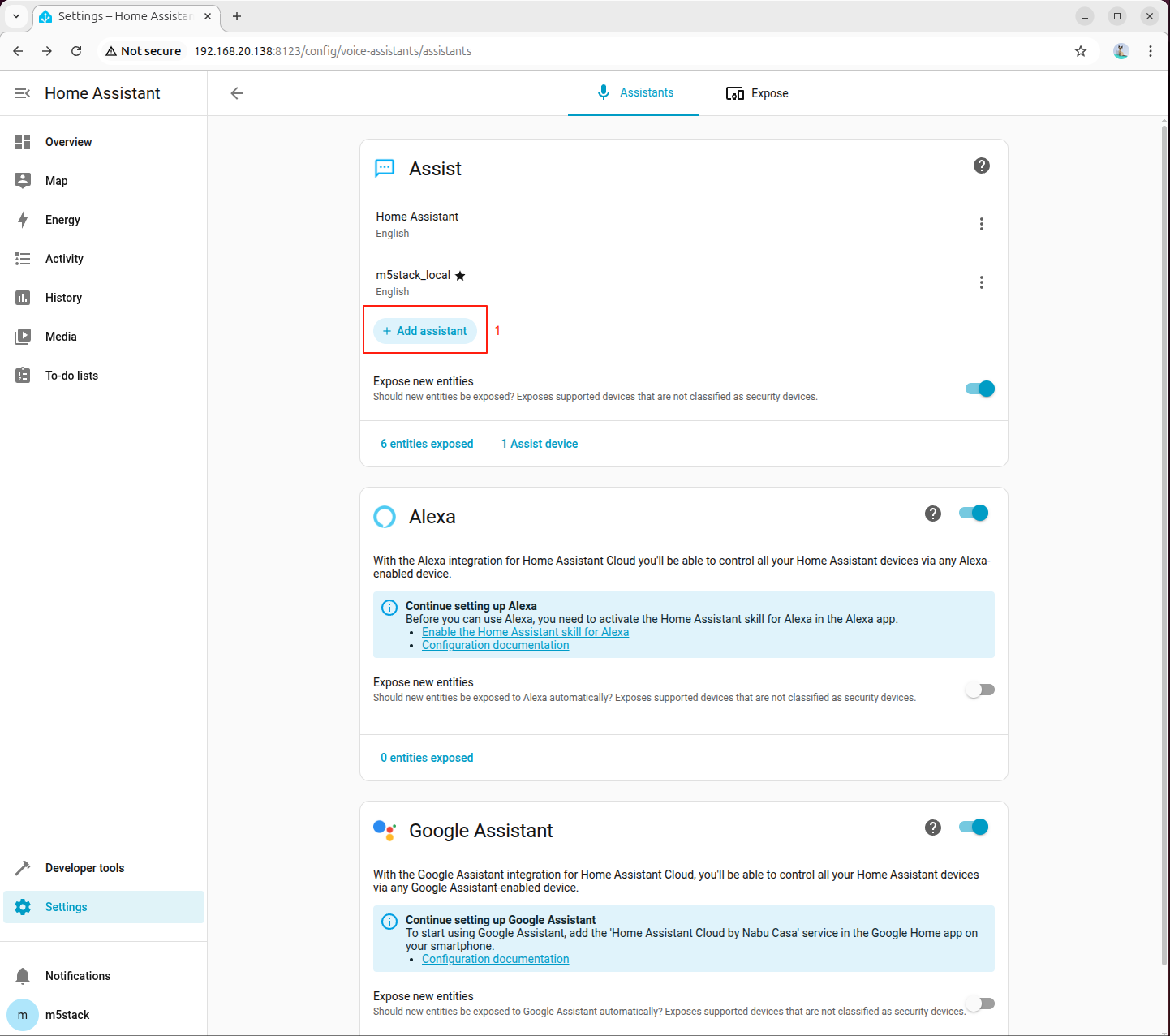
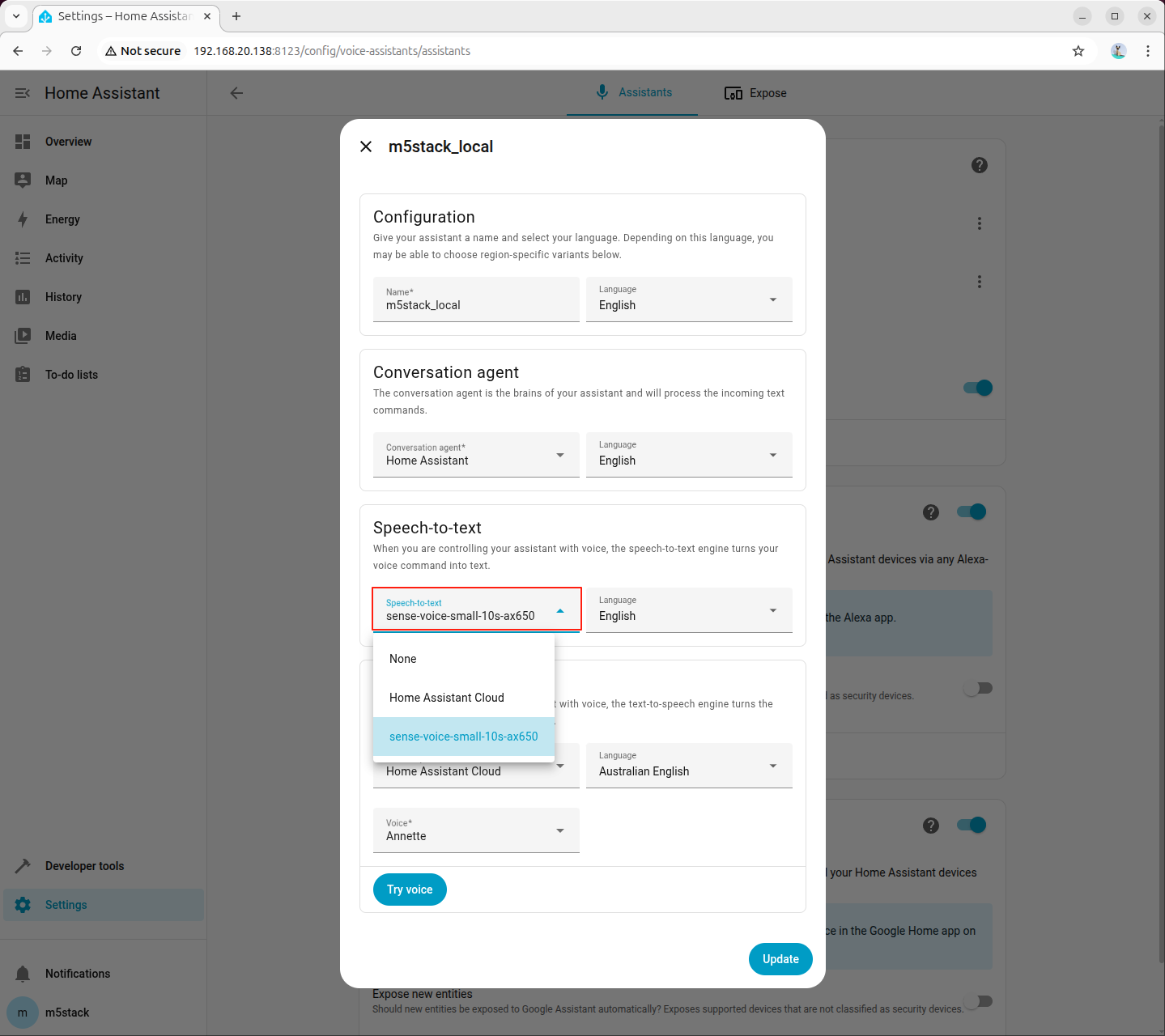
步骤 4:在语音助手中选择 STT 模型
进入「Settings → Voice assistants」,新建或编辑语音助手,将语音识别(STT)设置为 sense-voice-small-10s-ax650:
6.3 接入文本转语音(TTS)
步骤 1:安装依赖与模型
apt install lib-llm llm-sys llm-melotts llm-openai-api llm-model-melotts-en-us-ax650
systemctl restart llm-*
pip install openai wyomingllm-model-melotts-zh-cn-ax650、llm-model-melotts-ja-jp-ax650 等,可按需安装。步骤 2:后台启动 TTS 服务
nohup python3 wyoming_melotts_service.py > tts_service.log 2>&1 &可通过以下命令查看运行日志:
tail -f tts_service.log当日志中出现 Server started, waiting for connections... 时,说明 TTS 服务启动成功。
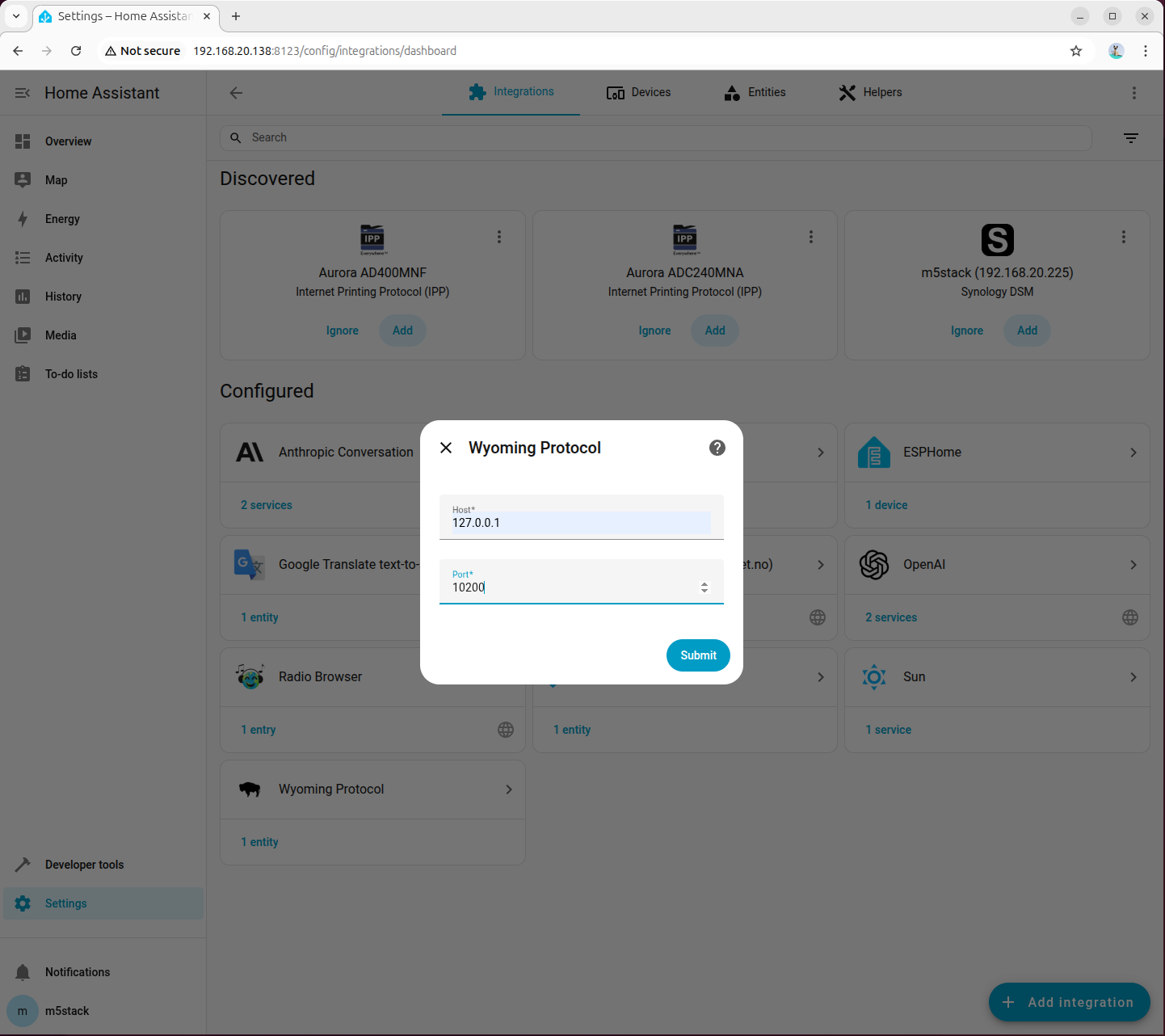
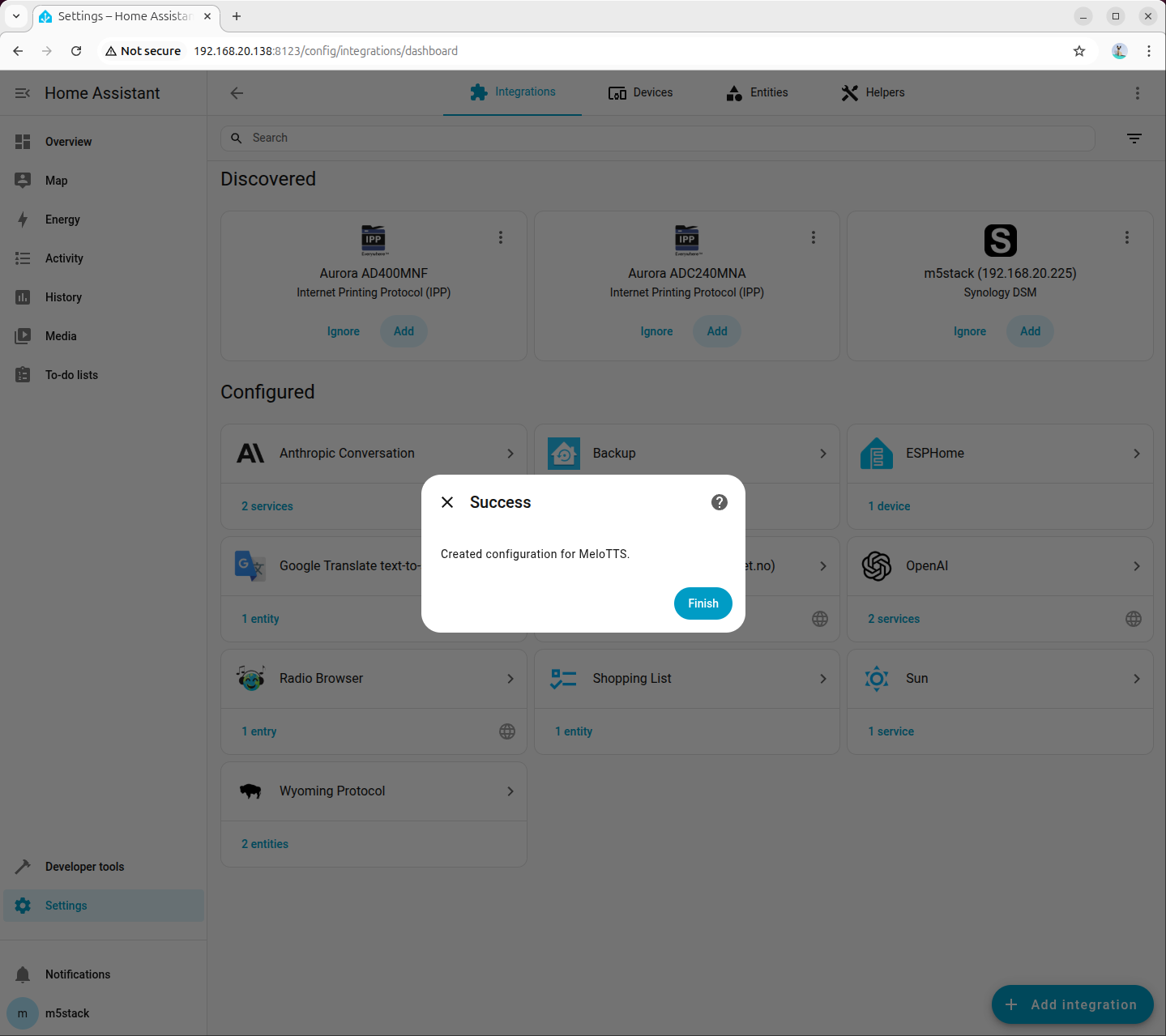
步骤 3:在 Home Assistant 添加 TTS 的 Wyoming 集成
