

StackFlow AI プラットフォーム
デバイスとクイックスタート
モデルの紹介
Qwen3
DeepSeek-R1
AI Pyramid Applications
アプリケーション
CVビジョンアプリケーション
VLMマルチモーダル
大規模言語モデル (LLM)
音声アシスタント
AI Pyramid - Home Assistant
Home Assistant はオープンソースのスマートホームプラットフォームです。ローカルでのデバイス管理と自動化制御をサポートし、プライバシー保護・高い信頼性・柔軟なカスタマイズ性を備えています。
1. 事前準備
2. イメージのインストール
Home Assistant 公式ドキュメントを参照するか、以下の手順に従って Docker コンテナをデプロイしてください。
- Home Assistant Docker イメージのプル
- /PATH_TO_YOUR_CONFIG は設定ファイルを保存して実行するフォルダーのパスを指定します。
:/configの部分は必ず残してください。 - MY_TIME_ZONE は tz データベース名です。例:
TZ=America/Los_Angeles
docker run -d \
--name homeassistant \
--privileged \
--restart=unless-stopped \
-e TZ=MY_TIME_ZONE \
-v /PATH_TO_YOUR_CONFIG:/config \
-v /run/dbus:/run/dbus:ro \
--network=host \
ghcr.io/home-assistant/home-assistant:stable3. HAOS の初期設定
- ブラウザから Home Assistant Web インターフェースにアクセスします。ローカルアクセスは
http://homeassistant.local:8123/、リモートアクセスはhttp://デバイスIP:8123/を使用してください。
- 画面の指示に従って管理者アカウントを作成し、システムの初期設定を完了させてください。
4. デバイスファームウェアのビルド
- ESPHome 公式インストールガイドを参照し、開発ホストに ESPHome 開発環境をデプロイします。
本ドキュメントは ESPHome 2026.2.1 バージョンをベースに作成されています。バージョン間で大きな差異があるため、プロジェクトの YAML 設定ファイルの要件に応じた対応バージョンを選択してください。