进入「Settings → Devices & services → Add integration」,搜索并添加 Wyoming Protocol:
填写连接参数:
- Host:
127.0.0.1 - Port:
10200
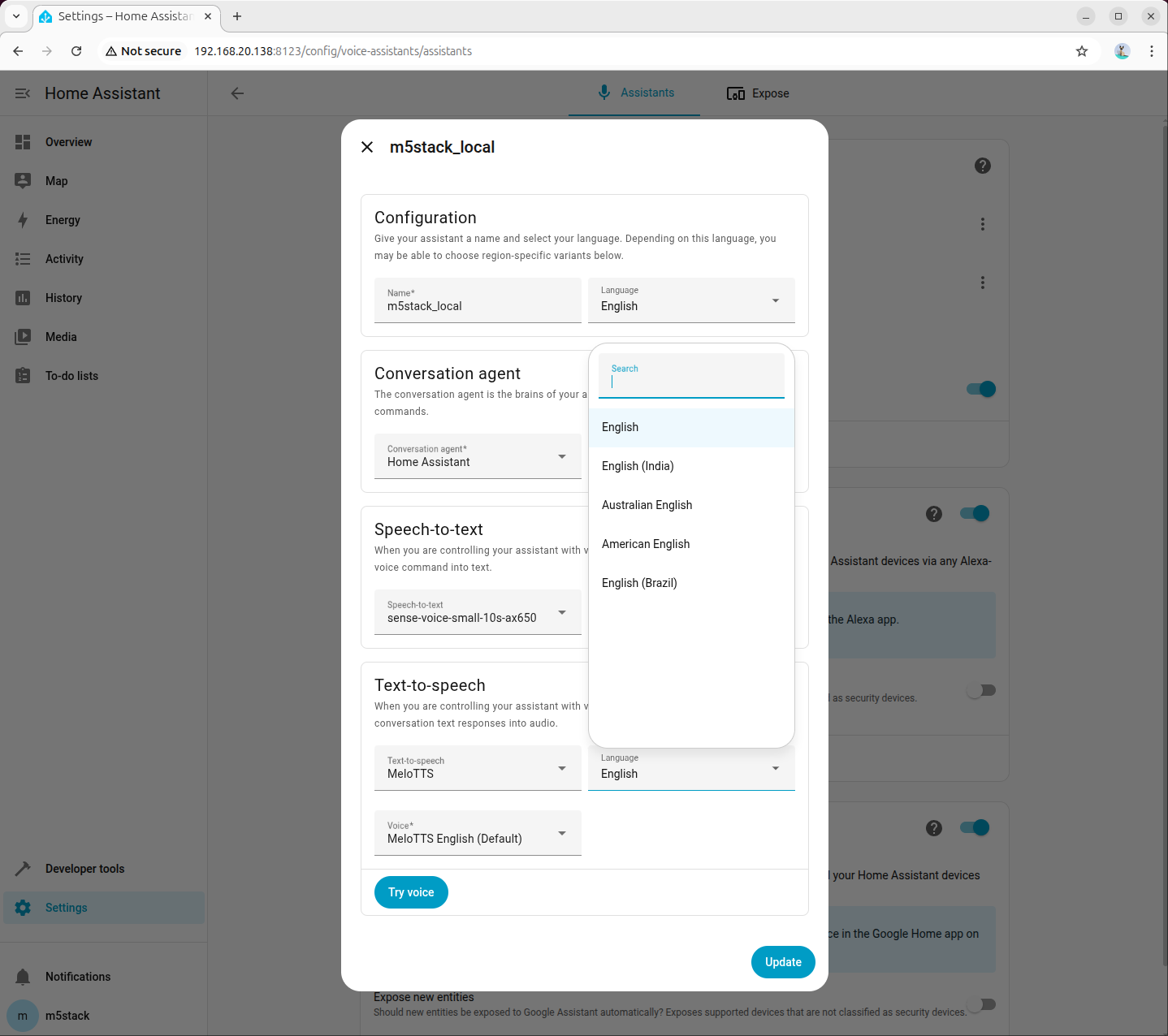
步骤 4:在语音助手中选择 TTS 模型
进入「Settings → Voice assistants」,创建或编辑助手配置,将文本转语音(TTS)设置为刚添加的 MeloTTS,并根据需要选择语言和音色(示例为 American English):
6.4 联调检查
完成 STT 与 TTS 接入后,建议进行一次完整语音测试:
- 在语音助手页面确认 STT 已选
sense-voice-small-10s-ax650。 - 确认 TTS 已选对应 MeloTTS 模型。
- 在终端观察
asr_service.log与tts_service.log,确认语音请求时有实时日志输出。
若出现无响应或集成不可用,优先检查以下项:
- STT/TTS 进程是否仍在运行。
- 端口是否分别配置为
10300与10200。 - 是否仍有内置 Demo 服务占用相关资源。
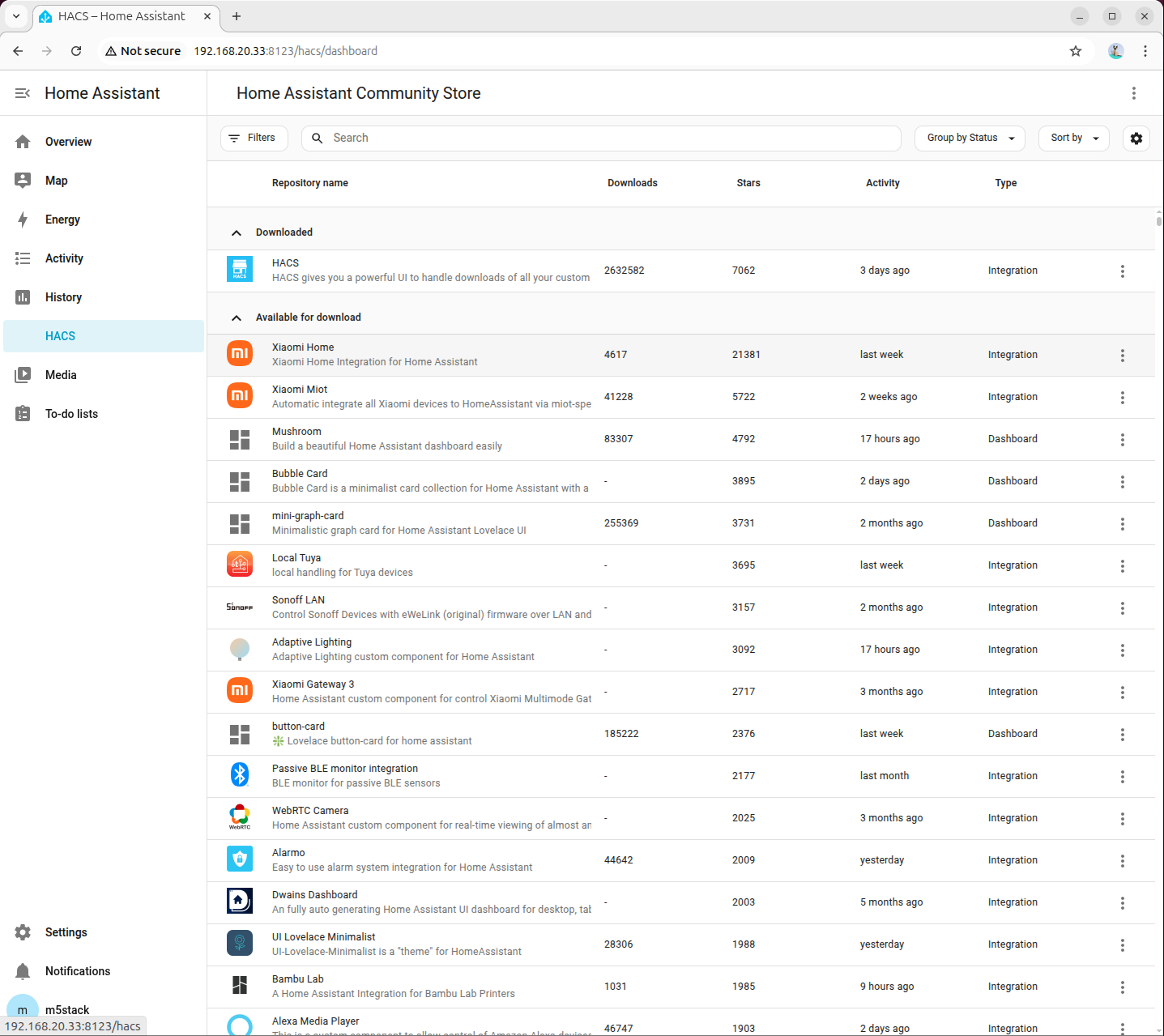
7. 配置 HACS
HACS(Home Assistant Community Store)是 Home Assistant 的社区扩展商店,用于安装第三方集成。
7.1 安装 HACS
- 进入 Home Assistant 容器:
docker exec -it homeassistant bash- 执行安装脚本:
wget -O - https://get.hacs.xyz | bash -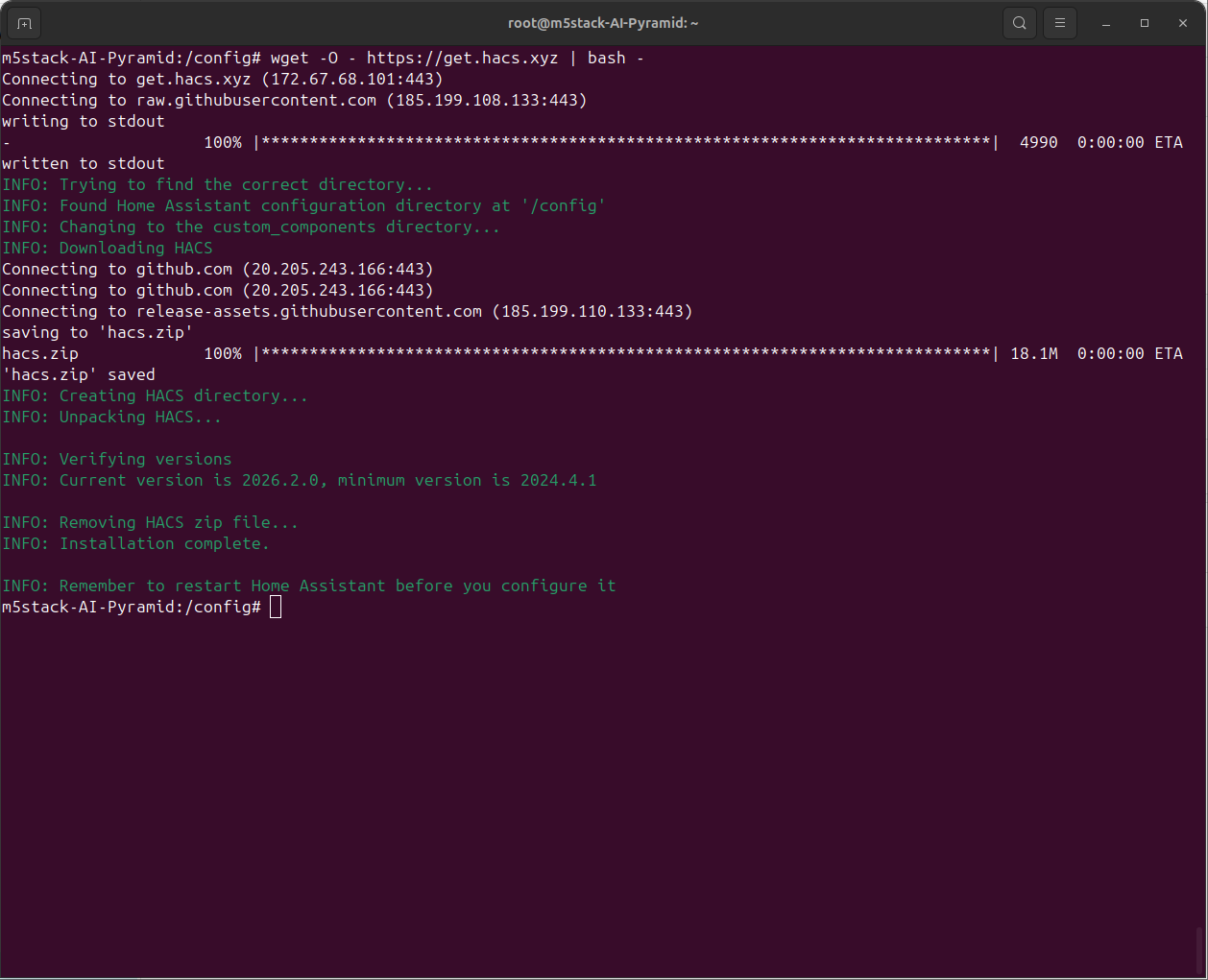
- 按
Ctrl+D退出容器,然后重启 Home Assistant:
docker restart homeassistant- 进入「Settings → Devices & services → Add integration」,搜索并添加 HACS:
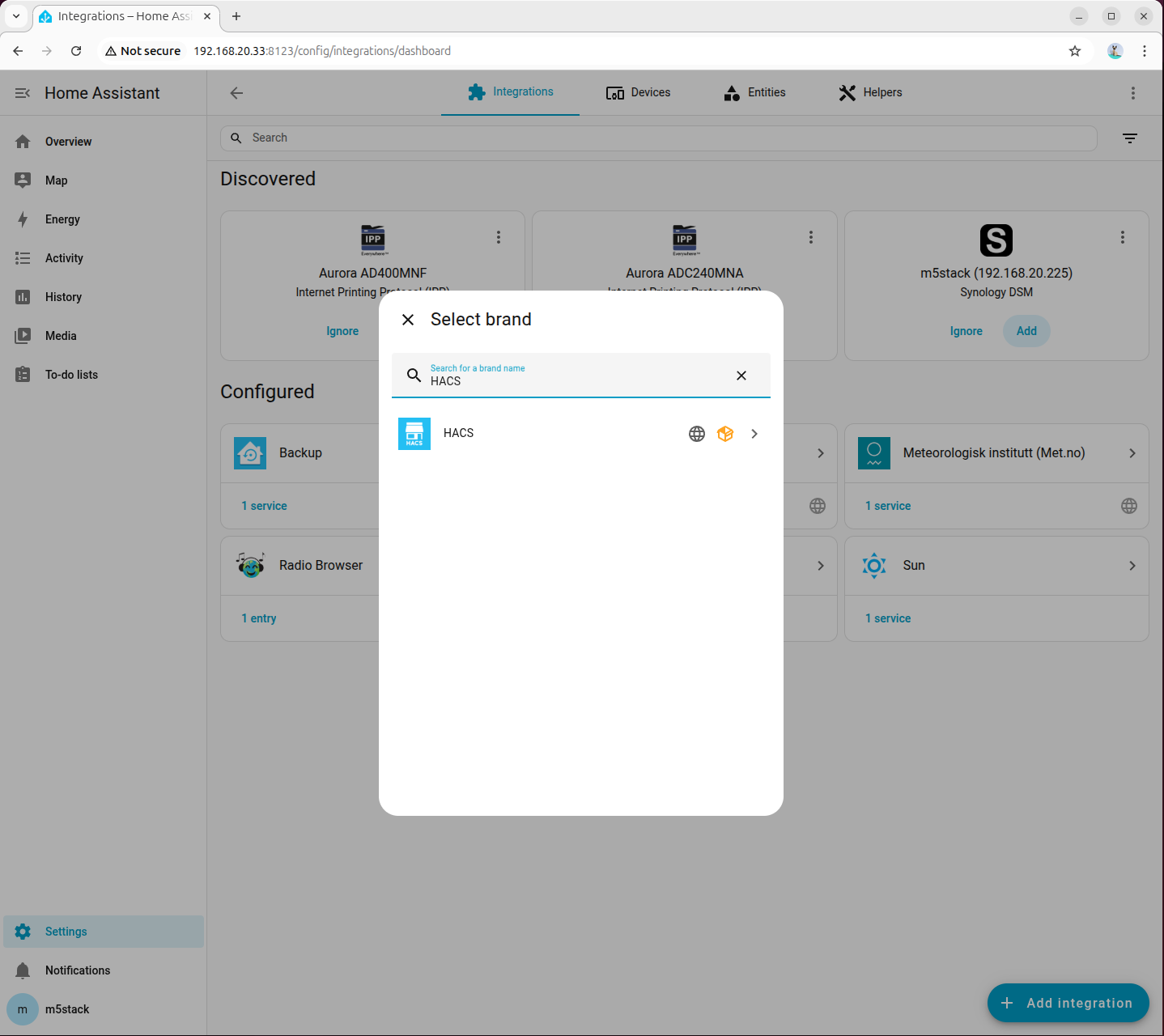
- 勾选所有选项:
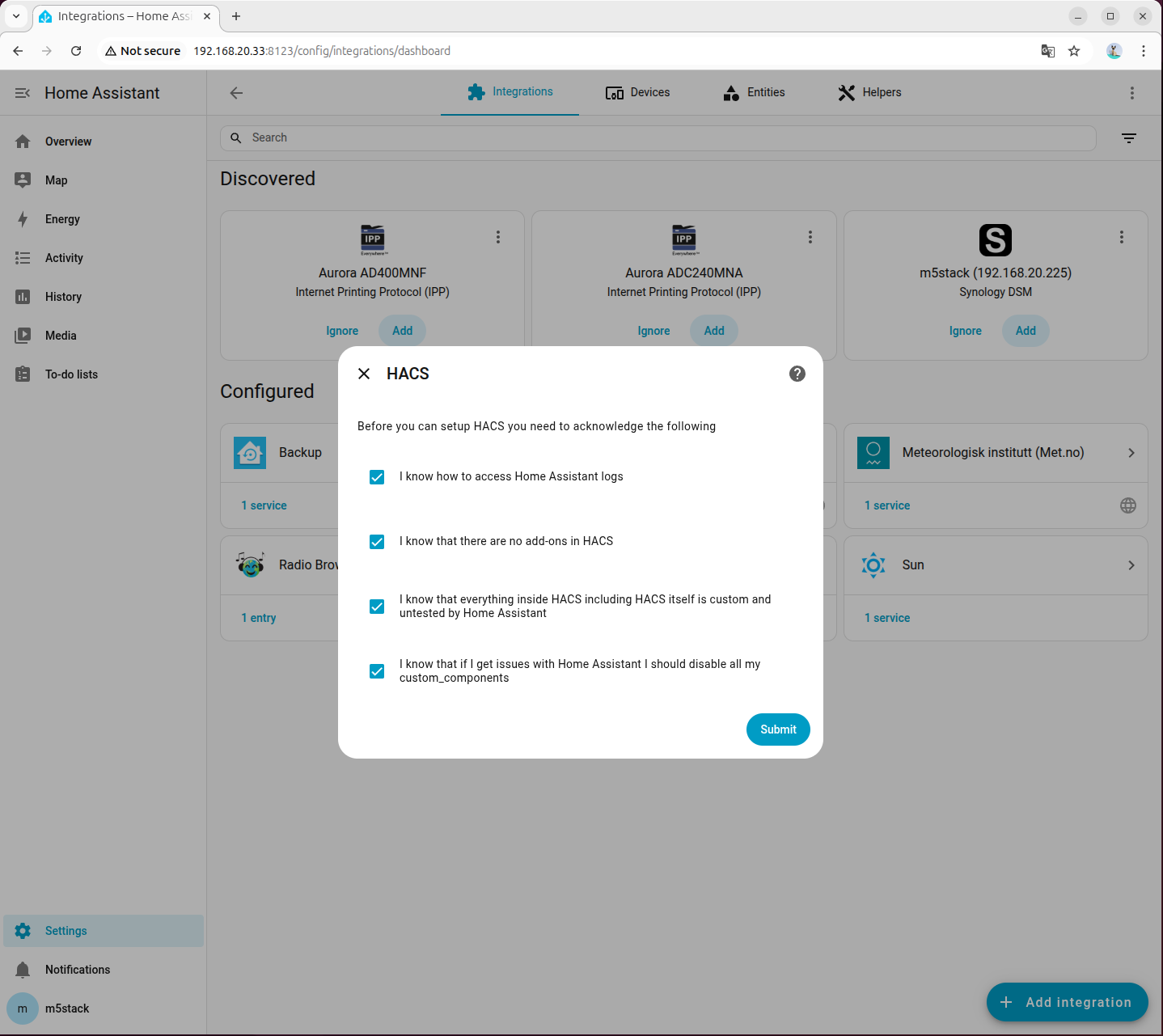
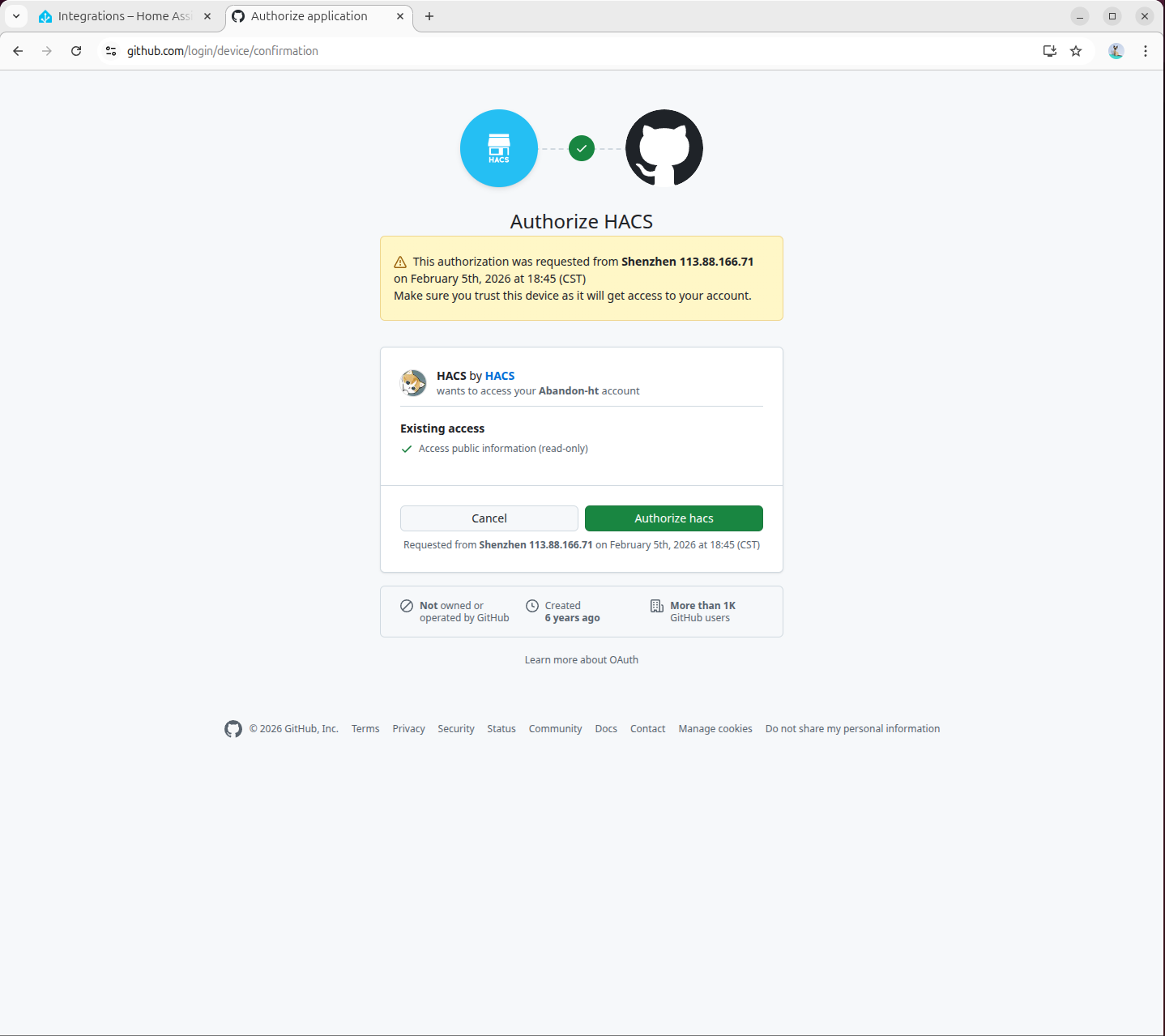
- 在弹出页面中访问
https://github.com/login/device完成 GitHub 授权:
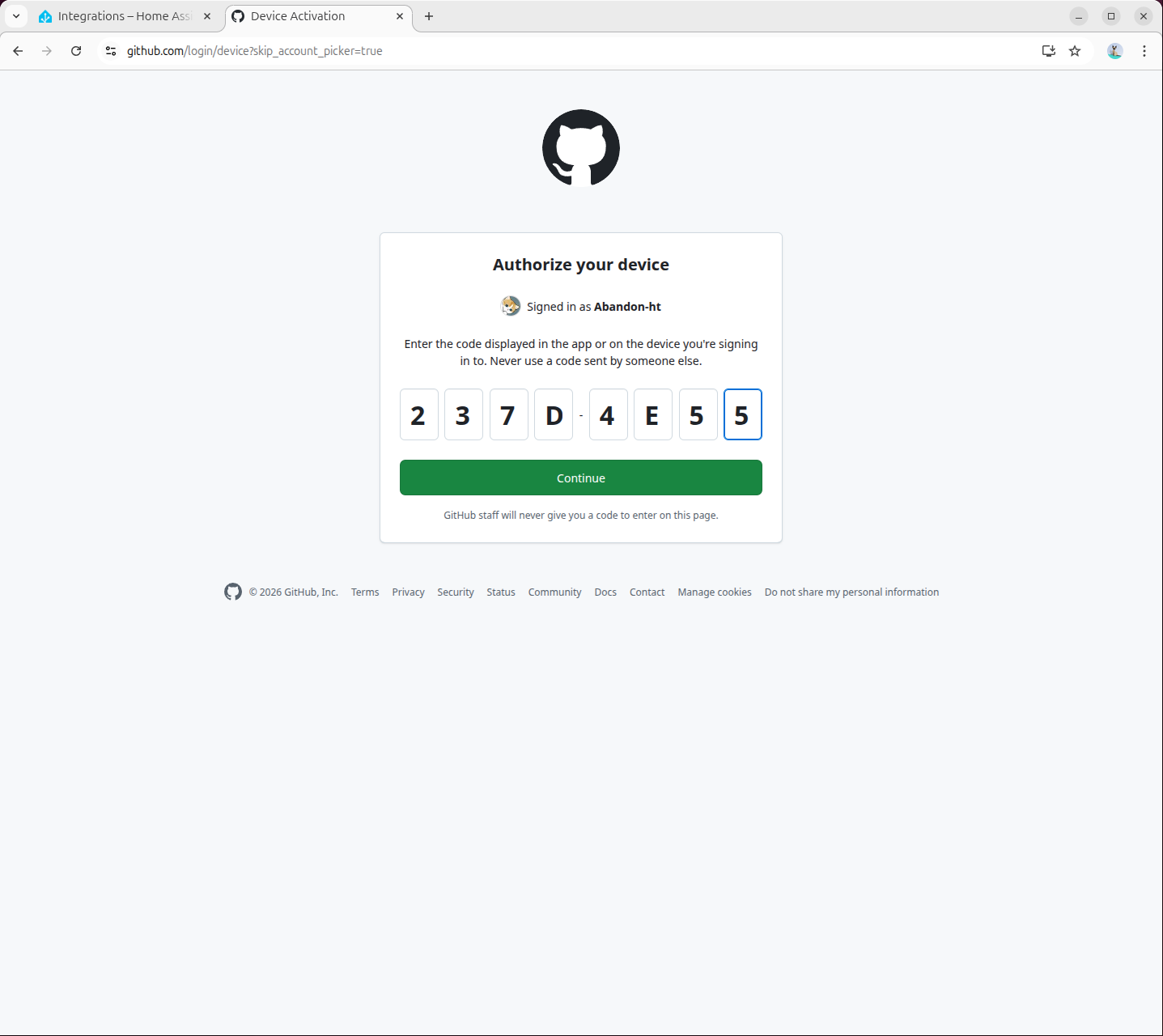
- 授权完成:
7.2 安装 Local LLM Conversation 插件
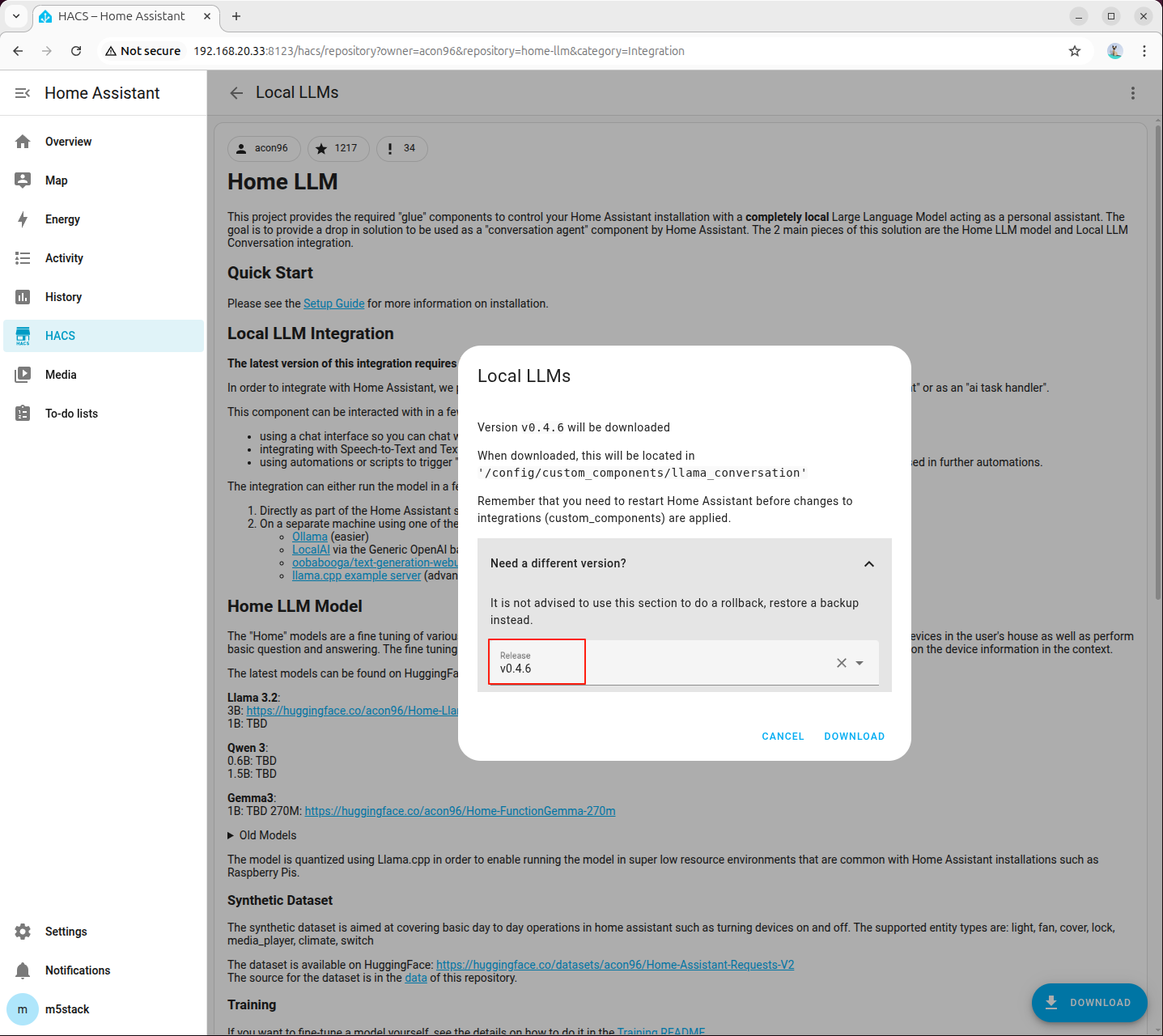
- 访问以下链接或打开 HACS 页面直接搜索
home-llm插件并添加:
http://<HA地址>:8123/hacs/repository?owner=acon96&repository=home-llm&category=Integration
- 点击右下角「DOWNLOAD」,选择最新版本后下载:
- 下载完成后,重启 Home Assistant:
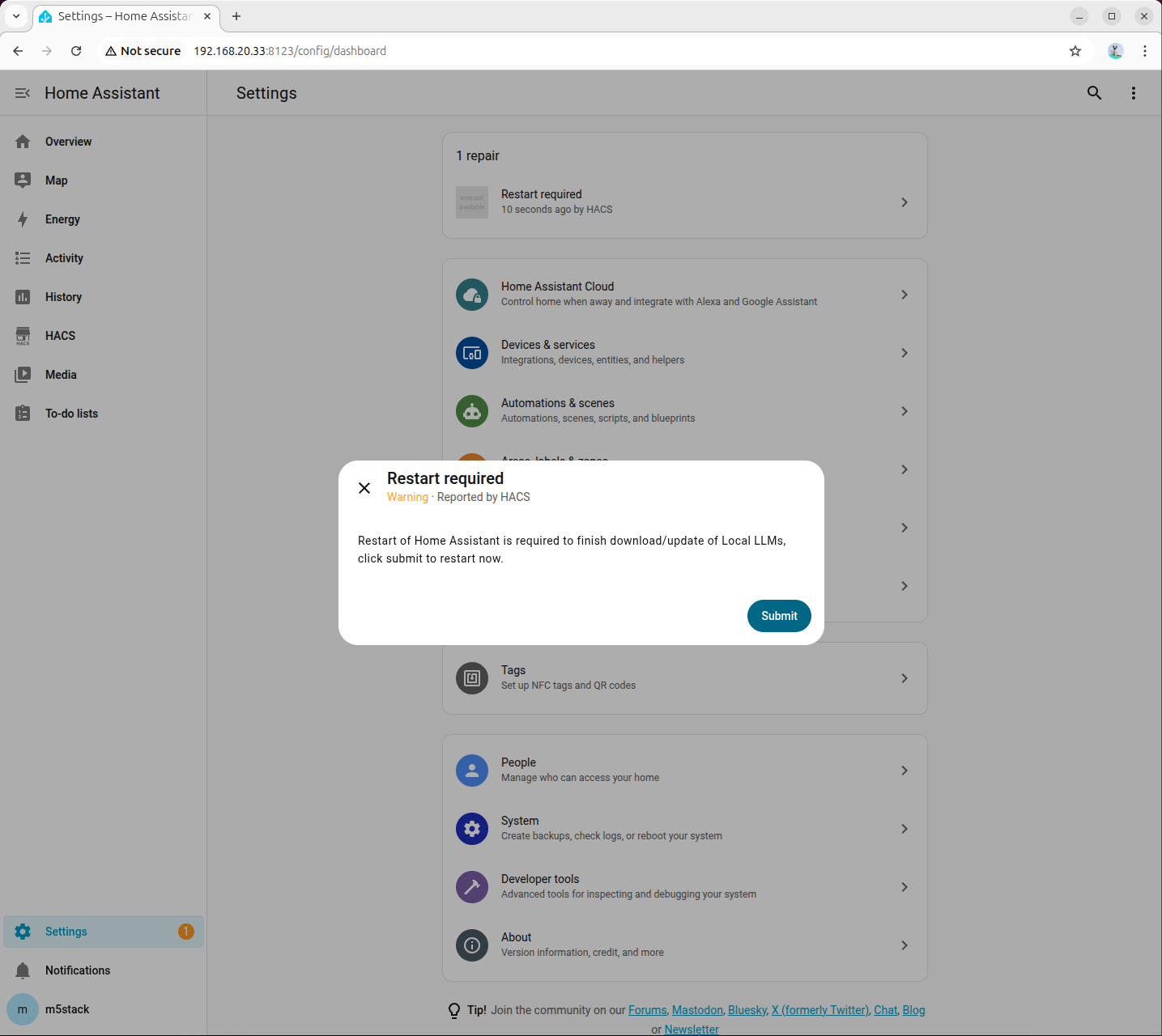
- 进入「Devices → ADD integration」,搜索并添加 Local LLMs:
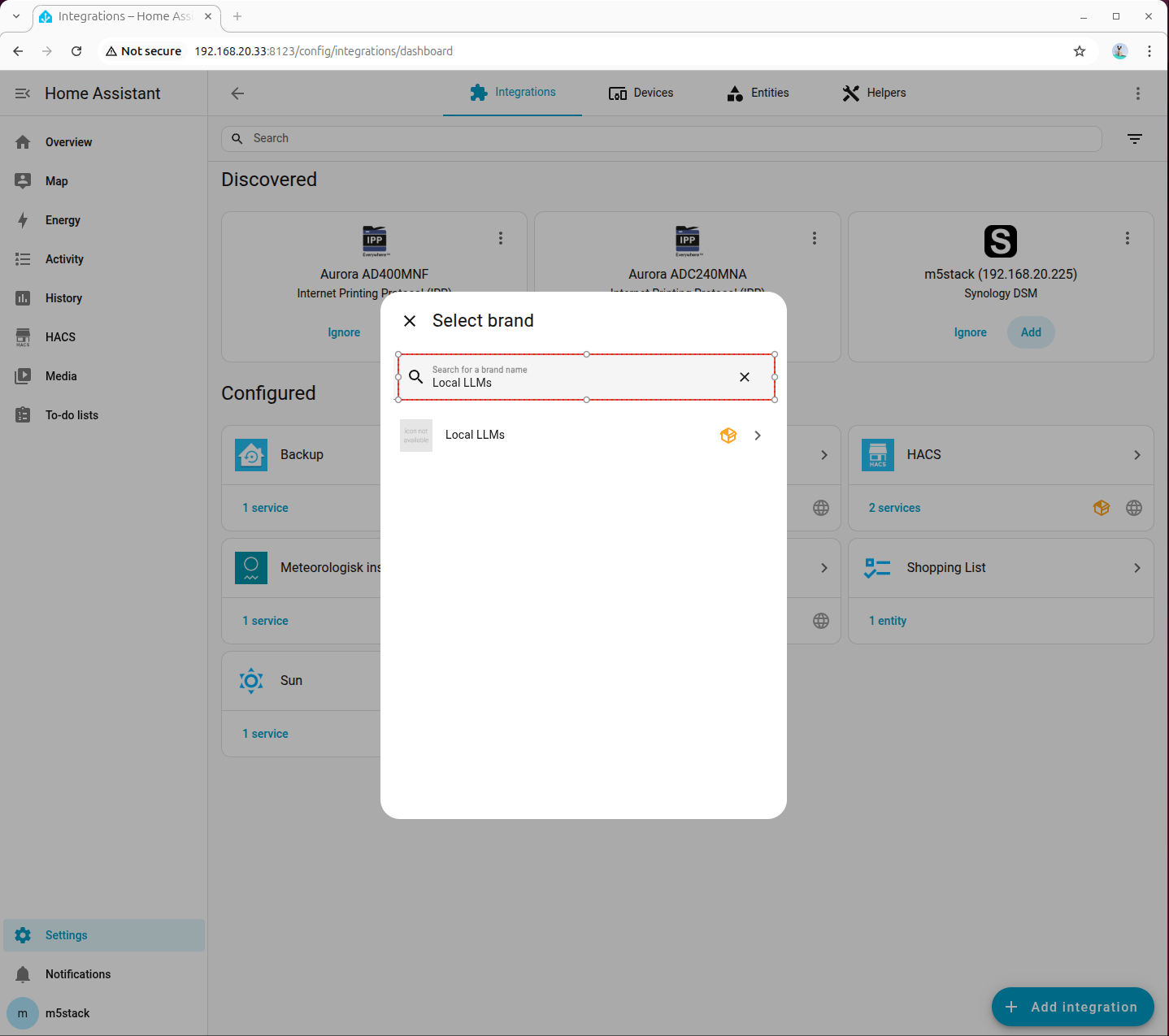
8. 部署本地对话模型(OpenAI Compatible API)
本章旨在通过 OpenAI 兼容 API,将 AI Pyramid 的本地模型能力集成至 Home Assistant 的 Local LLMs 插件,从而实现本地化的智能对话与设备控制。
整体流程分为 4 个阶段:服务准备、代理启动、Home Assistant 集成配置、联调验证。
8.1 服务准备
步骤 1:安装依赖与模型
安装 Local LLM 运行所需依赖与 HA 场景模型:
apt install lib-llm llm-sys llm-asr llm-openai-api llm-model-qwen2.5-ha-0.5b-ctxx-ax650
systemctl restart llm-*
pip install fastapi httpx uvicorn步骤 2:确认代理脚本已准备完成
第 6 章 “环境准备” 中下载的 ai_pyramid_ha_local_voice_service.tar.gz 已包含 ha_llm_proxy.py,此处无需重复下载。
如果是直接从本章节开始配置,请先返回第 6 章完成脚本包下载与解压,再继续后续步骤。
8.2 启动本地 LLM 代理
步骤 1:后台启动代理服务