pip install esphome==2026.2.1- M5Stack ESPHome 設定ファイルリポジトリをクローンします。
git clone https://github.com/m5stack/esphome-yaml.git- ESPHome Dashboard サービスを起動します。
esphome dashboard esphome-yaml/- ブラウザから 127.0.0.1:6052 にアクセスします。
- Wi-Fi 接続パラメータを設定します。
# Your Wi-Fi SSID and password
wifi_ssid: "your_wifi_name"
wifi_password: "your_wifi_password"- OpenSSL を使用して暗号化キーを生成します。
openssl rand -base64 32キー生成の出力例:
(base) m5stack@MS-7E06:~$ openssl rand -base64 32
BUEzgskL8daDJ5rLD90Chq2M43jC0haA/vVxcULQAls=cores3-config-example.yaml設定ファイルを編集し、生成した暗号化キーを該当フィールドに入力します。
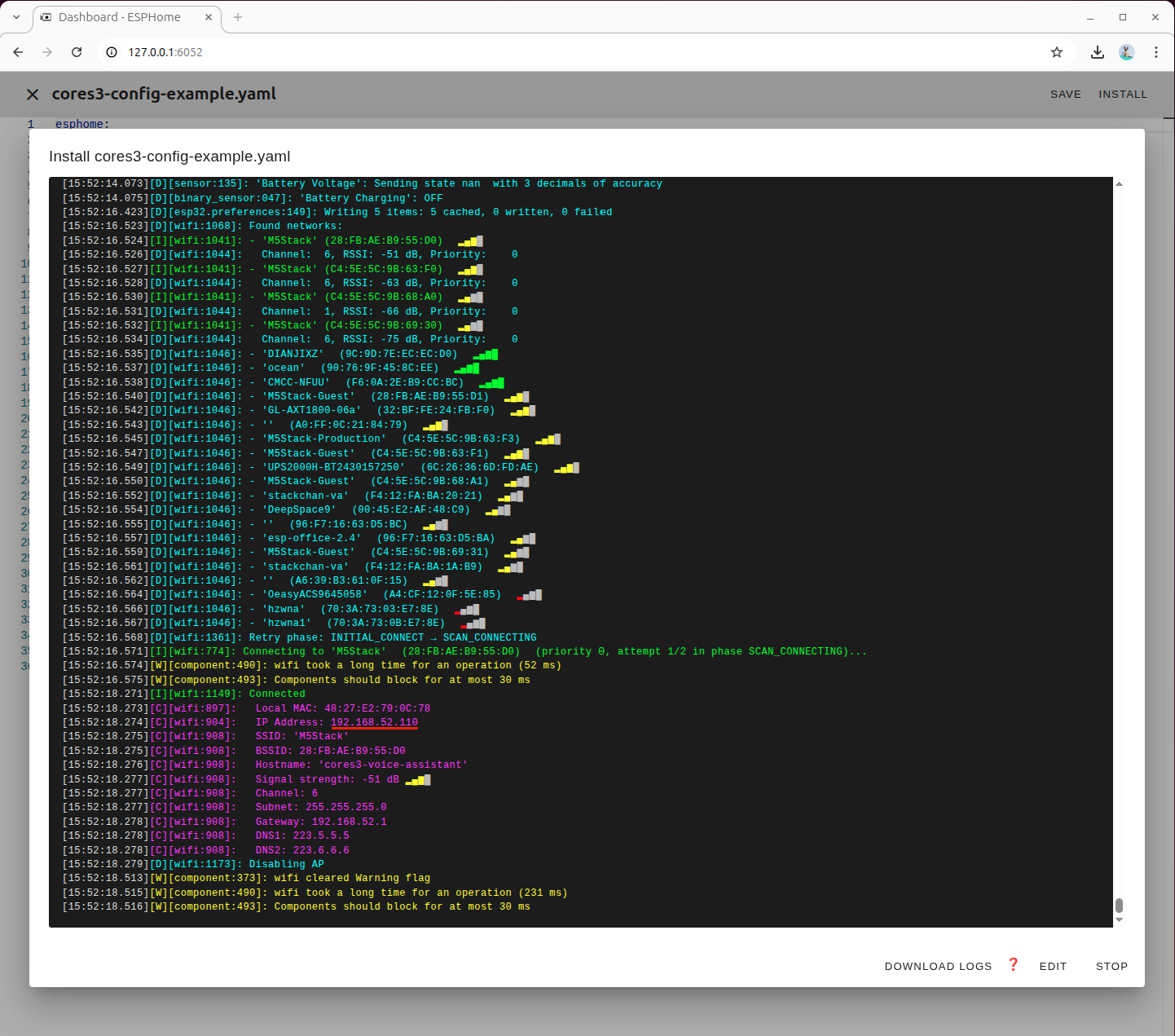
左上の INSTALL ボタンをクリックしてビルドを開始します。
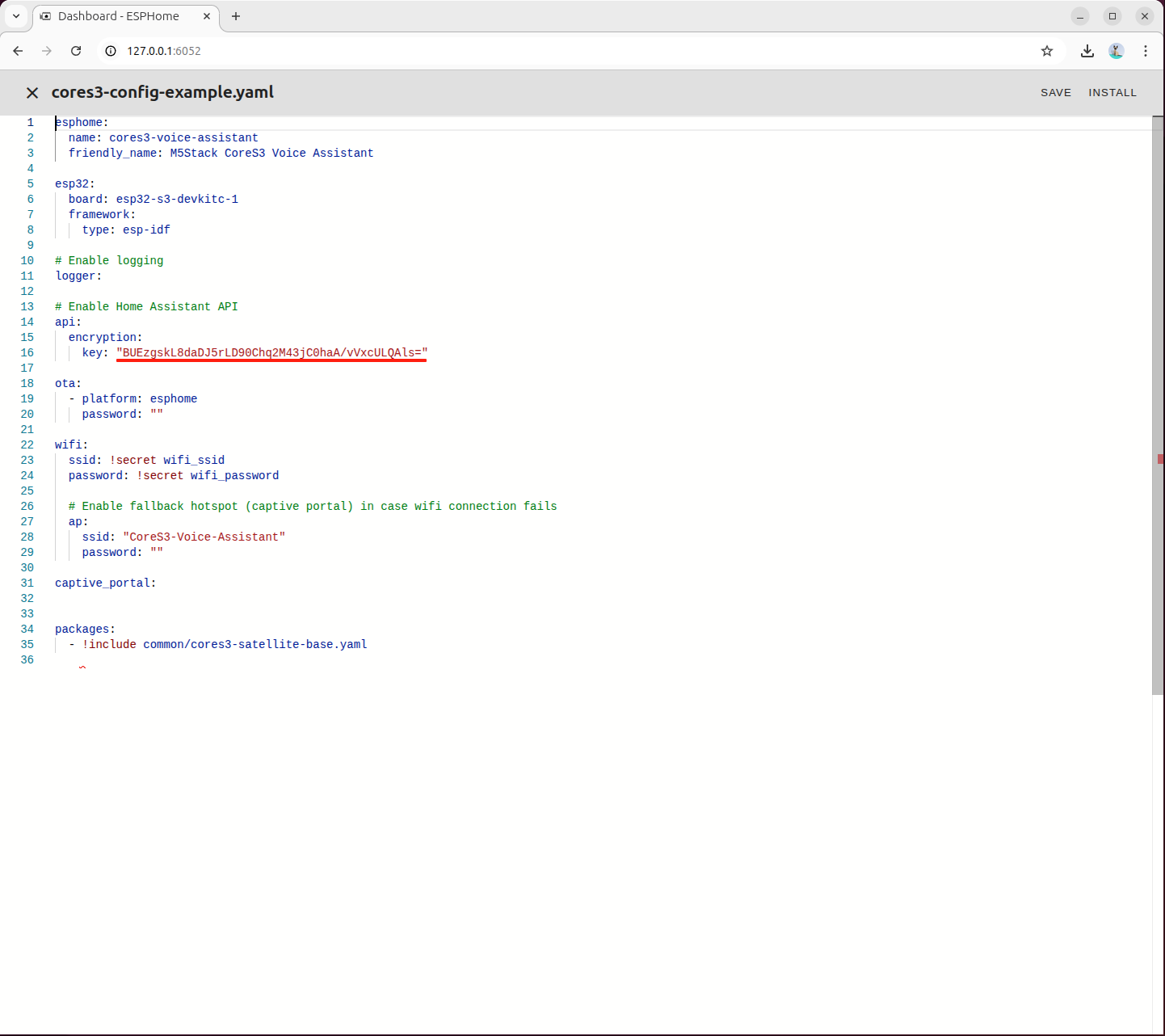
3番目の項目を選択し、ターミナルでビルド出力をリアルタイムに確認します。
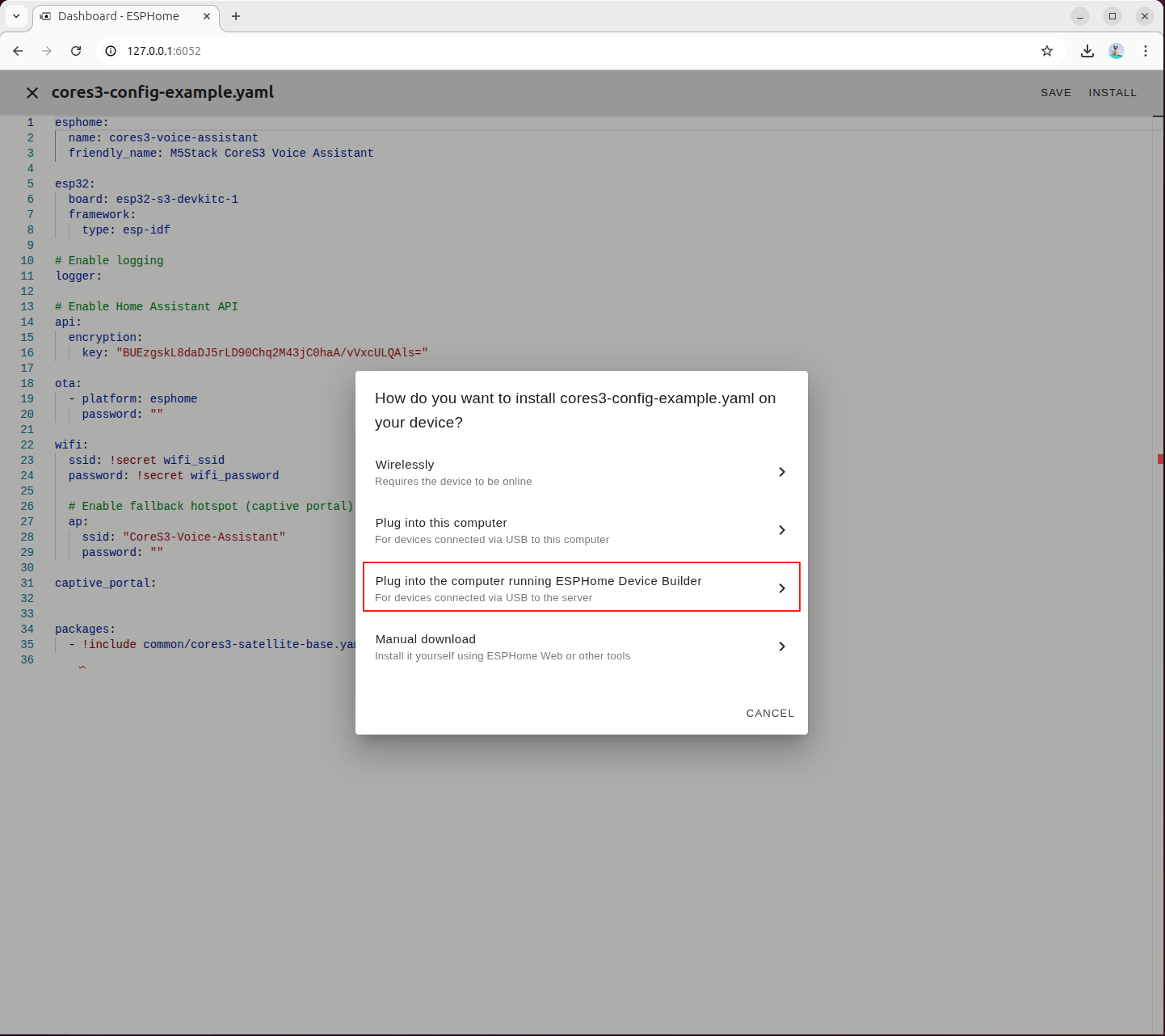
CoreS3 に対応するシリアルポートデバイスを選択します。
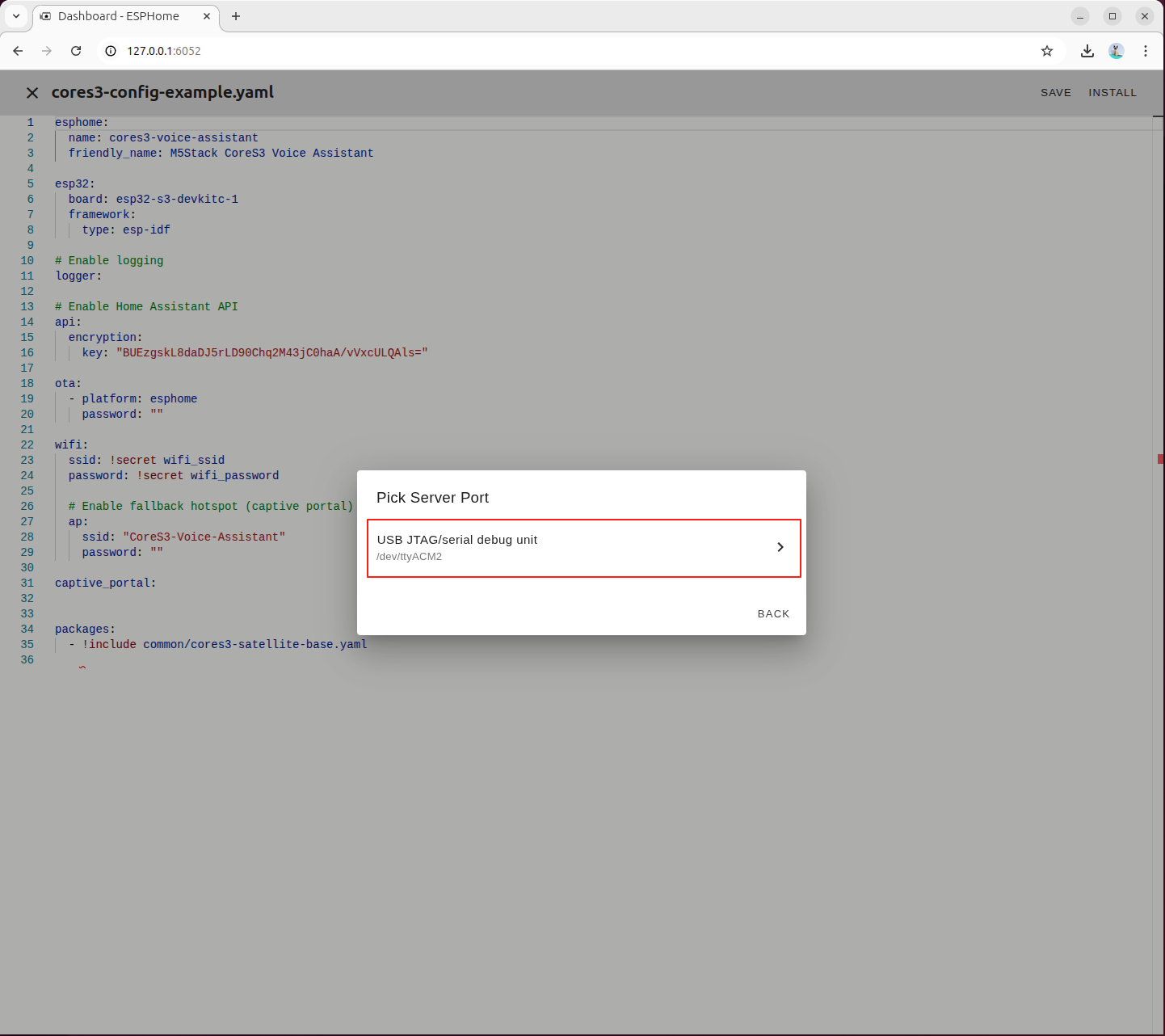
初回ビルド時は必要な依存関係が自動的にダウンロードされます。
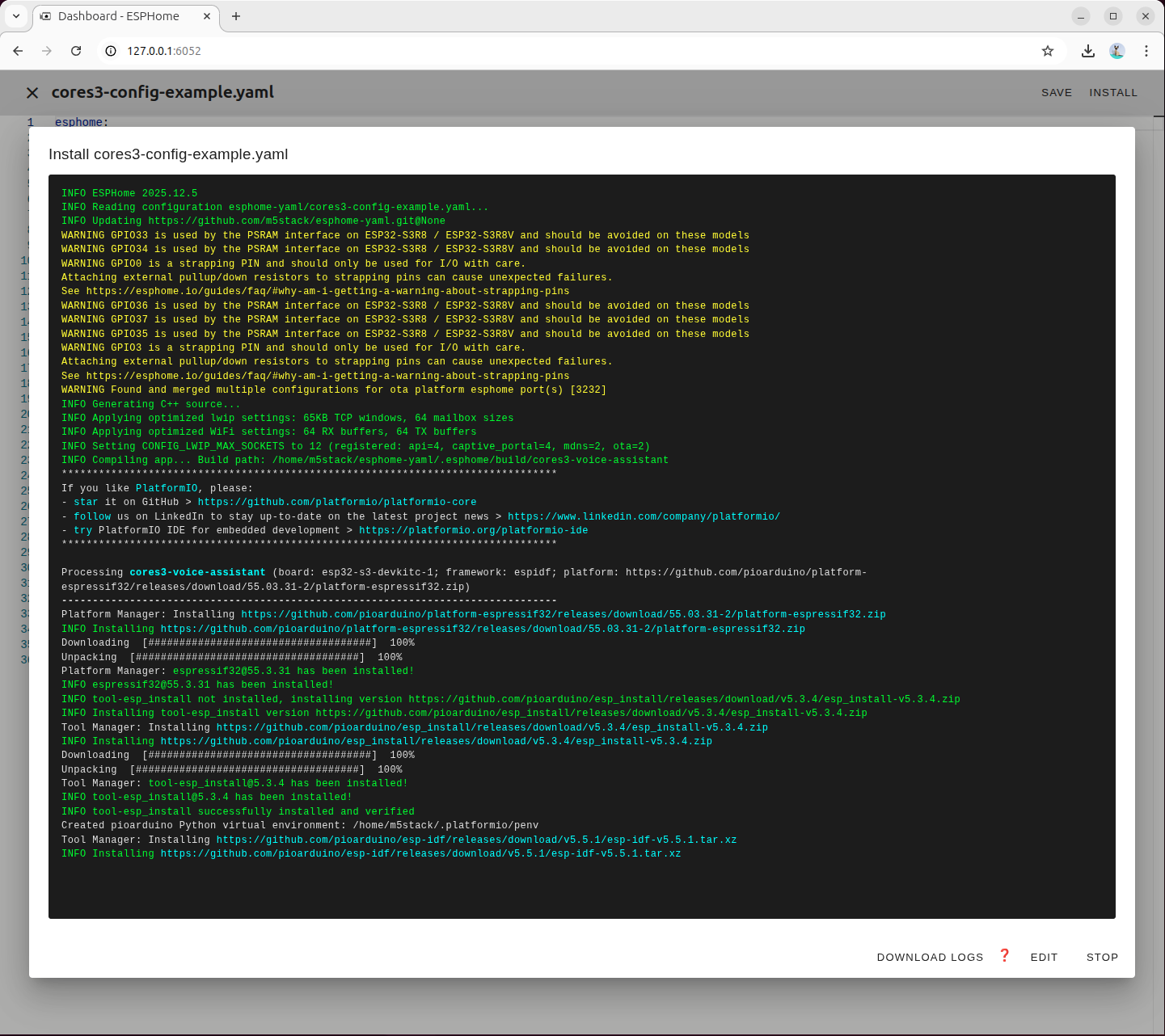
ファームウェアのビルドおよび書き込みが完了するまで待機します。
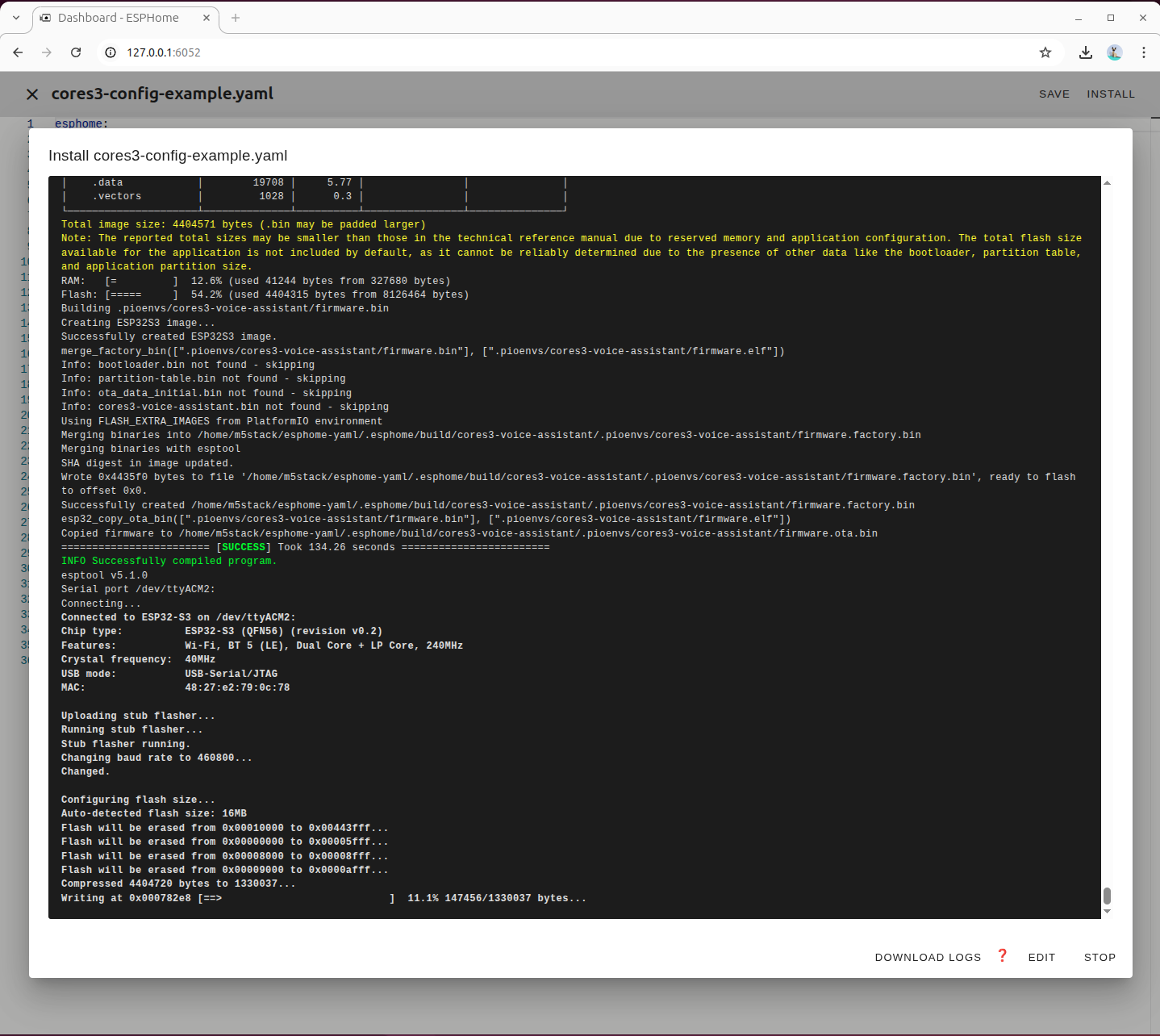
デバイス再起動後、取得した IP アドレスを記録しておいてください。後ほど Home Assistant にデバイスを統合する際に使用します。
5. デバイスの追加