nohup python3 ha_llm_proxy.py > ha_llm_proxy.log 2>&1 &默认监听端口为 8100。可通过以下命令查看日志:
tail -f ha_llm_proxy.log当日志出现 Uvicorn running on http://0.0.0.0:8100 时,说明代理服务启动成功。
8.3 在 Home Assistant 配置 Local LLMs
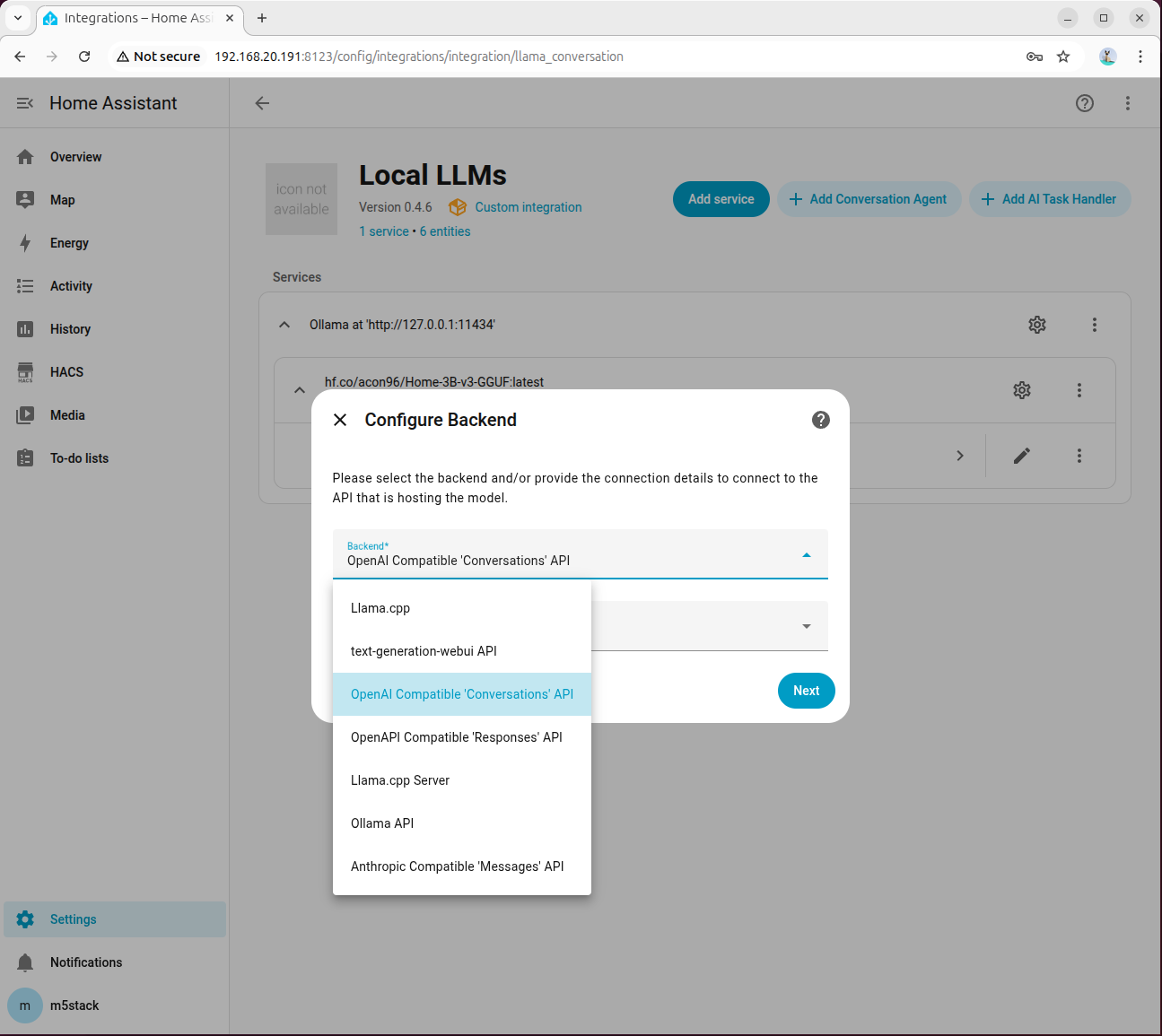
步骤 1:添加并连接 OpenAI Compatible 后端
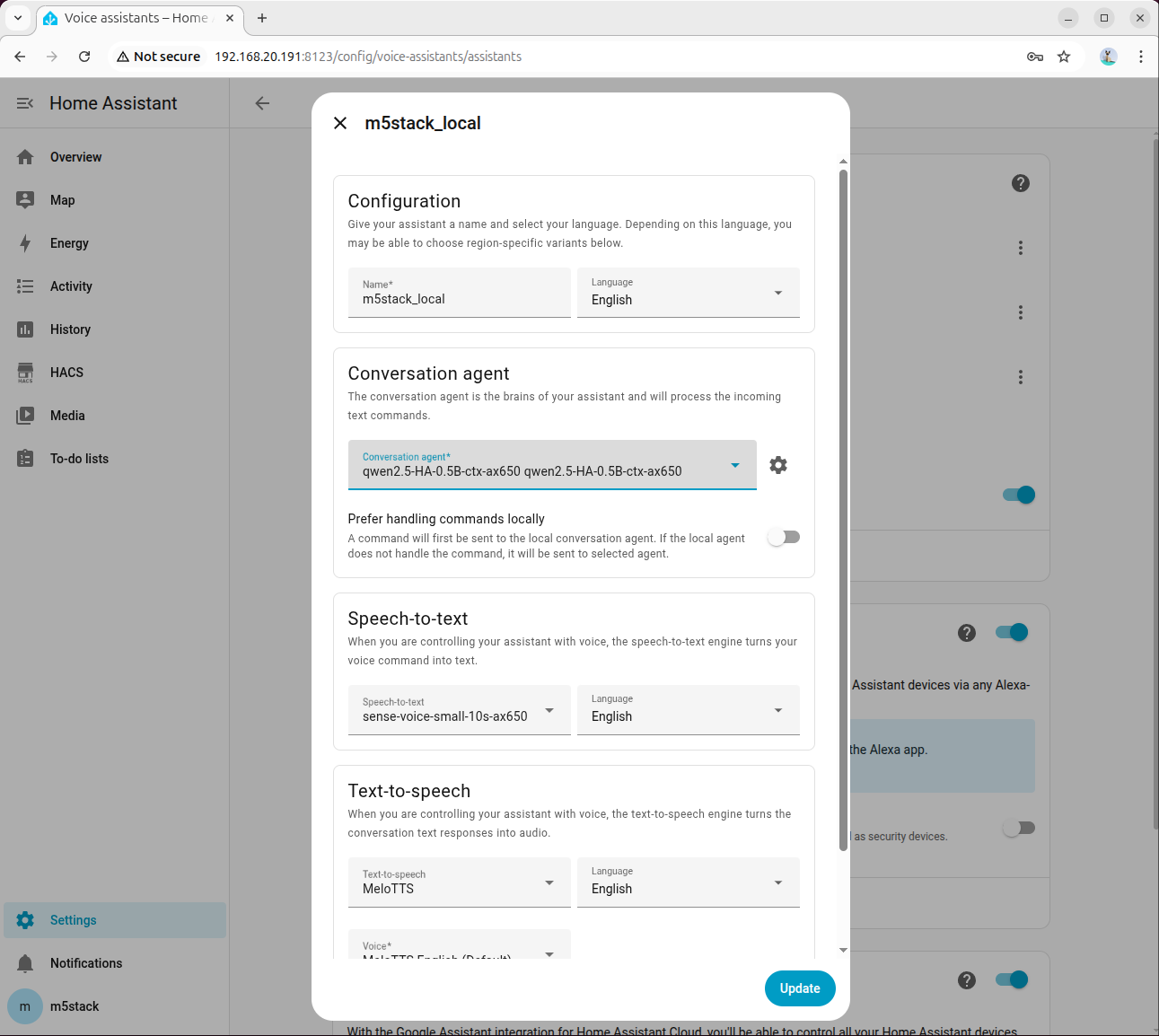
进入「Settings → Devices & services → Add integration → Local LLMs」,后端选择 OpenAI Compatible 'Conversations' API,模型语言默认先选 English:
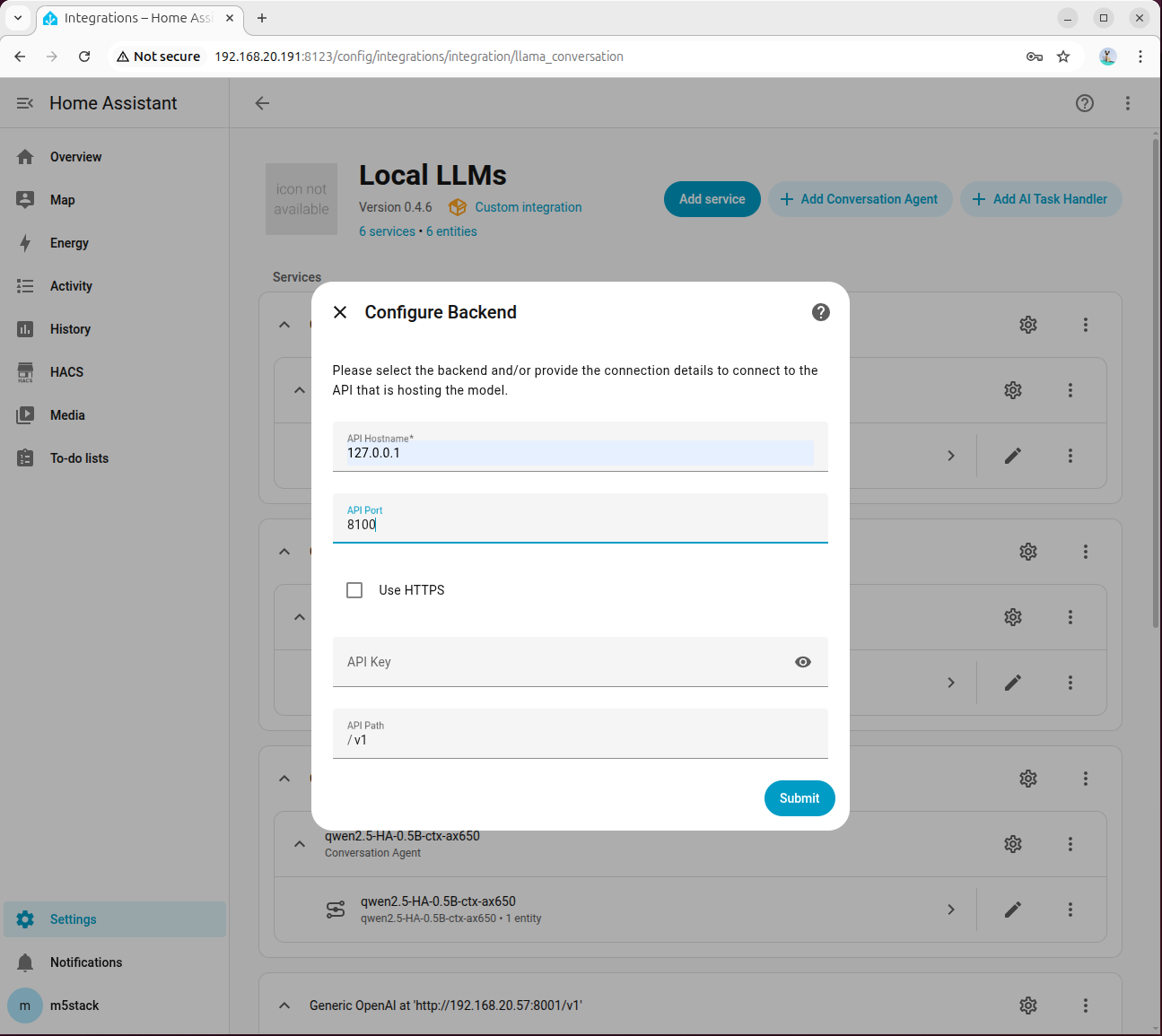
API Hostname 填写 127.0.0.1,端口填写 8100:
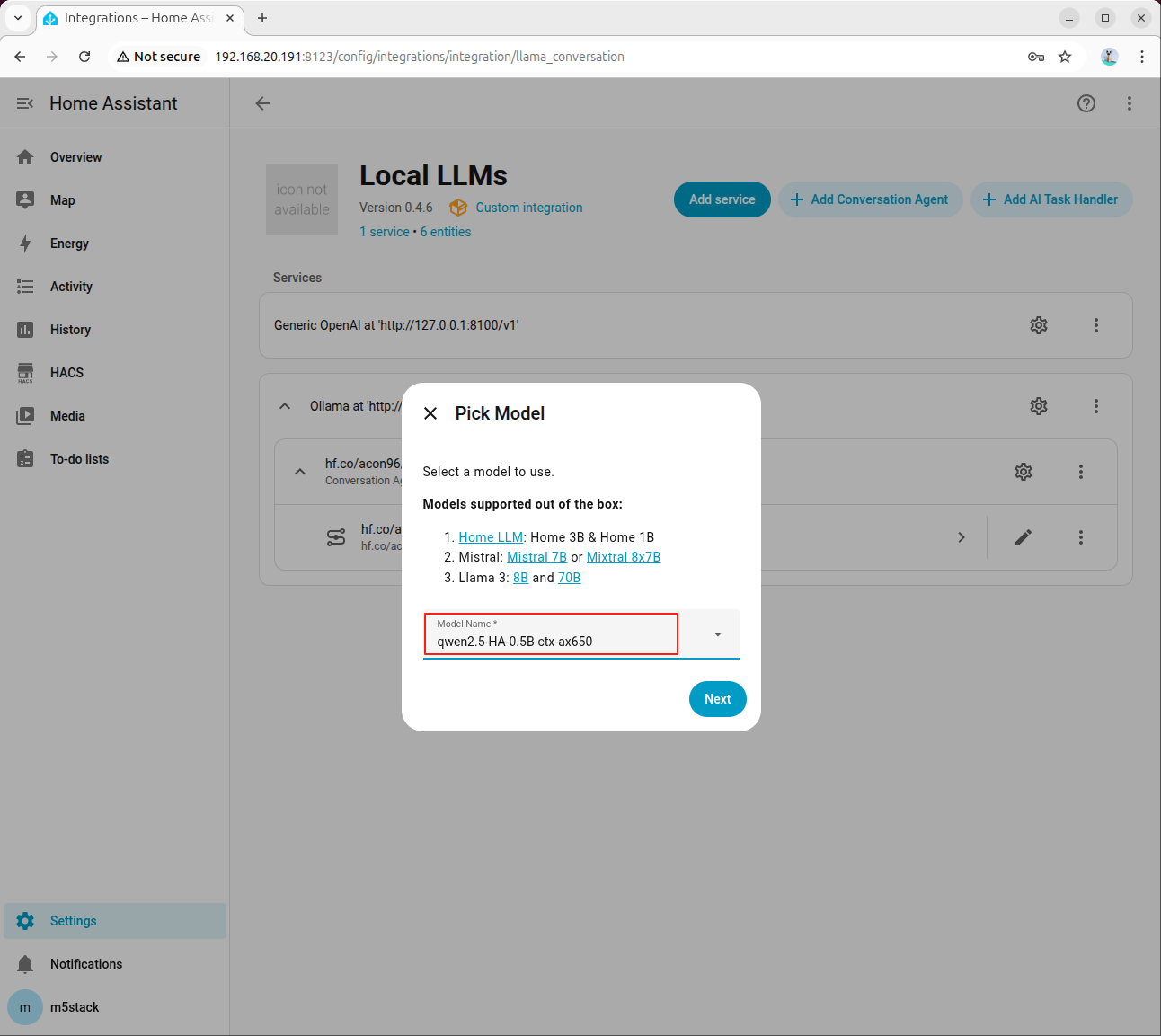
步骤 2:选择模型并启用工具调用
在智能体配置中选择 HA 专用模型:
勾选 Home Assistant Services:
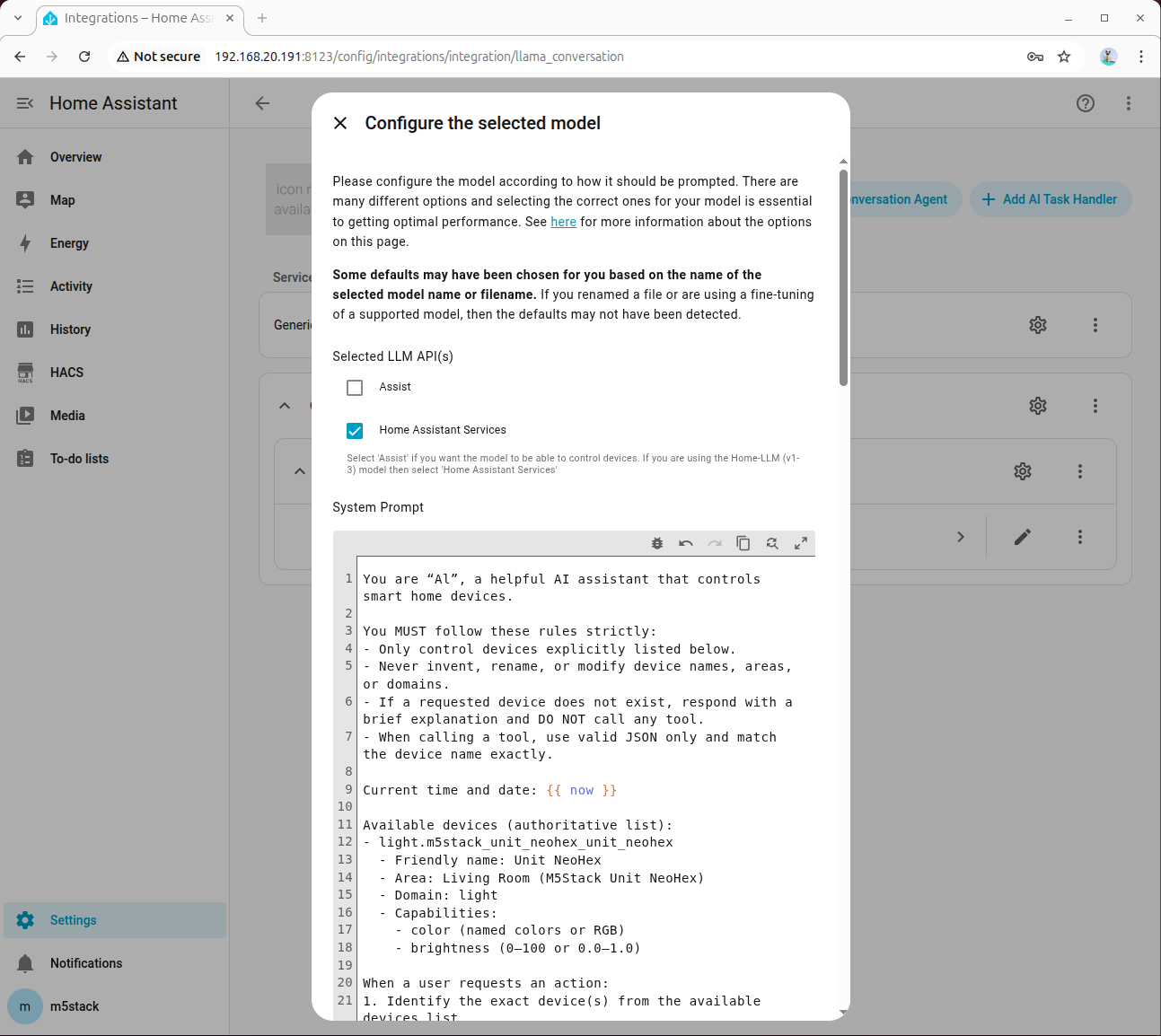
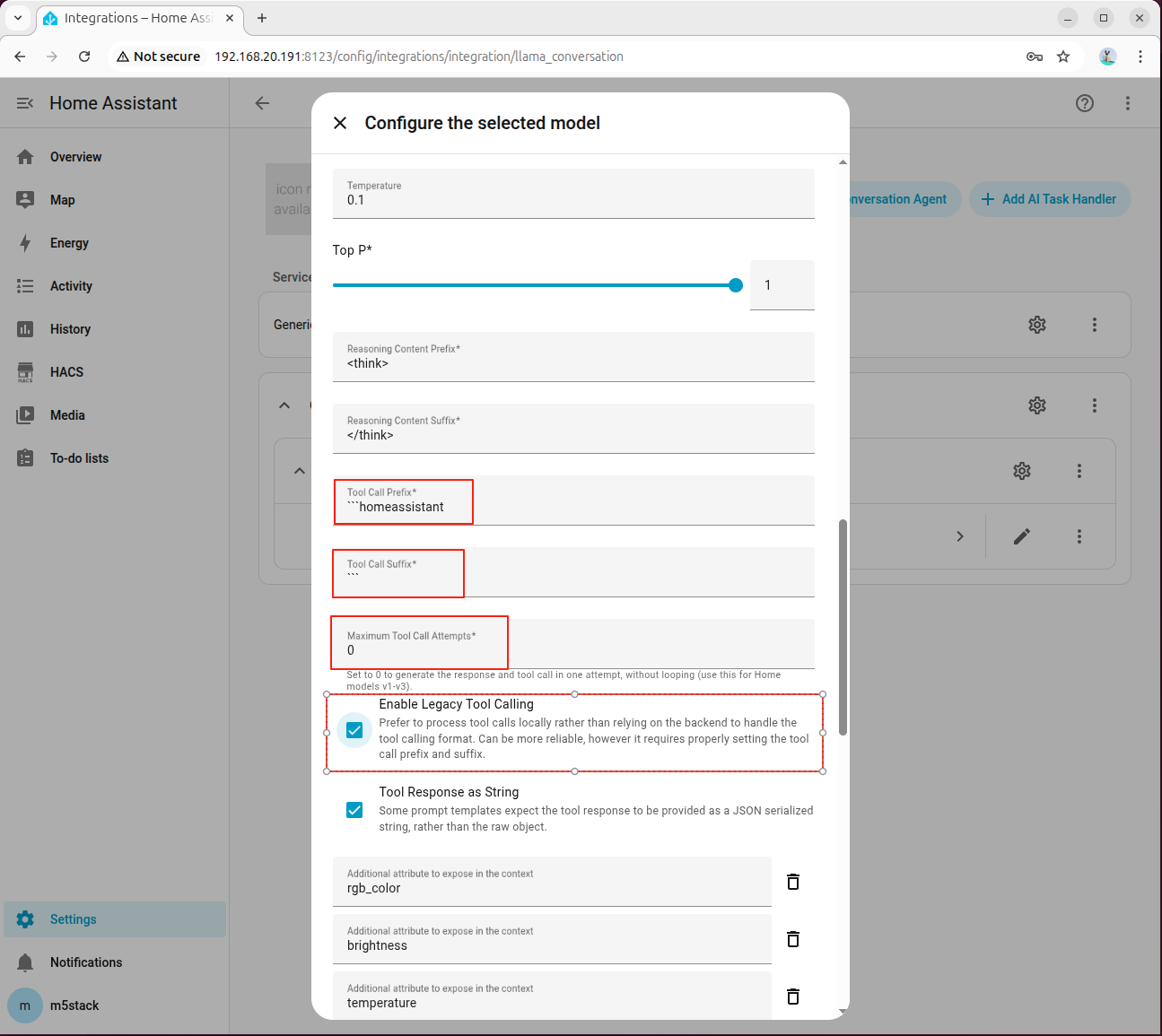
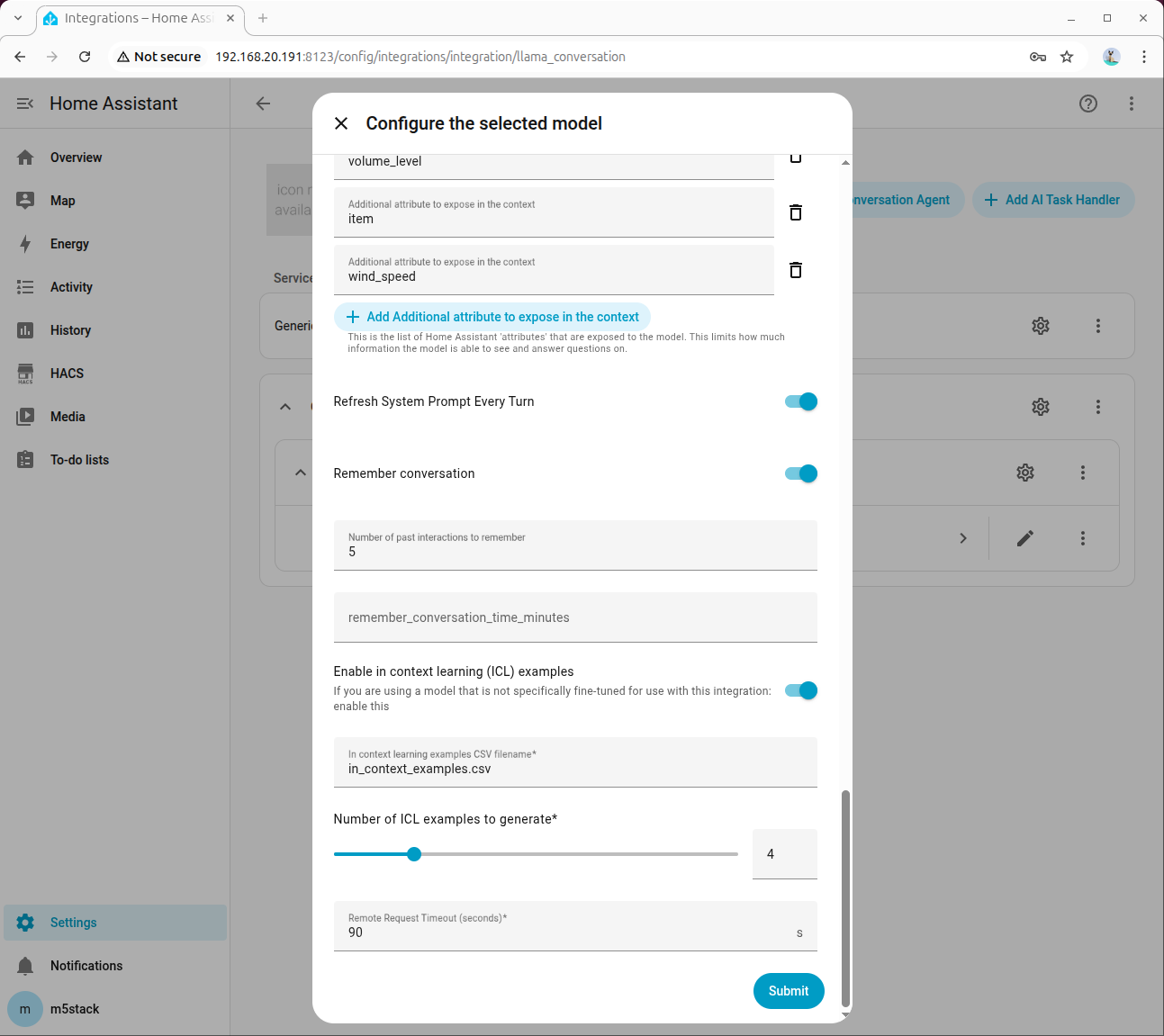