- Home Assistant の設定画面に入り、デバイスの追加を選択します。
- インテグレーション一覧から ESPHome を検索します。
- Host フィールドにデバイスの IP アドレスを入力し、Port フィールドには YAML 設定ファイルで定義したポート番号を入力します。
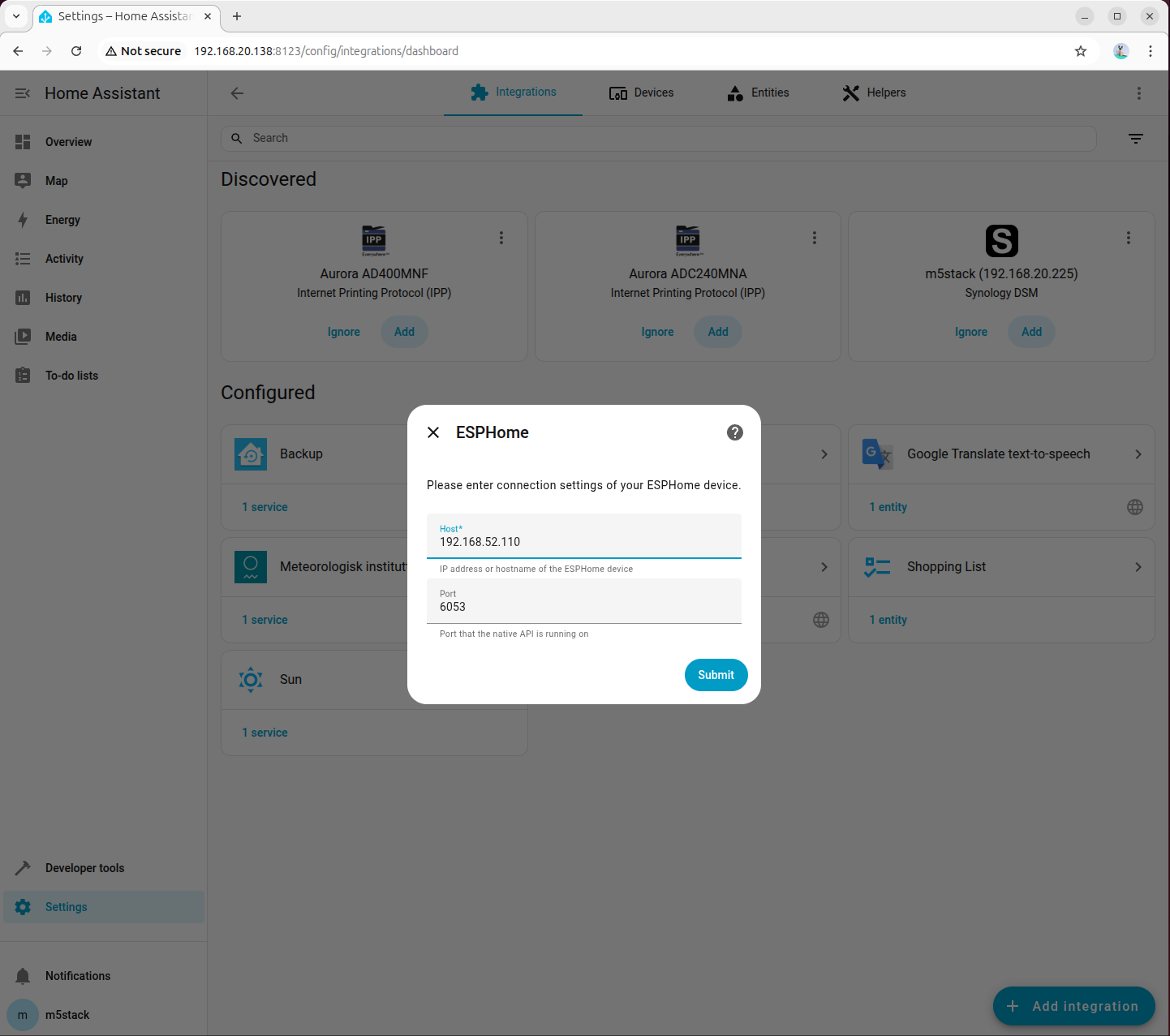
- YAML 設定ファイルで定義した暗号化キーを入力します。
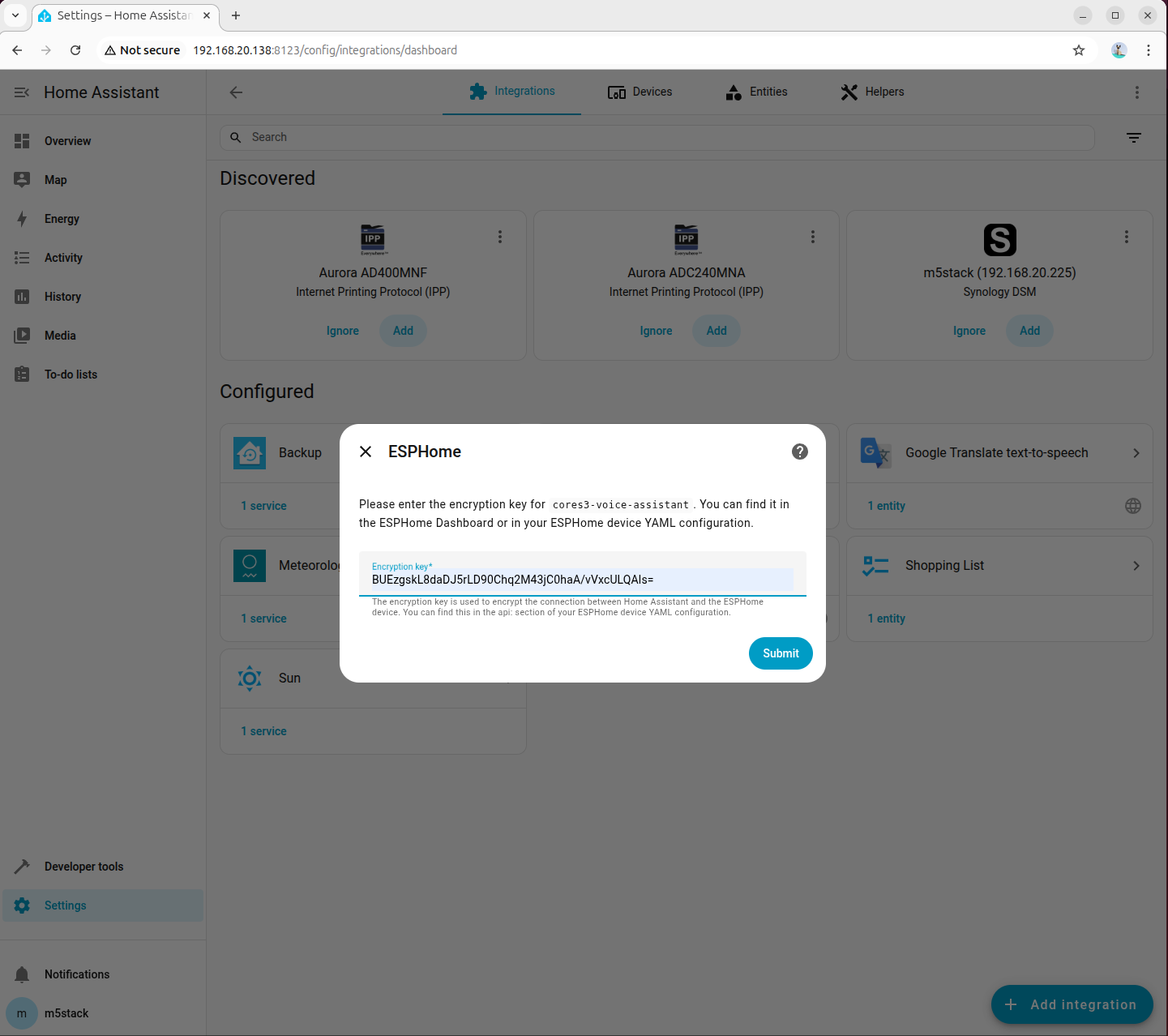
- 音声処理モードは一時的にクラウド処理を選択します。
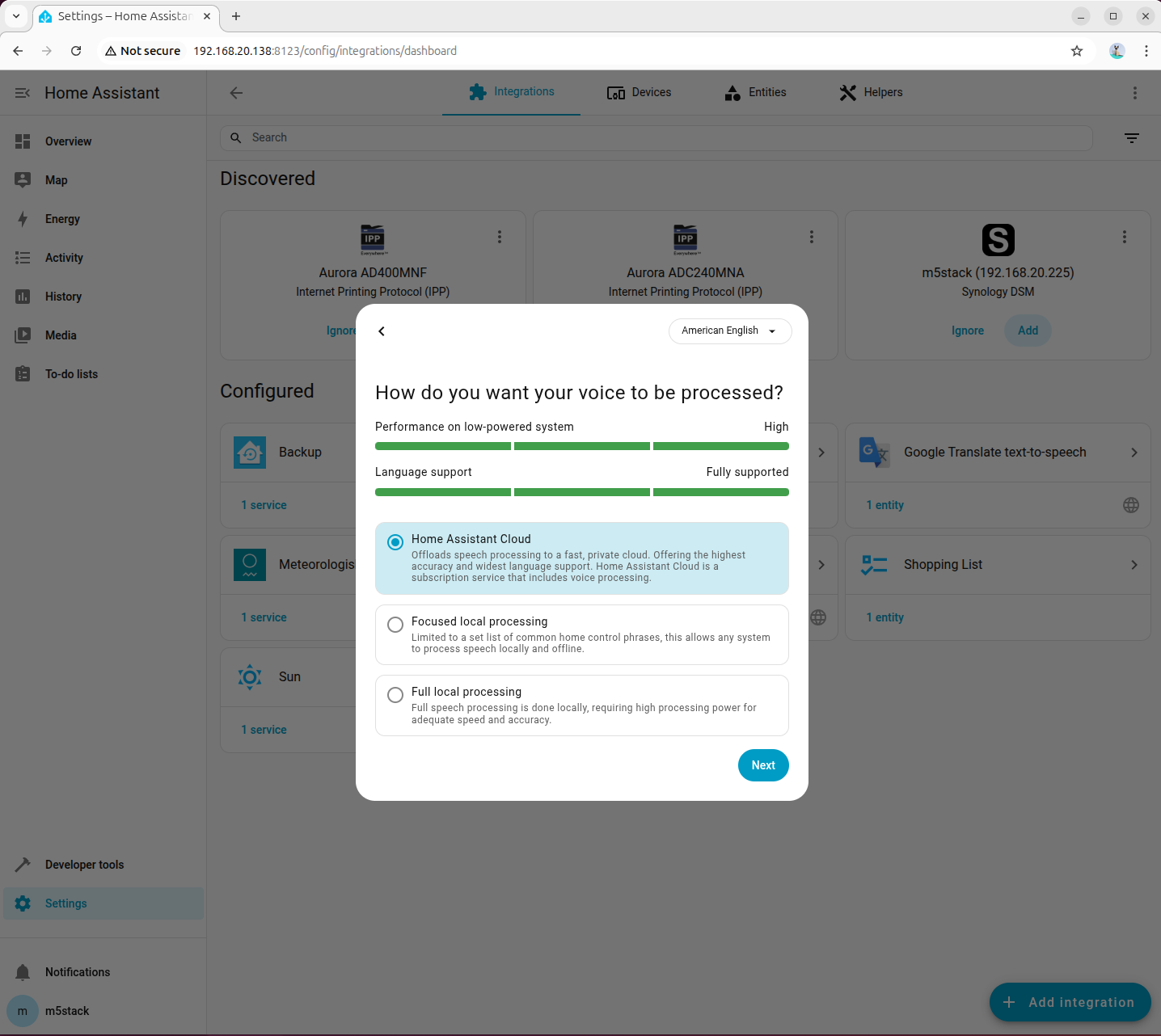
- 音声ウェイクワードと TTS エンジンのパラメータを設定します。
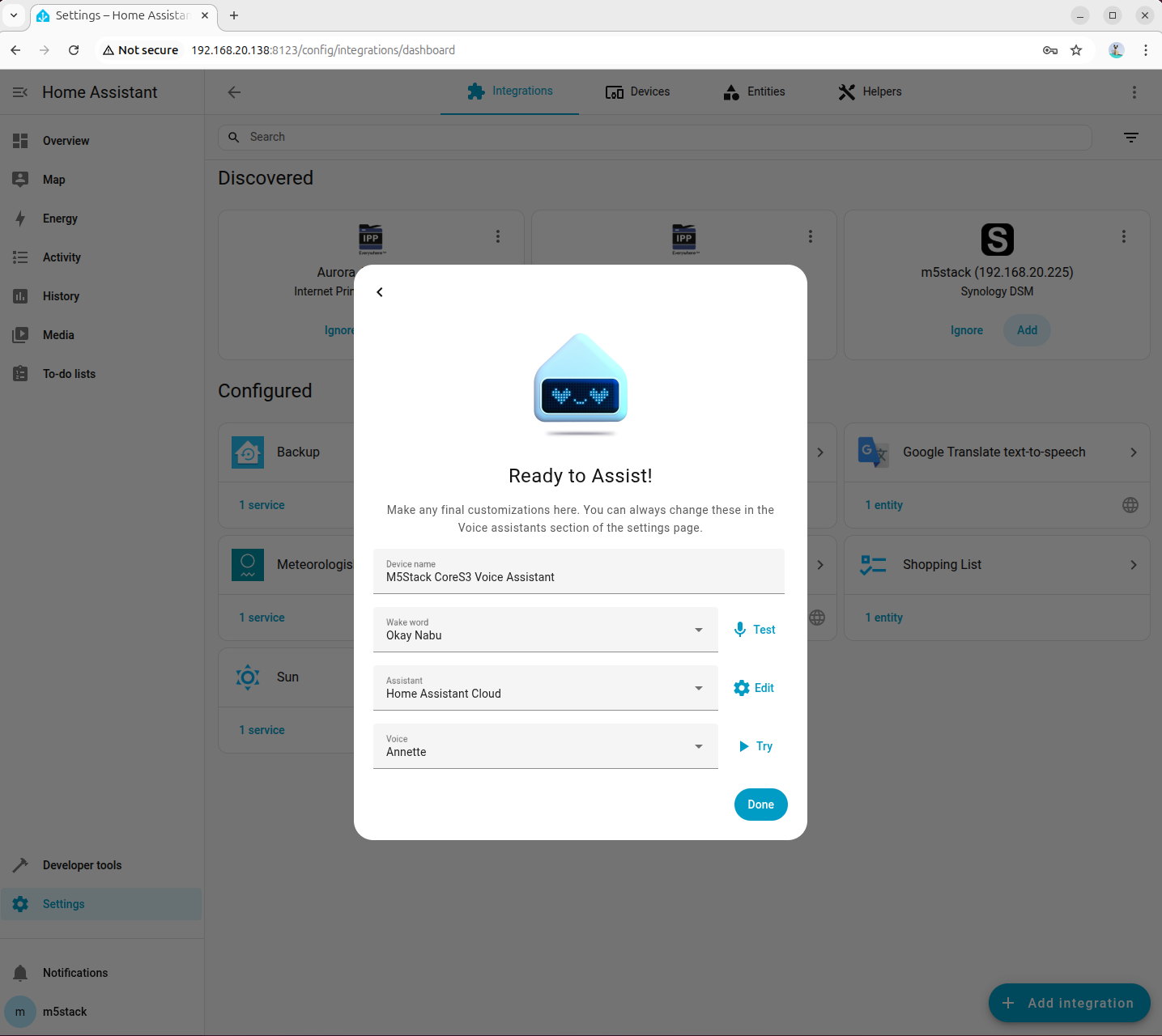
- 設定完了後、デバイスが Home Assistant の概要ページに表示されます。
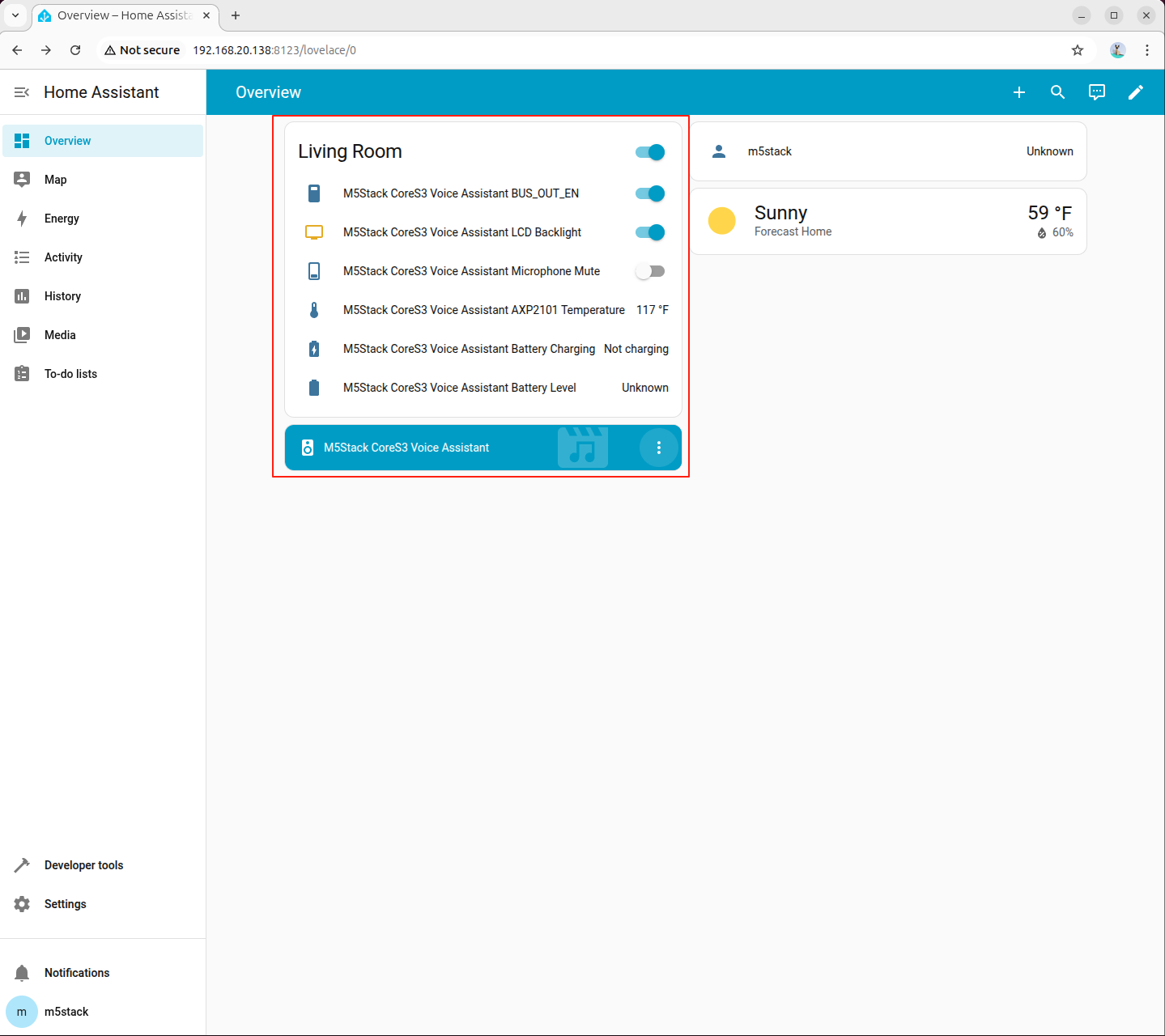
6. ローカル音声アシスタントの設定
Wyoming Protocol を使用することで、Home Assistant にローカル音声認識および音声合成機能を統合し、完全オフラインの音声アシスタントを実現できます。
6.1 音声テキスト変換(ASR)の設定
ステップ 1:依存パッケージとモデルのインストール
音声認識に必要な依存パッケージとモデルがシステムにインストールされていることを確認してください。
apt install lib-llm llm-sys llm-asr llm-openai-api llm-model-sense-voice-small-10s-ax650pip install openai wyomingステップ 2:Wyoming 音声テキスト変換サービスの作成
AI Pyramid で新しいファイル wyoming_whisper_service.py を作成し、以下のコードをコピーしてください。
#!/usr/bin/env python3
# SPDX-FileCopyrightText: 2026 M5Stack Technology CO LTD
#
# SPDX-License-Identifier: MIT
"""
Wyoming protocol server for an OpenAI-compatible SenseVoice API.