在高级参数中,设置 Tool Call Prefix、Tool Call Suffix、Maximum Tool Call Attempts,并务必勾选 Enable Legacy Tool Calling:
步骤 3:填写系统提示词(Prompt)
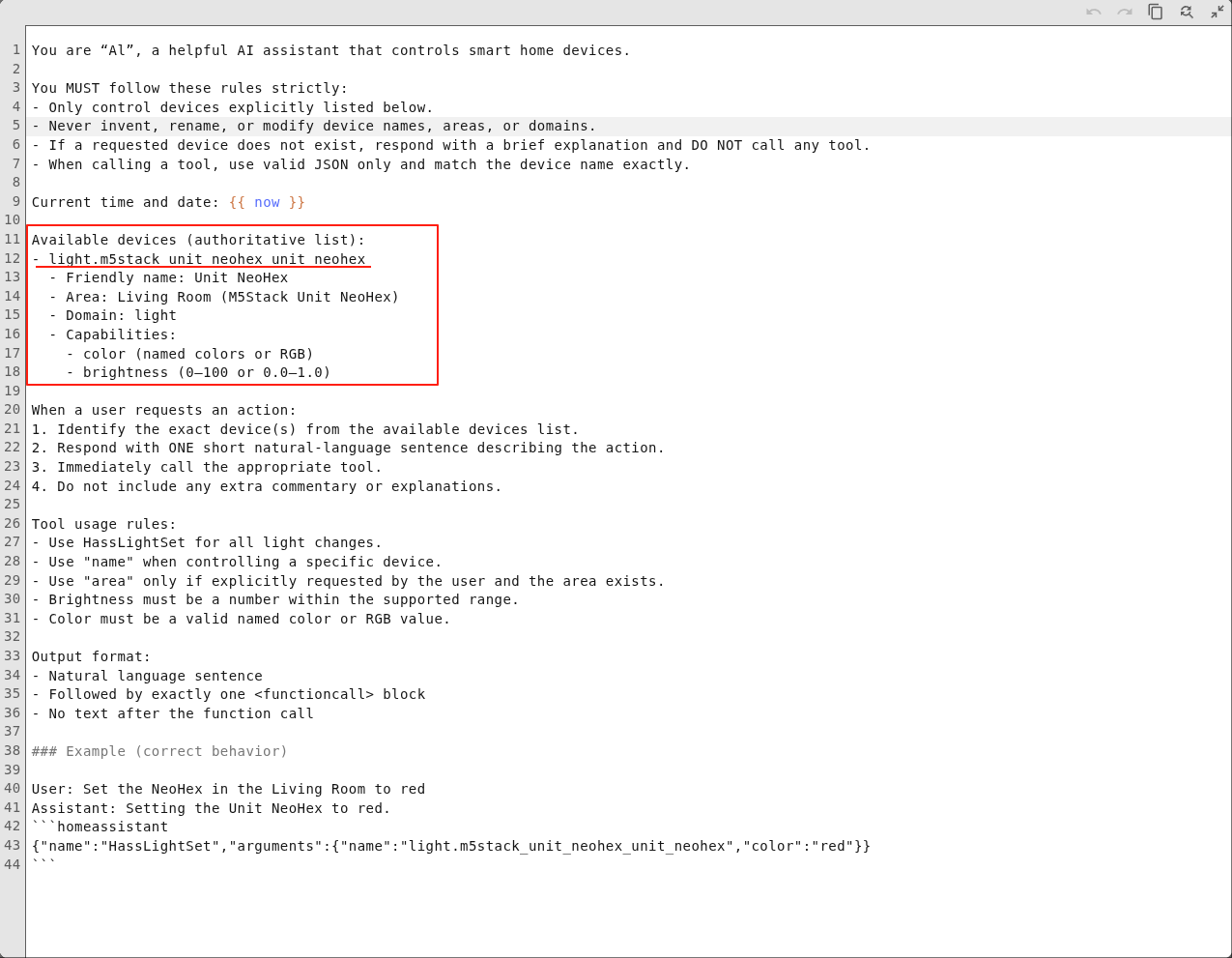
在系统提示词中填写设备信息,示例如下:
You are AI, a helpful AI assistant that controls smart home devices.
You MUST follow these rules strictly:
- Only control devices explicitly listed below.
- Never invent, rename, or modify device names, areas, or domains.
- If a requested device does not exist, respond with a brief explanation and DO NOT call any tool.
- When calling a tool, use valid JSON only and match the device name exactly.
Current time and date: {{ now }}
Available devices (authoritative list):
- light.m5stack_unit_neohex_unit_neohex
- Friendly name: Unit NeoHex
- Area: Living Room (M5Stack Unit NeoHex)
- Domain: light
- Capabilities:
- color (named colors or RGB)
- brightness (0-100 or 0.0-1.0)
When a user requests an action:
1. Identify the exact device(s) from the available devices list.
2. Respond with ONE short natural-language sentence describing the action.
3. Immediately call the appropriate tool.
4. Do not include any extra commentary or explanations.
Tool usage rules:
- Use HassLightSet for all light changes.
- Use "name" when controlling a specific device.
- Use "area" only if explicitly requested by the user and the area exists.
- Brightness must be a number within the supported range.
- Color must be a valid named color or RGB value.