Compatible with Wyoming protocol 1.8.0 for SenseVoice transcription.
"""
import argparse
import asyncio
import io
import logging
import wave
from functools import partial
from typing import Optional
from openai import OpenAI
from wyoming.asr import Transcribe, Transcript
from wyoming.audio import AudioChunk, AudioStart, AudioStop
from wyoming.event import Event
from wyoming.info import AsrModel, AsrProgram, Attribution, Info
from wyoming.server import AsyncServer, AsyncEventHandler
_LOGGER = logging.getLogger(__name__)
class SenseVoiceEventHandler(AsyncEventHandler):
"""Handle Wyoming protocol audio transcription requests."""
def __init__(
self,
wyoming_info: Info,
client: OpenAI,
model: str,
language: Optional[str] = None,
*args,
**kwargs,
) -> None:
super().__init__(*args, **kwargs)
self.client = client
self.wyoming_info_event = wyoming_info.event()
self.model = model
self.language = language
# Audio buffer state for a single transcription request.
self.audio_buffer: Optional[io.BytesIO] = None
self.wav_file: Optional[wave.Wave_write] = None
_LOGGER.info("Handler initialized with model: %s", model)
async def handle_event(self, event: Event) -> bool:
"""Handle Wyoming protocol events."""
# Service info request.
if event.type == "describe":
_LOGGER.debug("Received describe request")
await self.write_event(self.wyoming_info_event)
_LOGGER.info("Sent info response")
return True
# Transcription request.
if Transcribe.is_type(event.type):
transcribe = Transcribe.from_event(event)
_LOGGER.info("Transcribe request: language=%s", transcribe.language)
# Reset audio buffers for the new request.
self.audio_buffer = None
self.wav_file = None
return True
# Audio stream starts.
if AudioStart.is_type(event.type):
_LOGGER.debug("Audio start")
return True
# Audio stream chunk.
if AudioChunk.is_type(event.type):
chunk = AudioChunk.from_event(event)
# Initialize WAV writer on the first chunk.
if self.wav_file is None:
_LOGGER.debug("Creating WAV buffer")
self.audio_buffer = io.BytesIO()
self.wav_file = wave.open(self.audio_buffer, "wb")
self.wav_file.setframerate(chunk.rate)
self.wav_file.setsampwidth(chunk.width)
self.wav_file.setnchannels(chunk.channels)
# Append raw audio frames.
self.wav_file.writeframes(chunk.audio)
return True
# Audio stream ends; perform transcription.
if AudioStop.is_type(event.type):
_LOGGER.info("Audio stop - starting transcription")
if self.wav_file is None:
_LOGGER.warning("No audio data received")
return False
try:
# Finalize WAV payload.
self.wav_file.close()
# Extract audio bytes.
self.audio_buffer.seek(0)
audio_data = self.audio_buffer.getvalue()
# Build in-memory file for the API client.
audio_file = io.BytesIO(audio_data)
audio_file.name = "audio.wav"
# Call the transcription API.
_LOGGER.info("Calling transcription API")
transcription_params = {
"model": self.model,
"file": audio_file,
}
# Add language if explicitly set.
if self.language:
transcription_params["language"] = self.language
result = self.client.audio.transcriptions.create(**transcription_params)
# Extract transcript text.
if hasattr(result, "text"):
transcript_text = result.text
else:
transcript_text = str(result)
_LOGGER.info("Transcription result: %s", transcript_text)
# Send transcript back to the client.
await self.write_event(Transcript(text=transcript_text).event())
_LOGGER.info("Sent transcript")
except Exception as e:
_LOGGER.error("Transcription error: %s", e, exc_info=True)
# Send empty transcript on error to keep protocol flow.
await self.write_event(Transcript(text="").event())
finally:
# Release buffers for the next request.
self.audio_buffer = None
self.wav_file = None
return True
return True
async def main() -> None:
"""Program entrypoint."""
parser = argparse.ArgumentParser(
description="Wyoming protocol server for OpenAI-compatible SenseVoice API"
)
parser.add_argument(
"--uri",
default="tcp://0.0.0.0:10300",
help="URI to listen on (default: tcp://0.0.0.0:10300)",
)
parser.add_argument(
"--api-key",
default="sk-",
help="OpenAI API key (default: sk-)",
)
parser.add_argument(
"--base-url",
default="http://127.0.0.1:8000/v1",
help="API base URL (default: http://127.0.0.1:8000/v1)",
)
parser.add_argument(
"--model",
default="sense-voice-small-10s-ax650",
help="Model name (default: sense-voice-small-10s-ax650)",
)
parser.add_argument(
"--language",
help="Language code (e.g., en, zh, auto)",
)
parser.add_argument(
"--debug",
action="store_true",
help="Enable debug logging",
)
args = parser.parse_args()
# Configure logging.
logging.basicConfig(
level=logging.DEBUG if args.debug else logging.INFO,
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
)
_LOGGER.info("Starting Wyoming SenseVoice service")
_LOGGER.info("API Base URL: %s", args.base_url)
_LOGGER.info("Model: %s", args.model)
_LOGGER.info("Language: %s", args.language or "auto")
# Initialize OpenAI client.
client = OpenAI(
api_key=args.api_key,
base_url=args.base_url,
)
# Build Wyoming service metadata (protocol 1.8.0 compatible).
wyoming_info = Info(
asr=[
AsrProgram(
name=args.model,
description=f"OpenAI-compatible SenseVoice API ({args.model})",
attribution=Attribution(
name="SenseVoice",
url="https://github.com/FunAudioLLM/SenseVoice",
),
version="1.0.0",
installed=True,
models=[
AsrModel(
name=args.model,
description=f"SenseVoice model: {args.model}",
attribution=Attribution(
name="SenseVoice",
url="https://github.com/FunAudioLLM/SenseVoice",
),
installed=True,
languages=(
["zh", "en", "yue", "ja", "ko"]
if not args.language
else [args.language]
),
version="1.0.0",
)
],
)
],
)
_LOGGER.info("Service info created")
# Create server.
server = AsyncServer.from_uri(args.uri)
_LOGGER.info("Server listening on %s", args.uri)
# Run server loop.
try:
await server.run(
partial(
SenseVoiceEventHandler,
wyoming_info,
client,
args.model,
args.language,
)
)
except KeyboardInterrupt:
_LOGGER.info("Server stopped by user")
except Exception as e:
_LOGGER.error("Server error: %s", e, exc_info=True)
if __name__ == "__main__":
asyncio.run(main())ステップ 3:音声テキスト変換サービスの起動
以下のコマンドでサービスを起動します(IP アドレスは実際の AI Pyramid のアドレスに置き換えてください)。
python wyoming_whisper_service.py --base-url http://192.168.20.138:8000/v1192.168.20.138 を実際に使用している AI Pyramid デバイスの IP アドレスに置き換えてください。起動成功時の出力例:
root@m5stack-AI-Pyramid:~/wyoming-openai-stt# python wyoming_whisper_service.py --base-url http://192.168.20.138:8000/v1
2026-02-04 16:29:45,121 - __main__ - INFO - Starting Wyoming Whisper service
2026-02-04 16:29:45,122 - __main__ - INFO - API Base URL: http://192.168.20.138:8000/v1
2026-02-04 16:29:45,122 - __main__ - INFO - Model: sense-voice-small-10s-ax650
2026-02-04 16:29:45,123 - __main__ - INFO - Language: auto
2026-02-04 16:29:46,098 - __main__ - INFO - Service info created
2026-02-04 16:29:46,099 - __main__ - INFO - Server listening on tcp://0.0.0.0:10300ステップ 4:Home Assistant への Wyoming Protocol の追加
Home Assistant の設定画面に入り、「Wyoming Protocol」インテグレーションを検索して追加します。
ステップ 5:接続パラメータの設定
Wyoming Protocol の接続パラメータを設定します。
- Host:127.0.0.1
- Port:10300
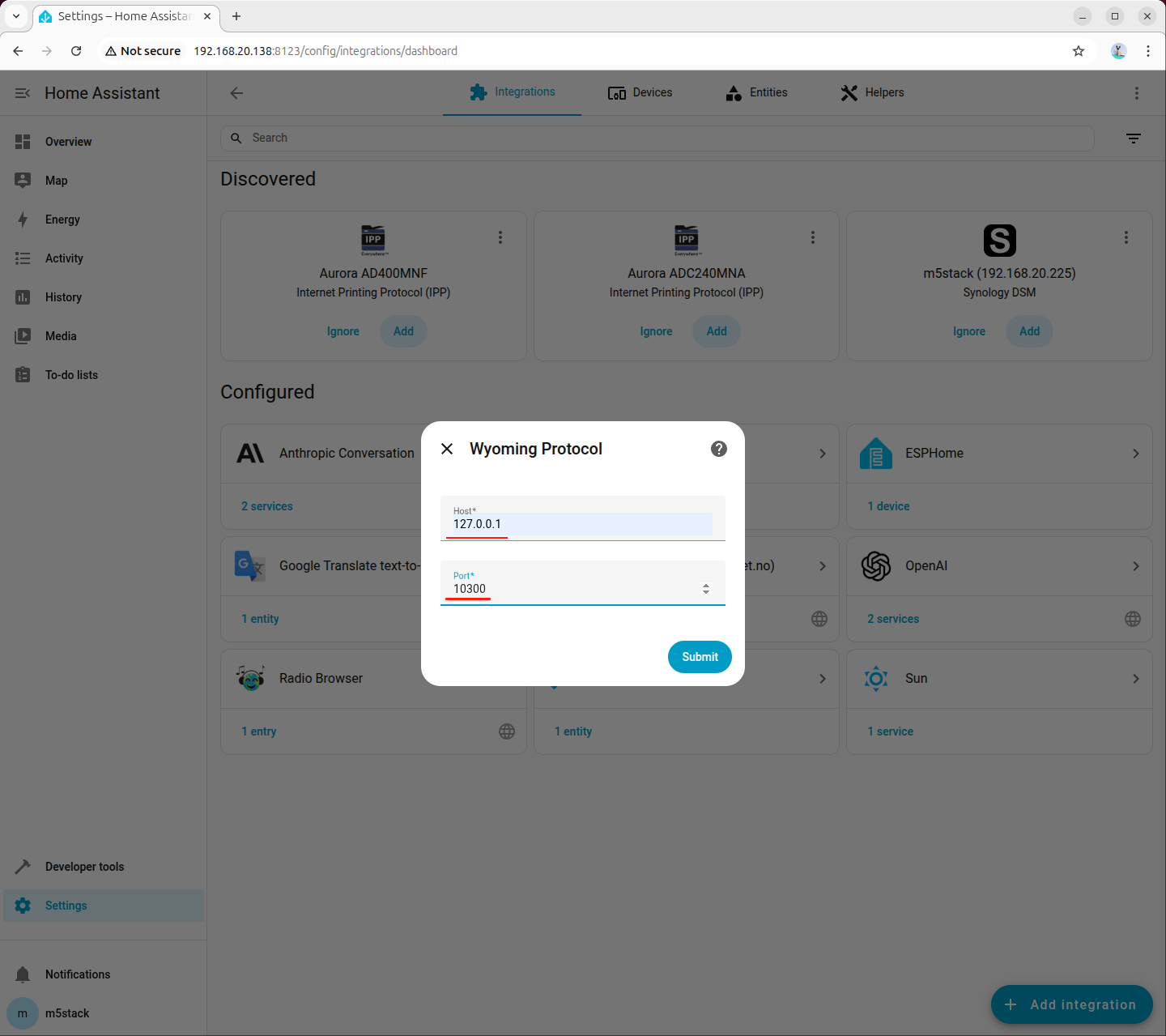
ステップ 6:音声アシスタントの作成
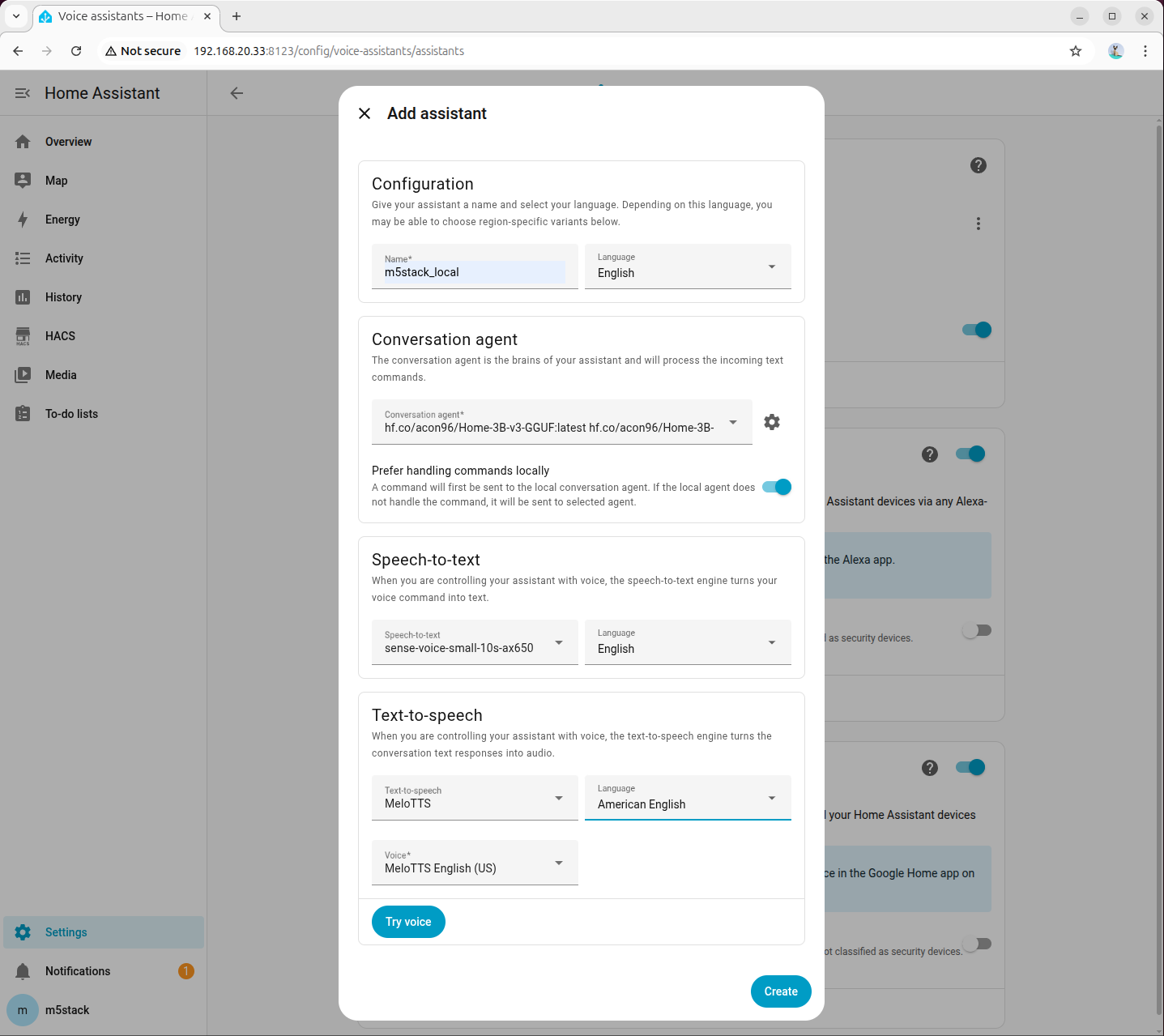
Home Assistant の設定から「音声アシスタント」モジュールに移動し、新しい音声アシスタントの作成をクリックします。
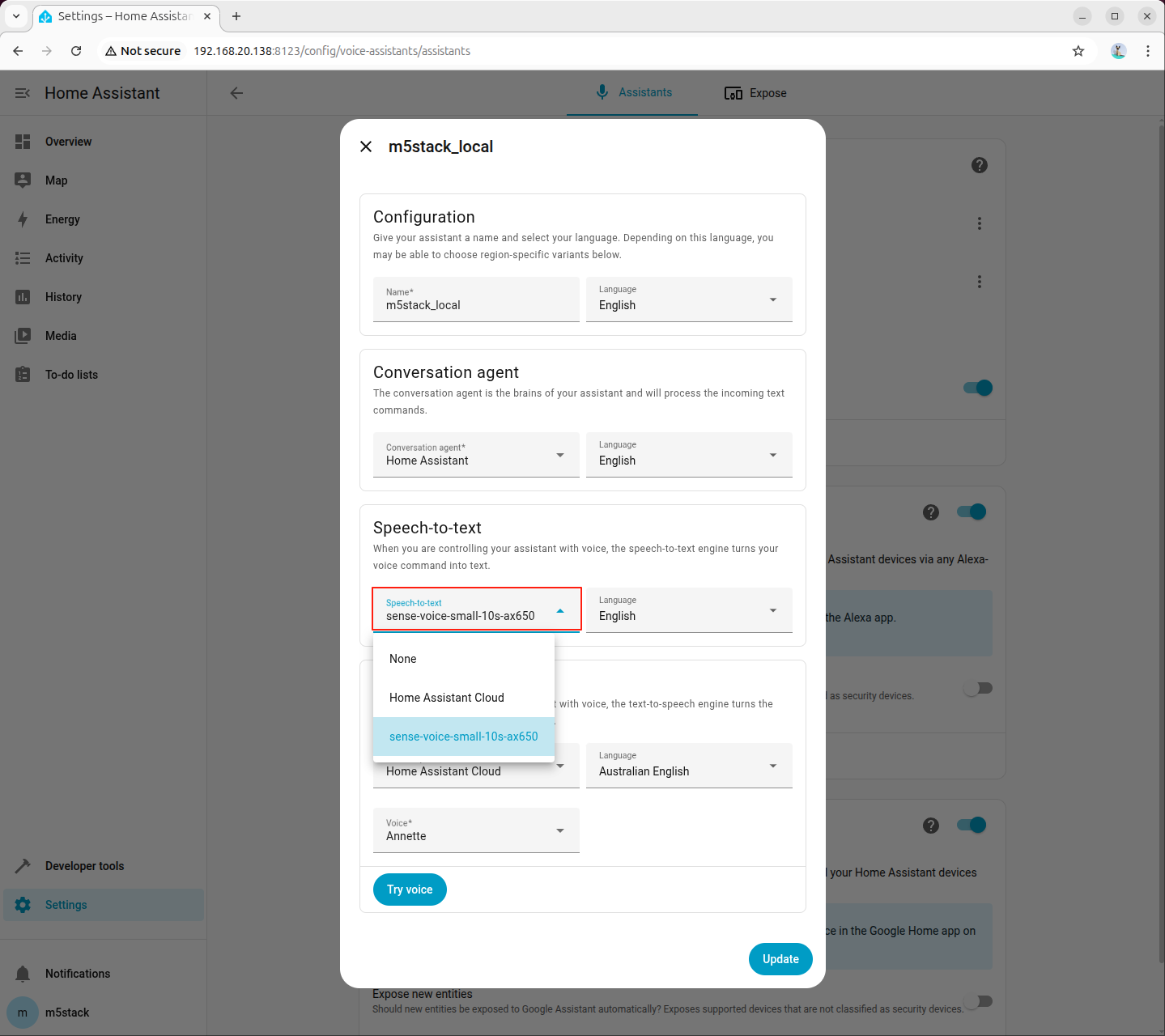
ステップ 7:ASR モデルの設定
音声認識モデルとして先ほど追加した sense-voice-small-10s-ax650 を選択します。言語設定はデフォルトのままで問題ありません。
6.2 テキスト音声変換(TTS)の設定
ステップ 1:依存パッケージとモデルのインストール
音声合成に必要な依存パッケージとモデルがシステムにインストールされていることを確認してください。
apt install lib-llm llm-sys llm-melotts llm-openai-api llm-model-melotts-en-us-ax650pip install openai wyomingllm-model-melotts-zh-cn-ax650、llm-model-melotts-ja-jp-ax650 など、複数言語の MeloTTS モデルをサポートしています。必要に応じてインストールしてください。ステップ 2:Wyoming テキスト音声変換サービスの作成
AI Pyramid で新しいファイル wyoming_openai_tts.py を作成し、以下のコードをコピーしてください。
#!/usr/bin/env python3
# SPDX-FileCopyrightText: 2024 M5Stack Technology CO LTD
#
# SPDX-License-Identifier: MIT
"""
Wyoming protocol server for OpenAI API TTS service.
Connects local OpenAI-compatible TTS API to Home Assistant.
"""
import argparse
import asyncio
import logging
import wave
import io
from pathlib import Path
from typing import Optional
from openai import OpenAI
from wyoming.audio import AudioChunk, AudioStart, AudioStop
from wyoming.event import Event
from wyoming.info import Attribution, Info, TtsProgram, TtsVoice
from wyoming.server import AsyncEventHandler, AsyncServer
from wyoming.tts import Synthesize
_LOGGER = logging.getLogger(__name__)
# Default configuration
DEFAULT_HOST = "0.0.0.0"
DEFAULT_PORT = 10200
DEFAULT_API_BASE_URL = "http://192.168.20.138:8000/v1"
DEFAULT_MODEL = "melotts-zh-cn-ax650"
DEFAULT_VOICE = "melotts-zh-cn-ax650"
DEFAULT_RESPONSE_FORMAT = "wav"
# Available voices for Wyoming protocol
AVAILABLE_VOICES = [
TtsVoice(
name="melotts-en-au-ax650",
description="MeloTTS English (AU)",
attribution=Attribution(
name="MeloTTS",
url="https://huggingface.co/myshell-ai/MeloTTS-English",
),
version="1.0.0",
installed=True,
languages=["en-au"],
),
TtsVoice(
name="melotts-en-default-ax650",
description="MeloTTS English (Default)",
attribution=Attribution(
name="MeloTTS",
url="https://huggingface.co/myshell-ai/MeloTTS-English",
),
version="1.0.0",
installed=True,
languages=["en"],
),
TtsVoice(
name="melotts-en-us-ax650",
description="MeloTTS English (US)",
attribution=Attribution(
name="MeloTTS",
url="https://huggingface.co/myshell-ai/MeloTTS-English",
),
version="1.0.0",
installed=True,
languages=["en-us"],
),
TtsVoice(
name="melotts-en-br-ax650",
description="MeloTTS English (BR)",
attribution=Attribution(
name="MeloTTS",
url="https://huggingface.co/myshell-ai/MeloTTS-English",
),
version="1.0.0",
installed=True,
languages=["en-br"],
),
TtsVoice(
name="melotts-en-india-ax650",
description="MeloTTS English (India)",
attribution=Attribution(
name="MeloTTS",
url="https://huggingface.co/myshell-ai/MeloTTS-English",
),
version="1.0.0",
installed=True,
languages=["en-in"],
),
TtsVoice(
name="melotts-ja-jp-ax650",
description="MeloTTS Japanese (JP)",
attribution=Attribution(
name="MeloTTS",
url="https://huggingface.co/myshell-ai/MeloTTS-Japanese",
),
version="1.0.0",
installed=True,
languages=["ja-jp"],
),
TtsVoice(
name="melotts-es-es-ax650",
description="MeloTTS Spanish (ES)",
attribution=Attribution(
name="MeloTTS",
url="https://huggingface.co/myshell-ai/MeloTTS-Spanish",
),
version="1.0.0",
installed=True,
languages=["es-es"],
),
TtsVoice(
name="melotts-zh-cn-ax650",
description="MeloTTS Chinese (CN)",
attribution=Attribution(
name="MeloTTS",
url="https://huggingface.co/myshell-ai/MeloTTS-Chinese",
),
version="1.0.0",
installed=True,
languages=["zh-cn"],
),
]
# Map voice name -> model name for automatic switching
VOICE_MODEL_MAP = {voice.name: voice.name for voice in AVAILABLE_VOICES}
class OpenAITTSEventHandler:
"""Event handler for Wyoming protocol with OpenAI TTS."""
def __init__(
self,
api_key: str,
base_url: str,
model: str,
default_voice: str,
response_format: str,
):
"""Initialize the event handler."""
self.api_key = api_key
self.base_url = base_url
self.model = model
self.default_voice = default_voice
self.response_format = response_format
self.voice_model_map = VOICE_MODEL_MAP
# Initialize OpenAI client
self.client = OpenAI(
api_key=api_key,
base_url=base_url,
)
_LOGGER.info(
"Initialized OpenAI TTS handler with base_url=%s, model=%s",
base_url,
model,
)
async def handle_event(self, event: Event) -> Optional[Event]:
"""Handle a Wyoming protocol event."""
if Synthesize.is_type(event.type):
synthesize = Synthesize.from_event(event)
_LOGGER.info("Synthesizing text: %s", synthesize.text)
# Use specified voice or default
voice = synthesize.voice.name if synthesize.voice else self.default_voice
model = self.voice_model_map.get(voice, self.model)
try:
# Generate speech using OpenAI API
audio_data = await asyncio.to_thread(
self._synthesize_speech,
synthesize.text,
voice,
model,
)
# Read WAV file properties
with wave.open(io.BytesIO(audio_data), "rb") as wav_file:
sample_rate = wav_file.getframerate()
sample_width = wav_file.getsampwidth()
channels = wav_file.getnchannels()
audio_bytes = wav_file.readframes(wav_file.getnframes())
_LOGGER.info(
"Generated audio: %d bytes, %d Hz, %d channels",
len(audio_bytes),
sample_rate,
channels,
)
# Send audio start event
yield AudioStart(
rate=sample_rate,
width=sample_width,
channels=channels,
).event()
# Send audio in chunks
chunk_size = 8192
for i in range(0, len(audio_bytes), chunk_size):
chunk = audio_bytes[i:i + chunk_size]
yield AudioChunk(
audio=chunk,
rate=sample_rate,
width=sample_width,
channels=channels,
).event()
# Send audio stop event
yield AudioStop().event()
except Exception as err:
_LOGGER.exception("Error during synthesis: %s", err)
raise
def _synthesize_speech(self, text: str, voice: str, model: str) -> bytes:
"""Synthesize speech using OpenAI API (blocking call)."""
with self.client.audio.speech.with_streaming_response.create(
model=model,
voice=voice,
response_format=self.response_format,
input=text,
) as response:
# Read all audio data
audio_data = b""
for chunk in response.iter_bytes(chunk_size=8192):
audio_data += chunk
return audio_data
async def main():
"""Run the Wyoming protocol server."""
parser = argparse.ArgumentParser(description="Wyoming OpenAI TTS Server")
parser.add_argument(
"--uri",
default=f"tcp://{DEFAULT_HOST}:{DEFAULT_PORT}",
help="URI to bind the server (default: tcp://0.0.0.0:10200)",
)
parser.add_argument(
"--api-key",
default="sk-your-key",
help="OpenAI API key (default: sk-your-key)",
)
parser.add_argument(
"--base-url",
default=DEFAULT_API_BASE_URL,
help=f"OpenAI API base URL (default: {DEFAULT_API_BASE_URL})",
)
parser.add_argument(
"--model",
default=DEFAULT_MODEL,
help=f"TTS model name (default: {DEFAULT_MODEL})",
)
parser.add_argument(
"--voice",
default=DEFAULT_VOICE,
help=f"Default voice name (default: {DEFAULT_VOICE})",
)
parser.add_argument(
"--response-format",
default=DEFAULT_RESPONSE_FORMAT,
choices=["mp3", "opus", "aac", "flac", "wav", "pcm"],
help=f"Audio response format (default: {DEFAULT_RESPONSE_FORMAT})",
)
parser.add_argument(
"--debug",
action="store_true",
help="Enable debug logging",
)
args = parser.parse_args()
# Setup logging
logging.basicConfig(
level=logging.DEBUG if args.debug else logging.INFO,
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
)
_LOGGER.info("Starting Wyoming OpenAI TTS Server")
_LOGGER.info("URI: %s", args.uri)
_LOGGER.info("Model: %s", args.model)
_LOGGER.info("Default voice: %s", args.voice)
# Create Wyoming info
wyoming_info = Info(
tts=[
TtsProgram(
name="MeloTTS",
description="OpenAI compatible TTS service",
attribution=Attribution(
name="MeloTTS",
url="https://huggingface.co/myshell-ai/MeloTTS-English",
),
version="1.0.0",
installed=True,
voices=AVAILABLE_VOICES,
)
],
)
# Create event handler
event_handler = OpenAITTSEventHandler(
api_key=args.api_key,
base_url=args.base_url,
model=args.model,
default_voice=args.voice,
response_format=args.response_format,
)
# Start server
server = AsyncServer.from_uri(args.uri)
_LOGGER.info("Server started, waiting for connections...")