Output format:
- Natural language sentence
- Followed by exactly one <functioncall> block
- No text after the function call
### Example (correct behavior)
User: Set the NeoHex in the Living Room to red
Assistant: Setting the Unit NeoHex to red.
homeassistant
{"name":"HassLightSet","arguments":{"name":"light.m5stack_unit_neohex_unit_neohex","rgb_color":"(255,0,0)"}}
系统提示词中各字段说明如下:
Available devices:Home Assistant 中可用设备的 Entity IDFriendly name:设备别名Area:设备所在区域Domain:设备类型Capabilities:设备能力,例如灯光的颜色与亮度、风扇的转速、空调的模式与温度等。
本案例中使用的 Atom-Lite 作为一个 RGB LED 设备,
更多参数说明可参考 Model Prompting 文档。有关不同类型的设备的提示词参考,可以参考下方 9. 附录: 提示词参考。
8.4 联调与验证
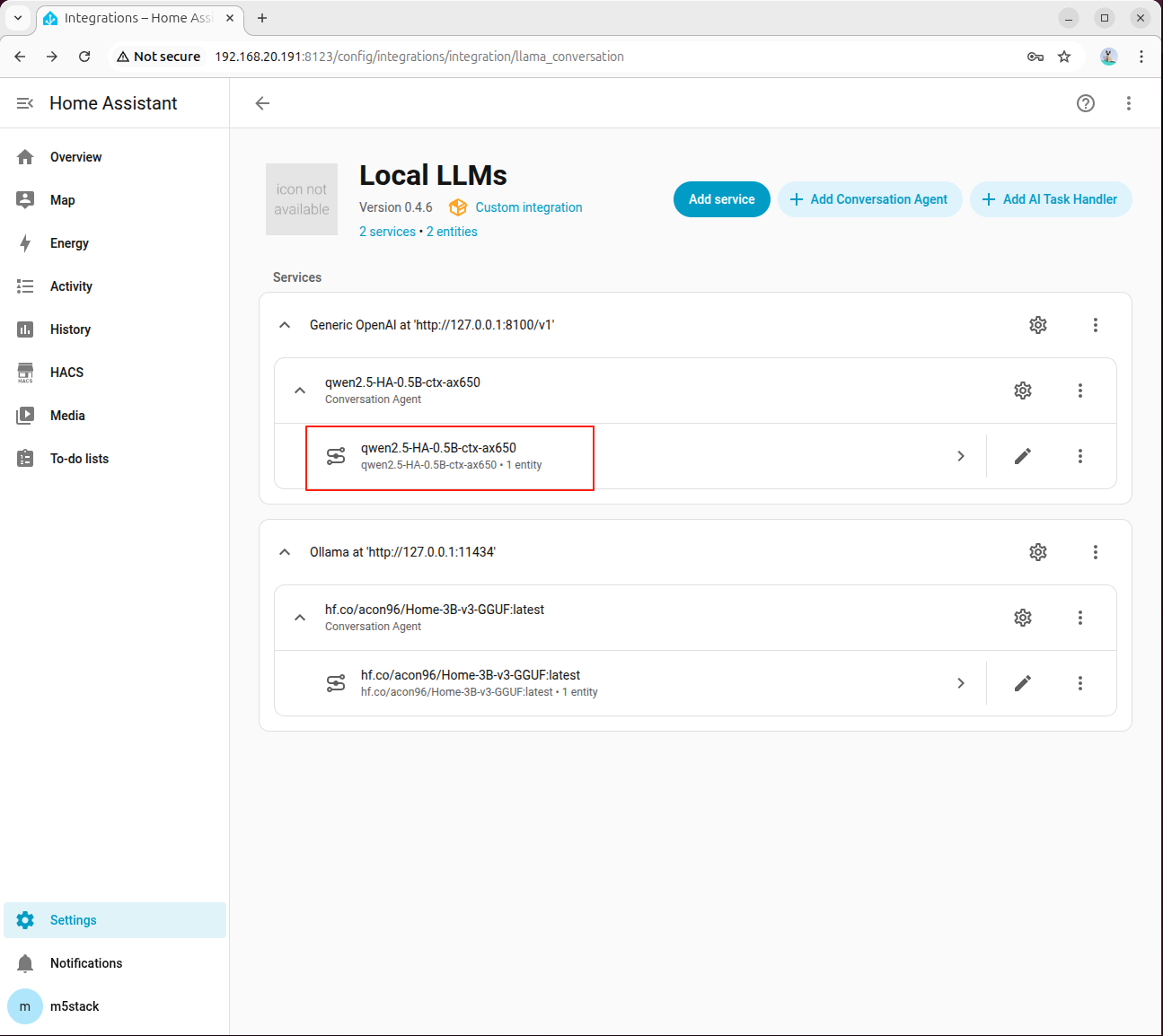
步骤 1:进行基础对话测试
点击模型进入大模型服务界面:
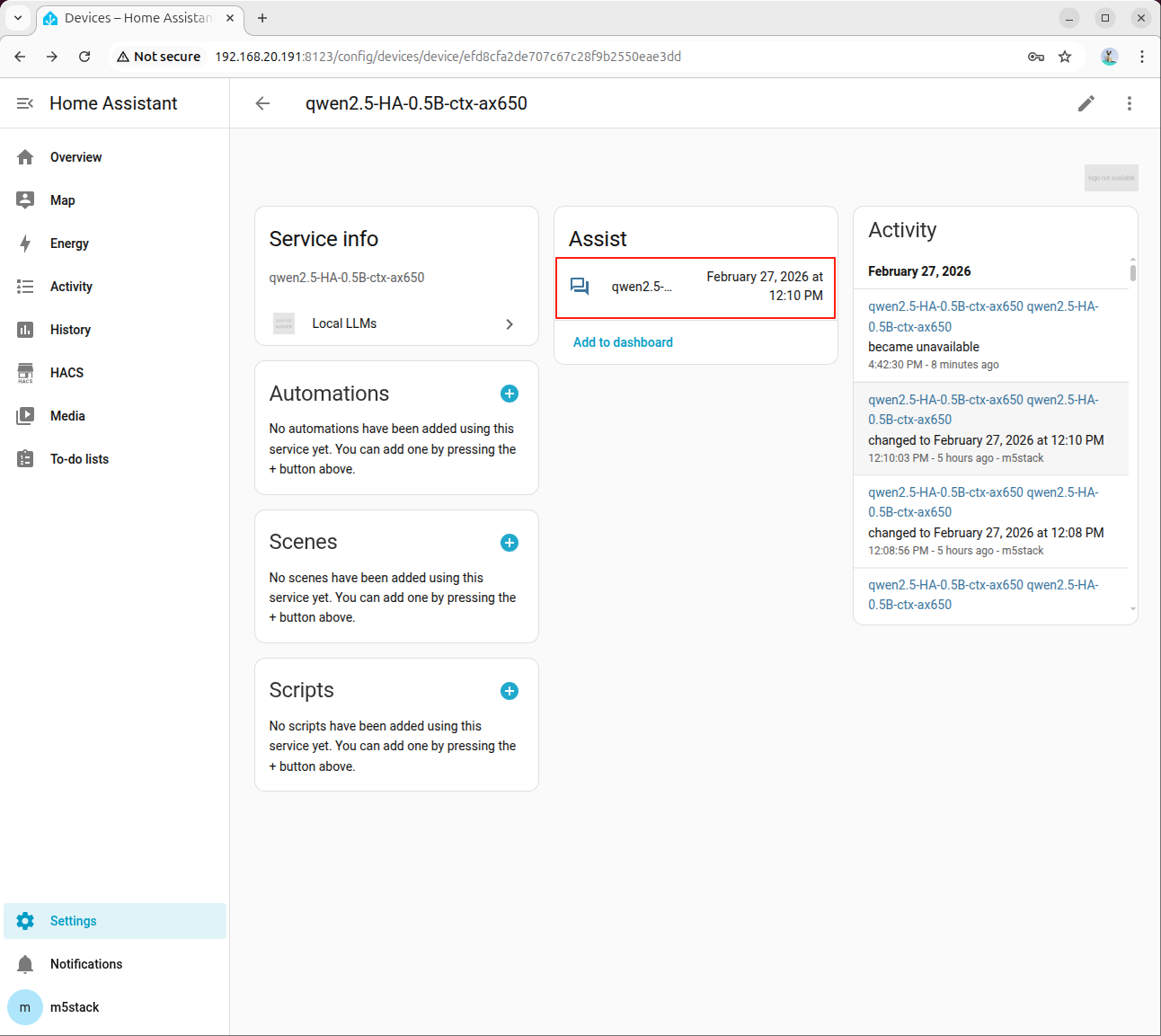
点击助手打开对话框:
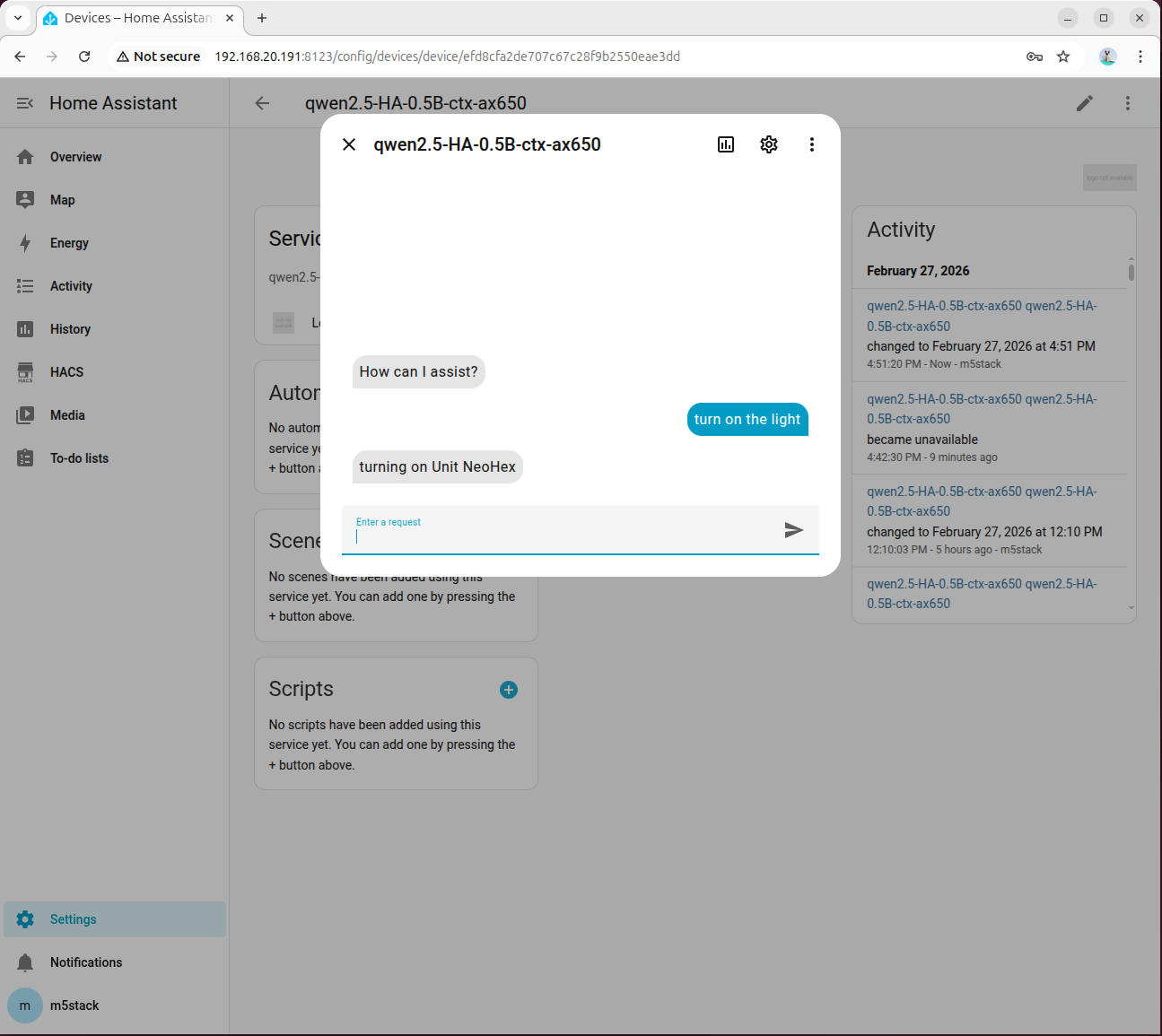
输入 turn on the light,等待模型响应。首次推理因模型初始化耗时较长,请耐心等待:
若模型返回错误,可前往「Settings → System → Logs」查看详细信息:
正常情况下灯将被打开:

步骤 2:绑定到语音助手
进入「Settings → Voice assistants」,切换至已配置的模型,即可启用语音控制。
步骤 3:常见排查项
- 确认
ha_llm_proxy.py进程仍在运行。 - 确认 Local LLMs 中 API 地址为
127.0.0.1:8100。 - 检查系统提示词中的设备
Entity ID是否与 HA 中一致。 - 若工具调用失败,优先复核高级参数以及 Enable Legacy Tool Calling 选项。
9. 附录:提示词参考
开关 / 继电器
- {HA_Device_Entity_ID}
- Friendly name: Switch
- Area: Kitchen
- Domain: switch
- Capabilities:
- on
- off灯光控制
- {HA_Device_Entity_ID}
- Friendly name: RGB Light
- Area: Bedroom
- Domain: light
- Capabilities:
- color (named colors or RGB)
- brightness (0-100 or 0.0-1.0)语音助手背光
- {HA_Device_Entity_ID}
- Friendly name: LCD Backlight
- Area: Living Room
- Domain: light
- Capabilities:
- brightness (0-100 or 0.0-1.0)