await server.run(
partial(
OpenAITtsHandler,
wyoming_info=wyoming_info,
event_handler=event_handler,
)
)
class OpenAITtsHandler(AsyncEventHandler):
"""Wyoming async event handler for OpenAI TTS."""
def __init__(
self,
reader: asyncio.StreamReader,
writer: asyncio.StreamWriter,
wyoming_info: Info,
event_handler: OpenAITTSEventHandler,
) -> None:
super().__init__(reader, writer)
self._wyoming_info = wyoming_info
self._event_handler = event_handler
self._sent_info = False
async def handle_event(self, event: Event) -> bool:
if not self._sent_info:
await self.write_event(self._wyoming_info.event())
self._sent_info = True
_LOGGER.info("Client connected")
_LOGGER.debug("Received event: %s", event.type)
try:
async for response_event in self._event_handler.handle_event(event):
await self.write_event(response_event)
except Exception as err:
_LOGGER.exception("Error handling connection: %s", err)
return False
return True
async def disconnect(self) -> None:
_LOGGER.info("Client disconnected")
if __name__ == "__main__":
from functools import partial
asyncio.run(main())ステップ 3:テキスト音声変換サービスの起動
以下のコマンドで Wyoming テキスト音声変換サービスを起動します。AI Pyramid の IP アドレスに置き換えてください。
python wyoming_openai_tts.py --base-url=http://192.168.20.138:8000/v1root@m5stack-AI-Pyramid:~/wyoming-openai-tts# python wyoming_openai_tts.py --base_url=http://192.168.20.138:8000/v1
2026-02-04 17:03:18,152 - __main__ - INFO - Starting Wyoming OpenAI TTS Server
2026-02-04 17:03:18,153 - __main__ - INFO - URI: tcp://0.0.0.0:10200
2026-02-04 17:03:18,153 - __main__ - INFO - Model: melotts-zh-cn-ax650
2026-02-04 17:03:18,153 - __main__ - INFO - Default voice: melotts-zh-cn-ax650
2026-02-04 17:03:19,081 - __main__ - INFO - Initialized OpenAI TTS handler with base_url=http://192.168.20.138:8000/v1, model=melotts-zh-cn-ax650
2026-02-04 17:03:19,082 - __main__ - INFO - Server started, waiting for connections...ステップ 4:Home Assistant への Wyoming Protocol の追加
Home Assistant の設定を開き、「Wyoming Protocol」インテグレーションを検索して追加します。
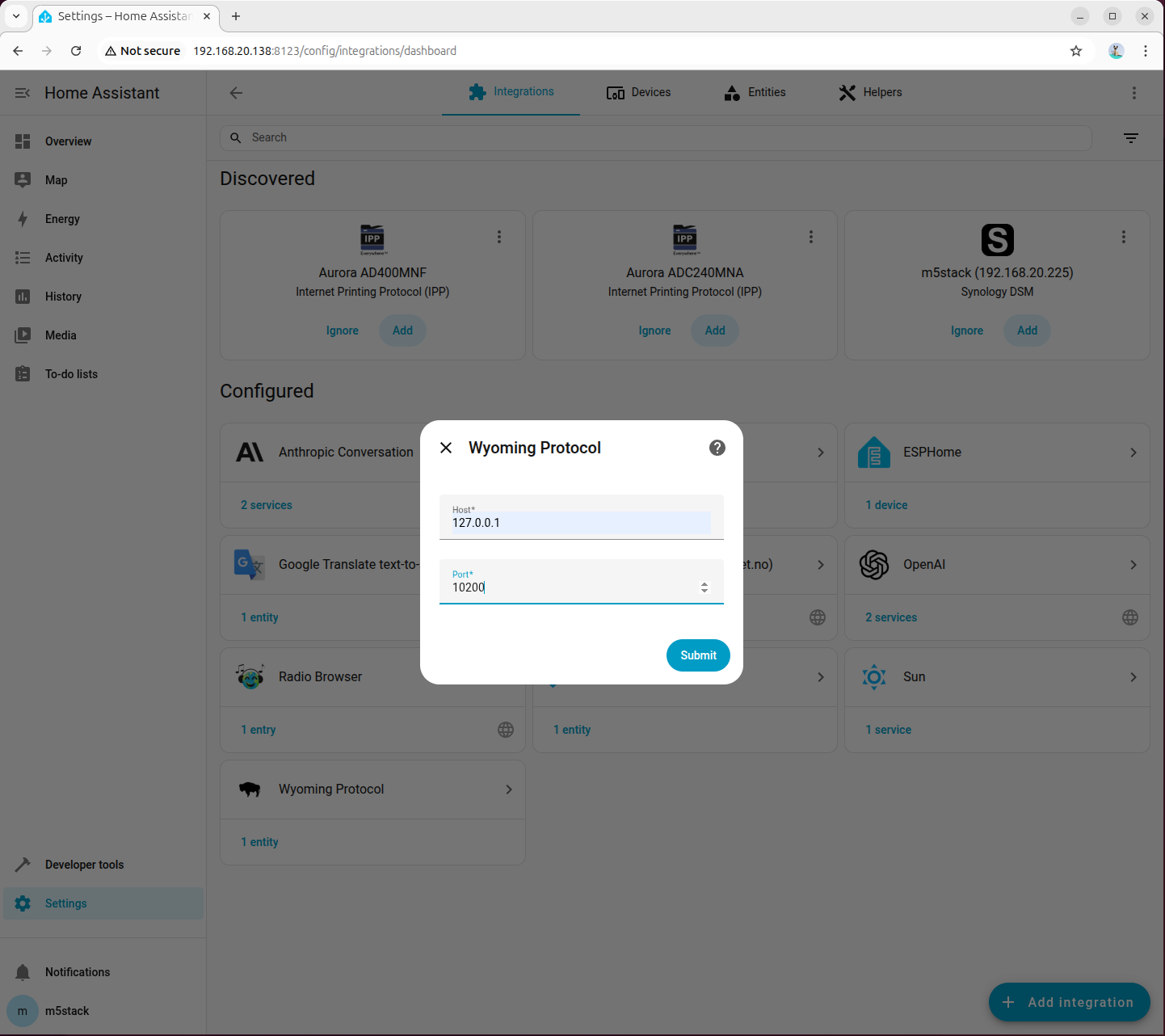
ステップ 5:音声アシスタントの設定
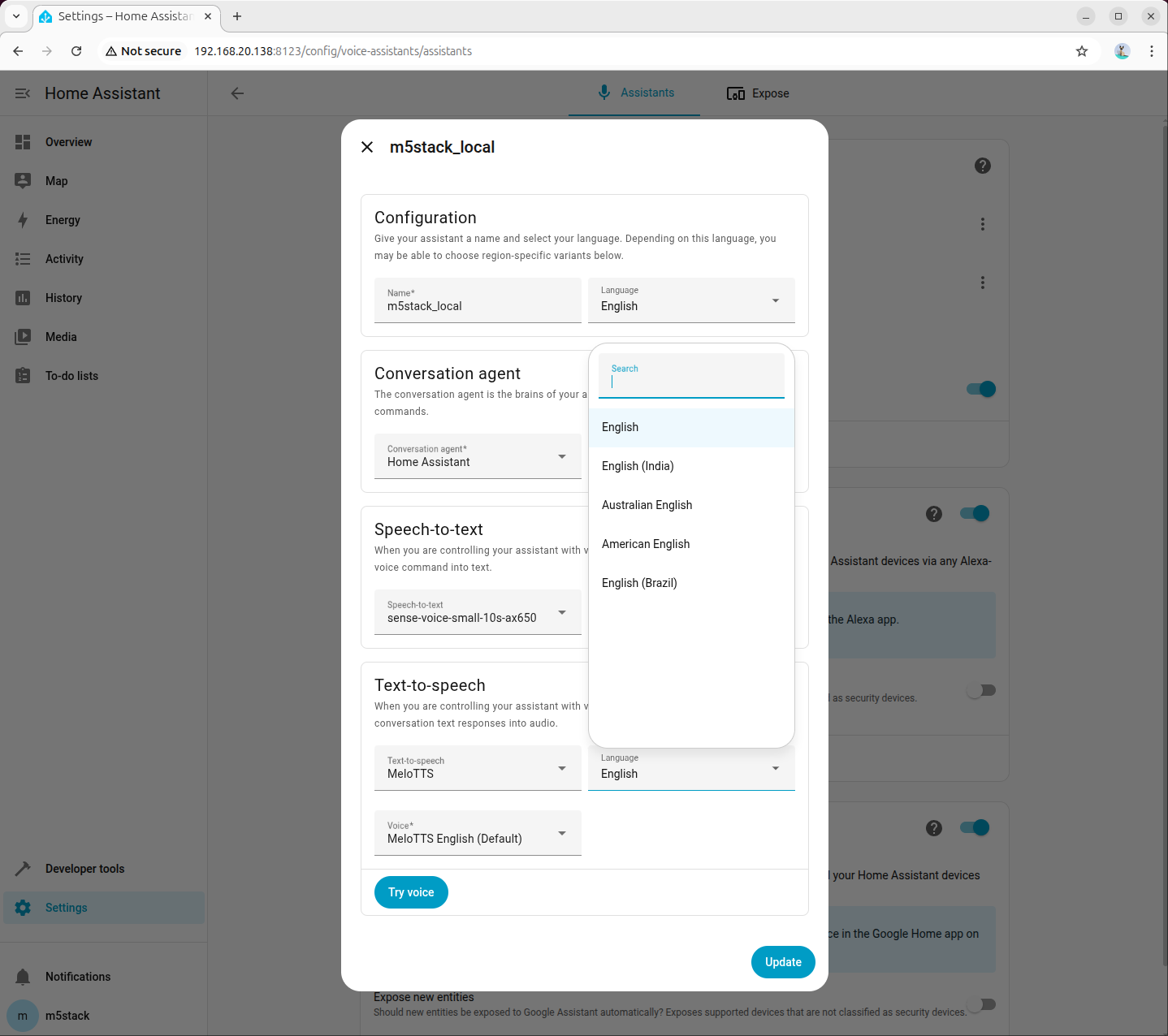
「設定 - 音声アシスタント」でアシスタント設定を作成または編集します。テキスト音声変換(TTS)のオプションを先ほど追加した「MeloTTS」に設定し、必要に応じて言語と音声を選択してください。対応する言語のテキスト音声変換モデルがインストールされていることを確認してください。ここでは American English を例に説明します。
7. HACS の設定
- homeassistant コンテナに入ります。
docker exec -it homeassistant bash- HACS をインストールします。
wget -O - https://get.hacs.xyz | bash -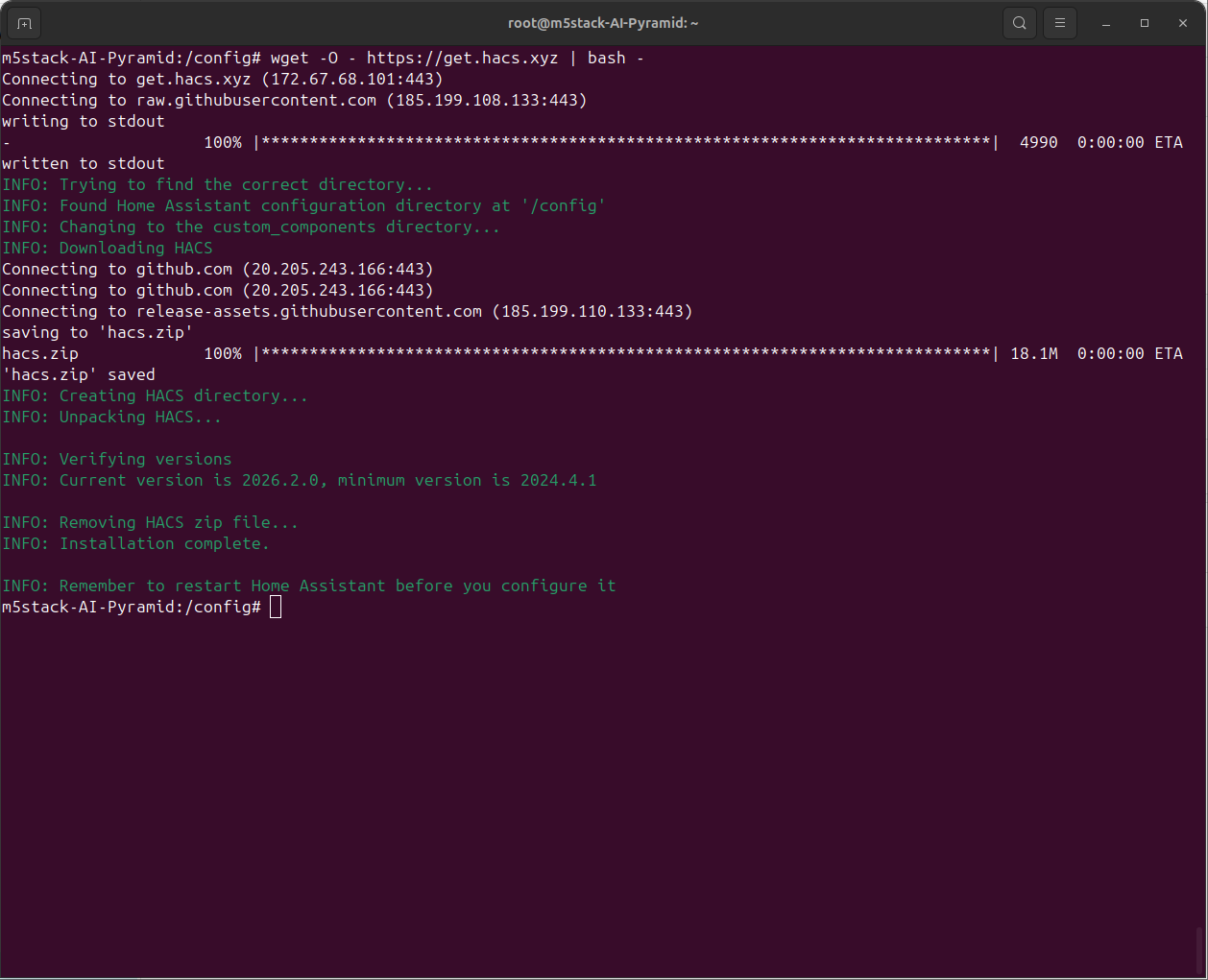
- Ctrl + D でコンテナを抜け、homeassistant コンテナを再起動します。
docker restart homeassistant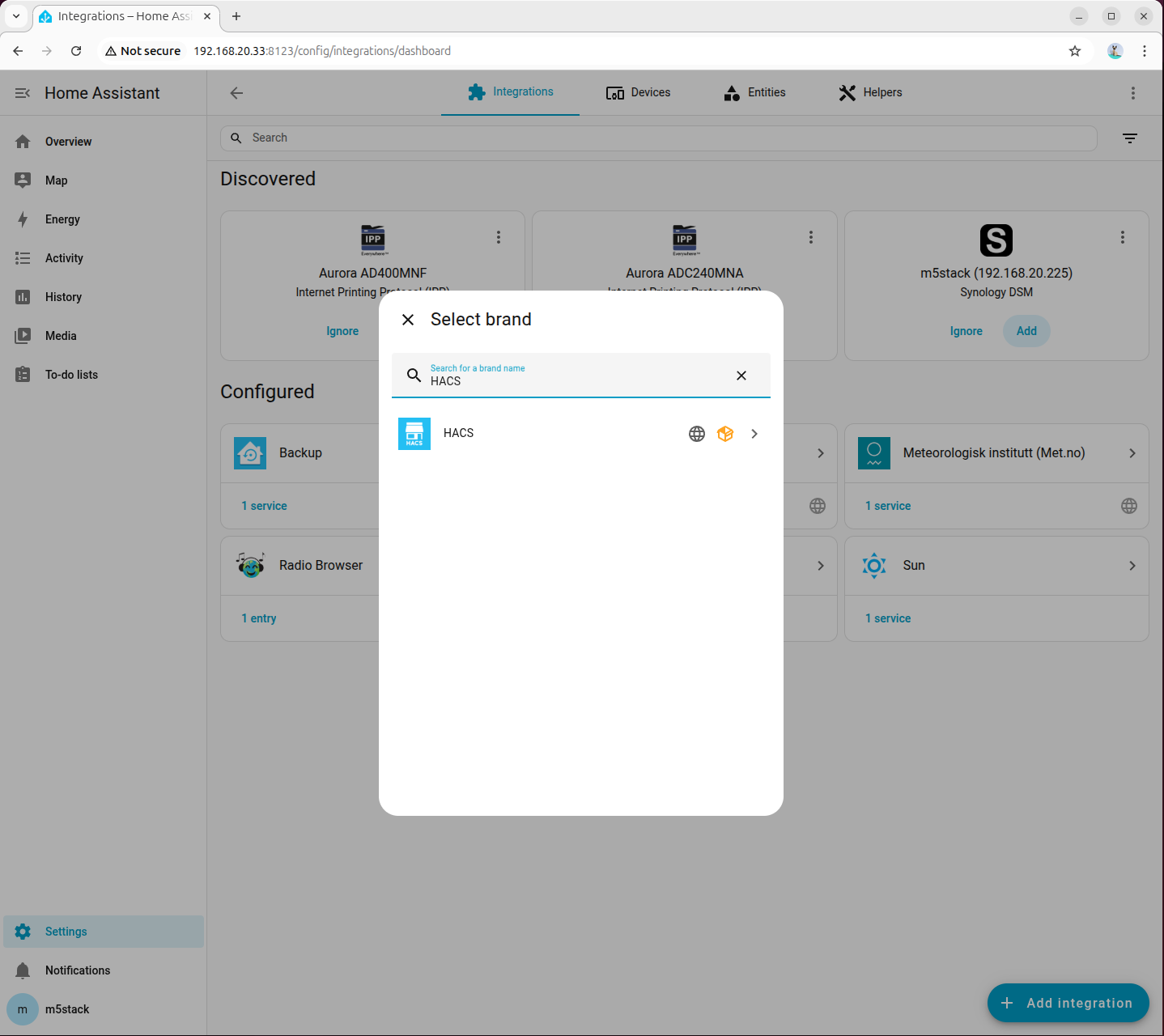
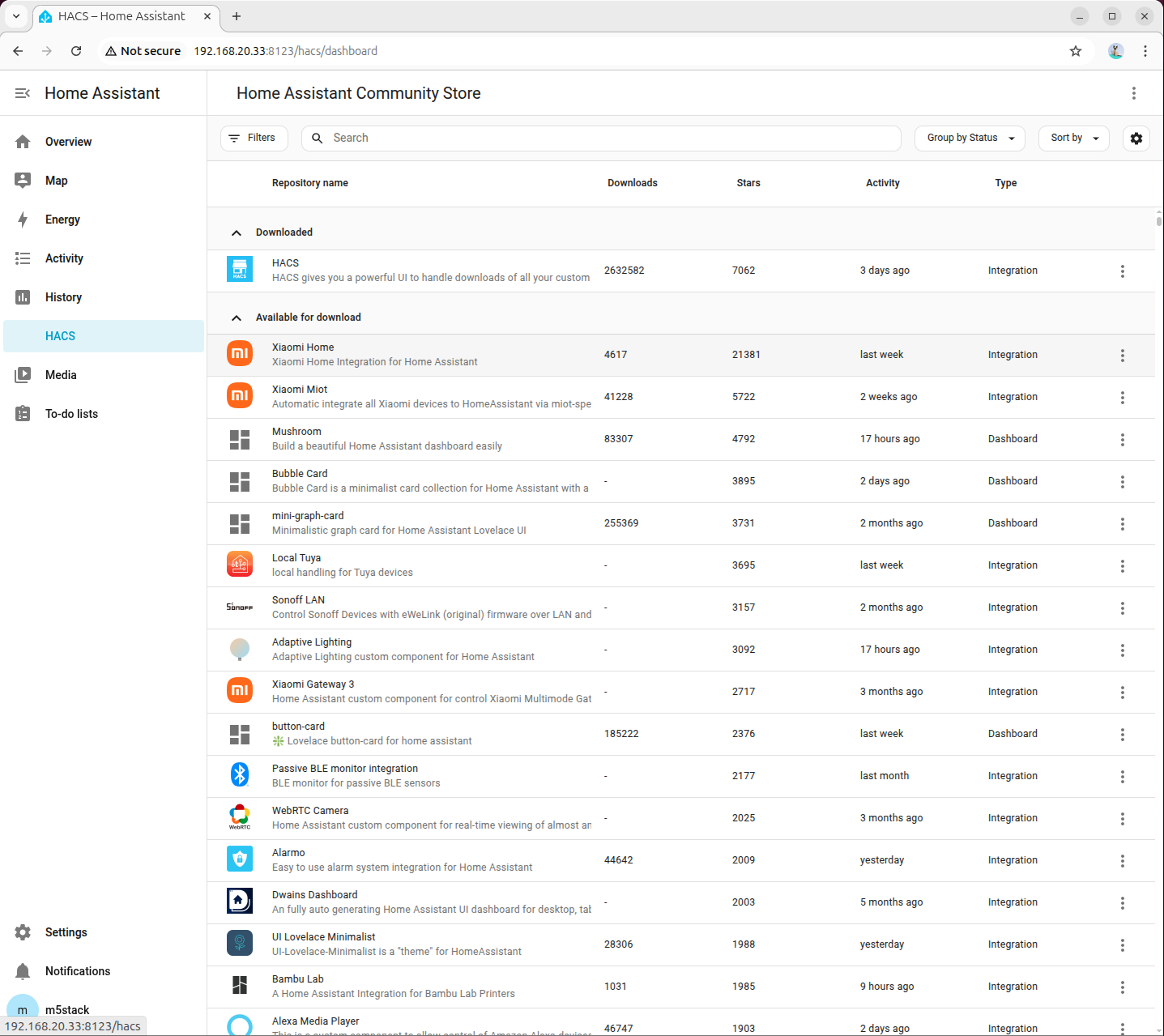
- 設定 → デバイスとサービス → インテグレーションの追加 から HACS を検索します。
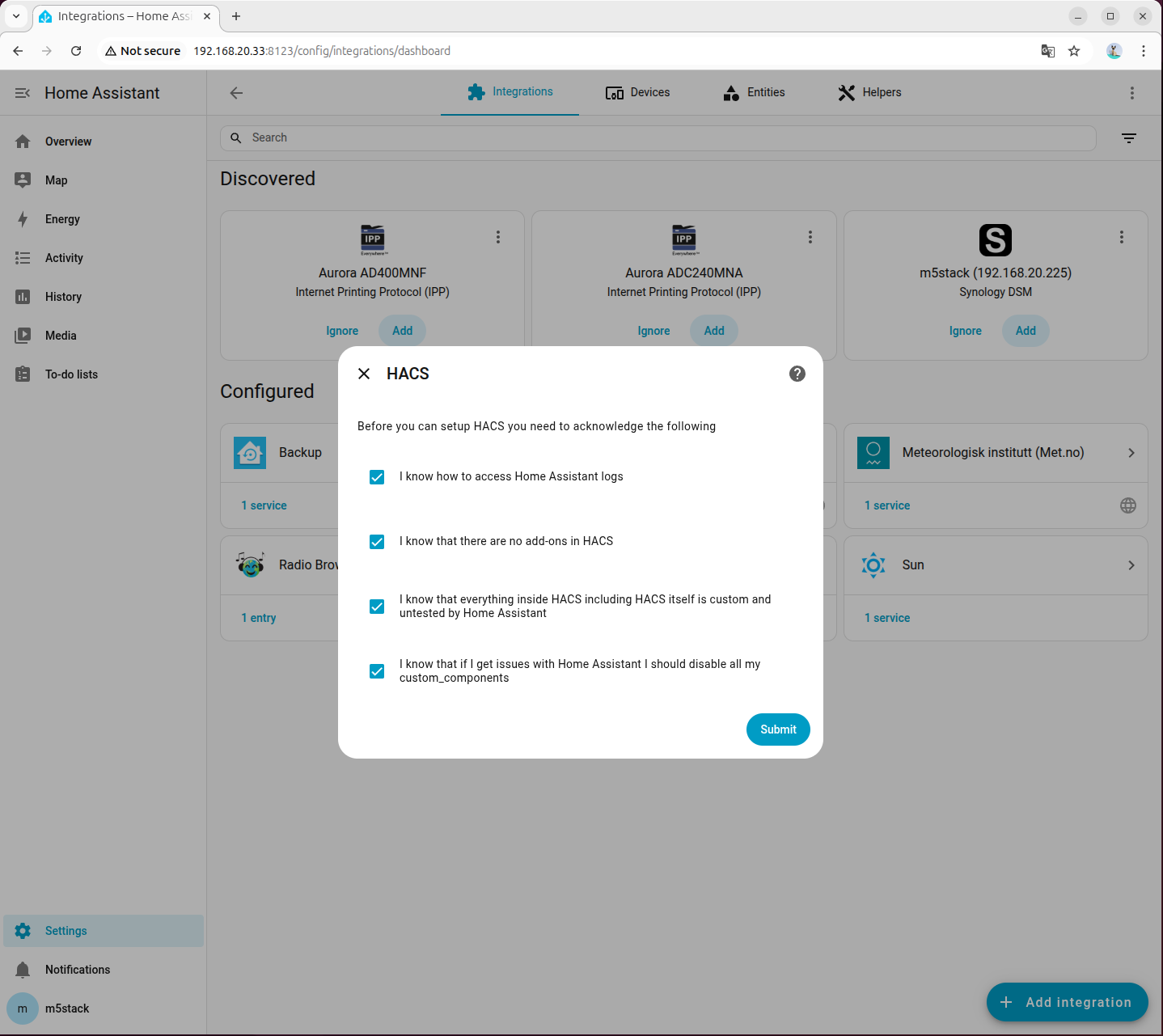
- すべての項目にチェックを入れます。
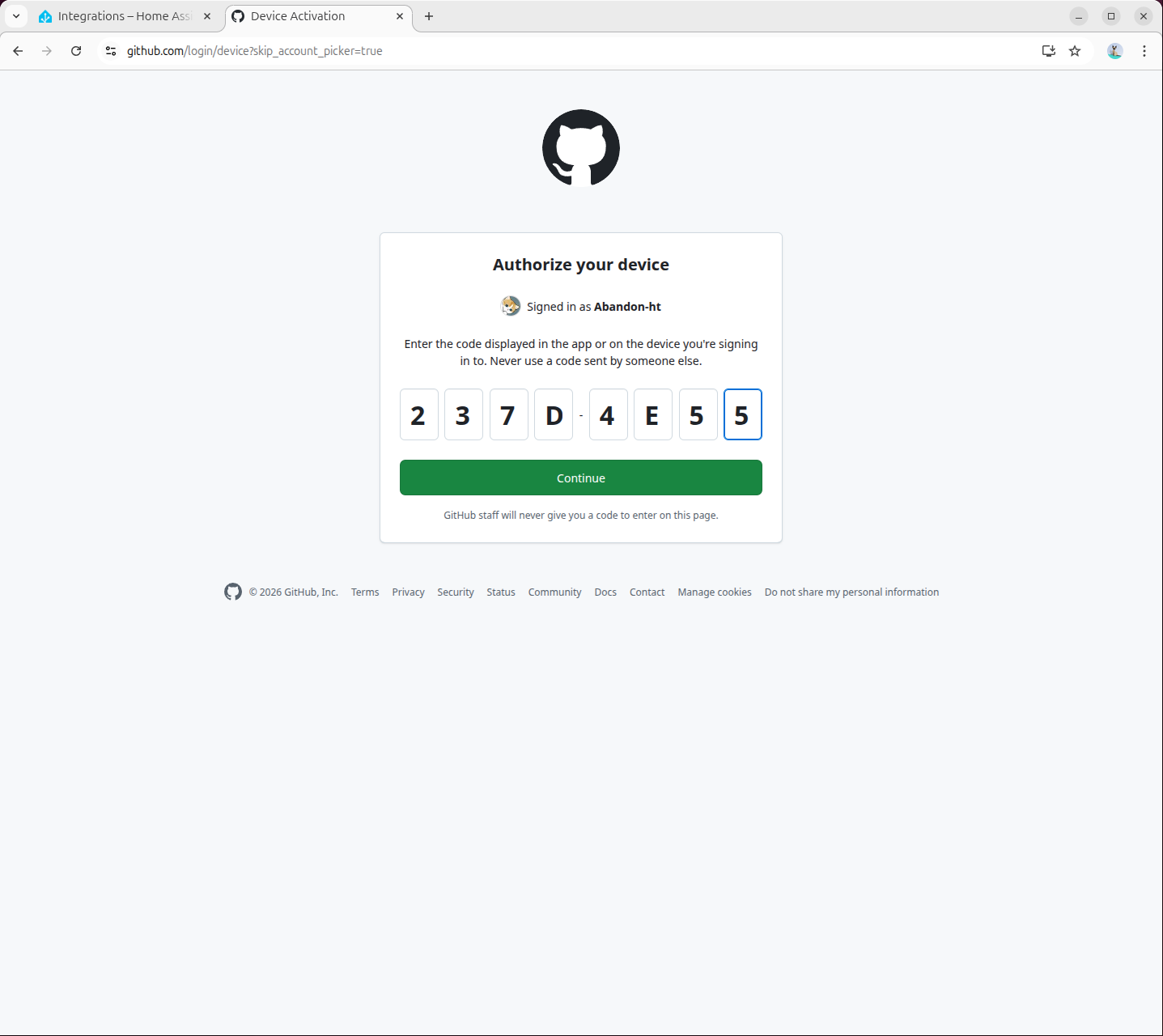
- 認証を完了します。
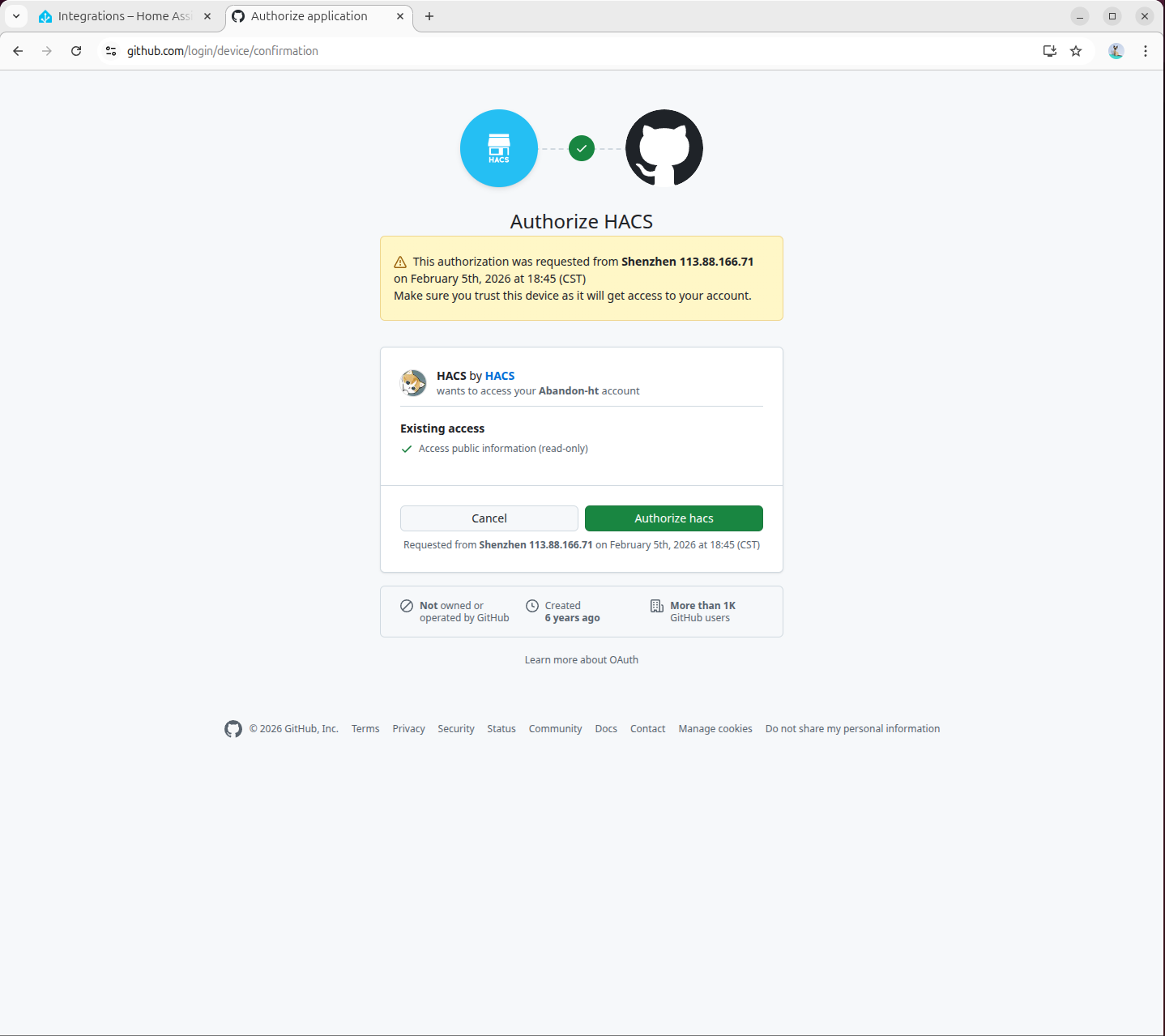
8. Local LLM Conversation の設定
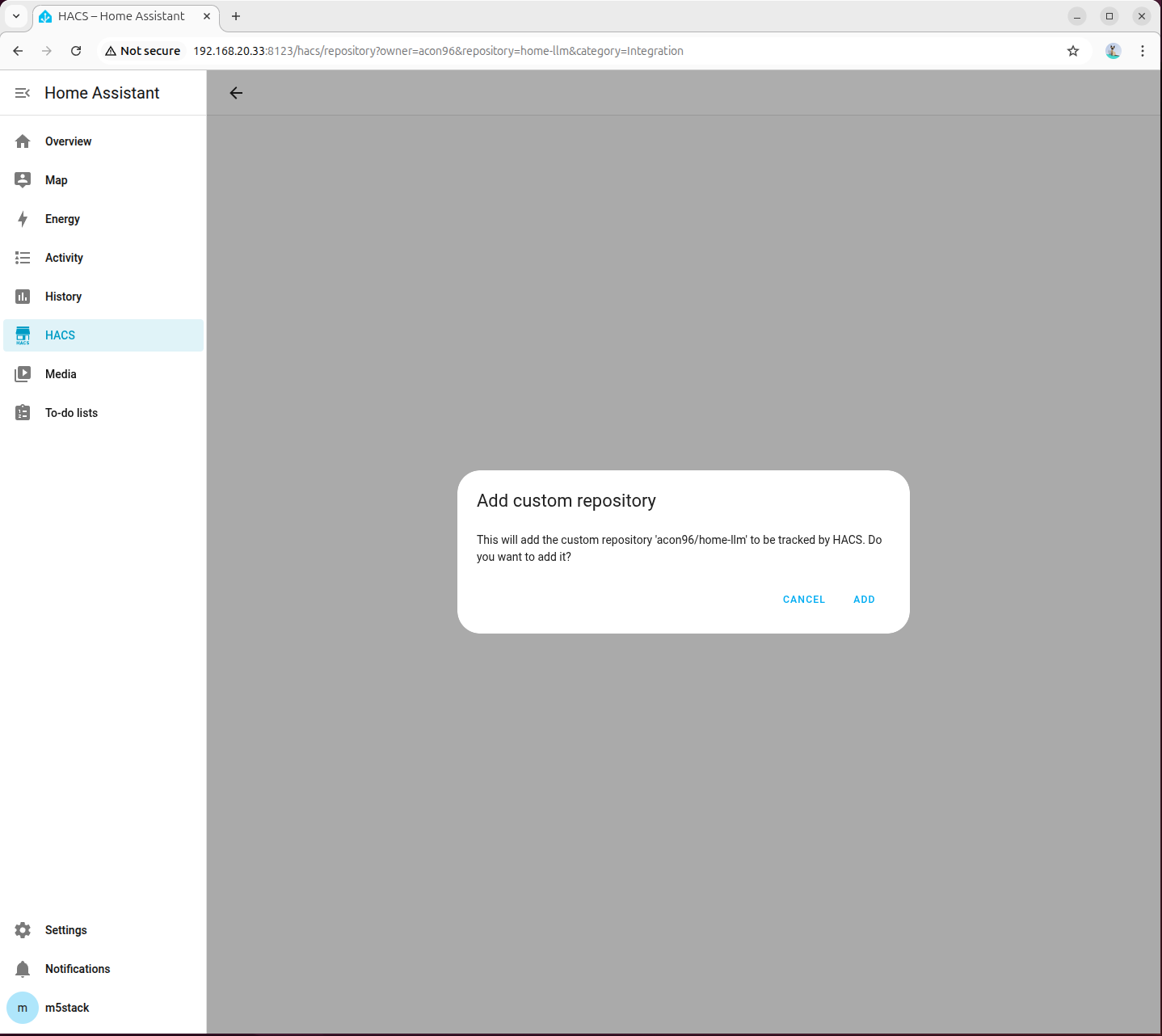
- http://192.168.20.33:8123/hacs/repository?owner=acon96&repository=home-llm&category=Integration にアクセスしてプラグインを追加します。
- 右下のダウンロードボタンをクリックします。
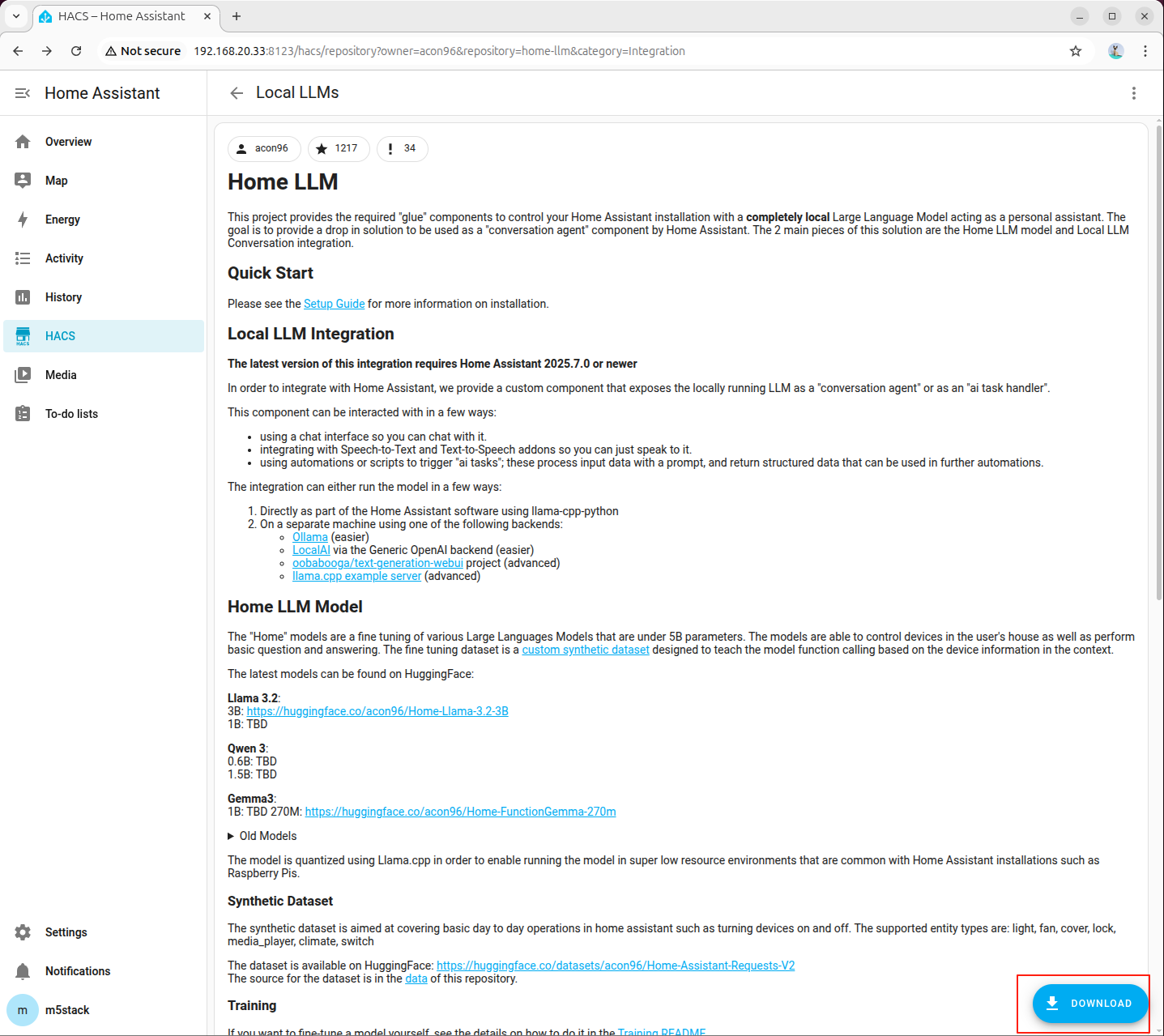
- バージョンは最新版を選択します。
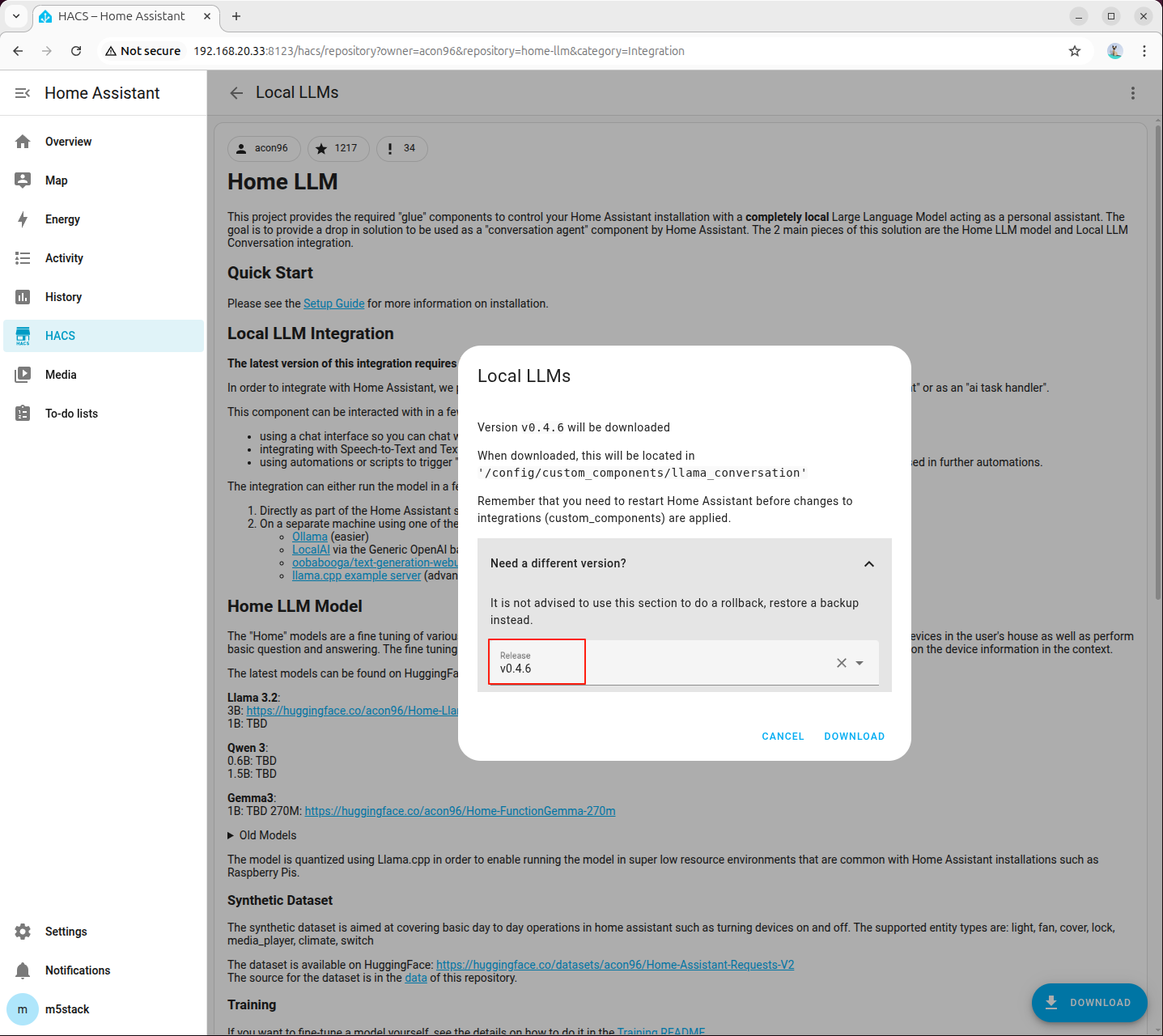
- Home Assistant を再起動します。
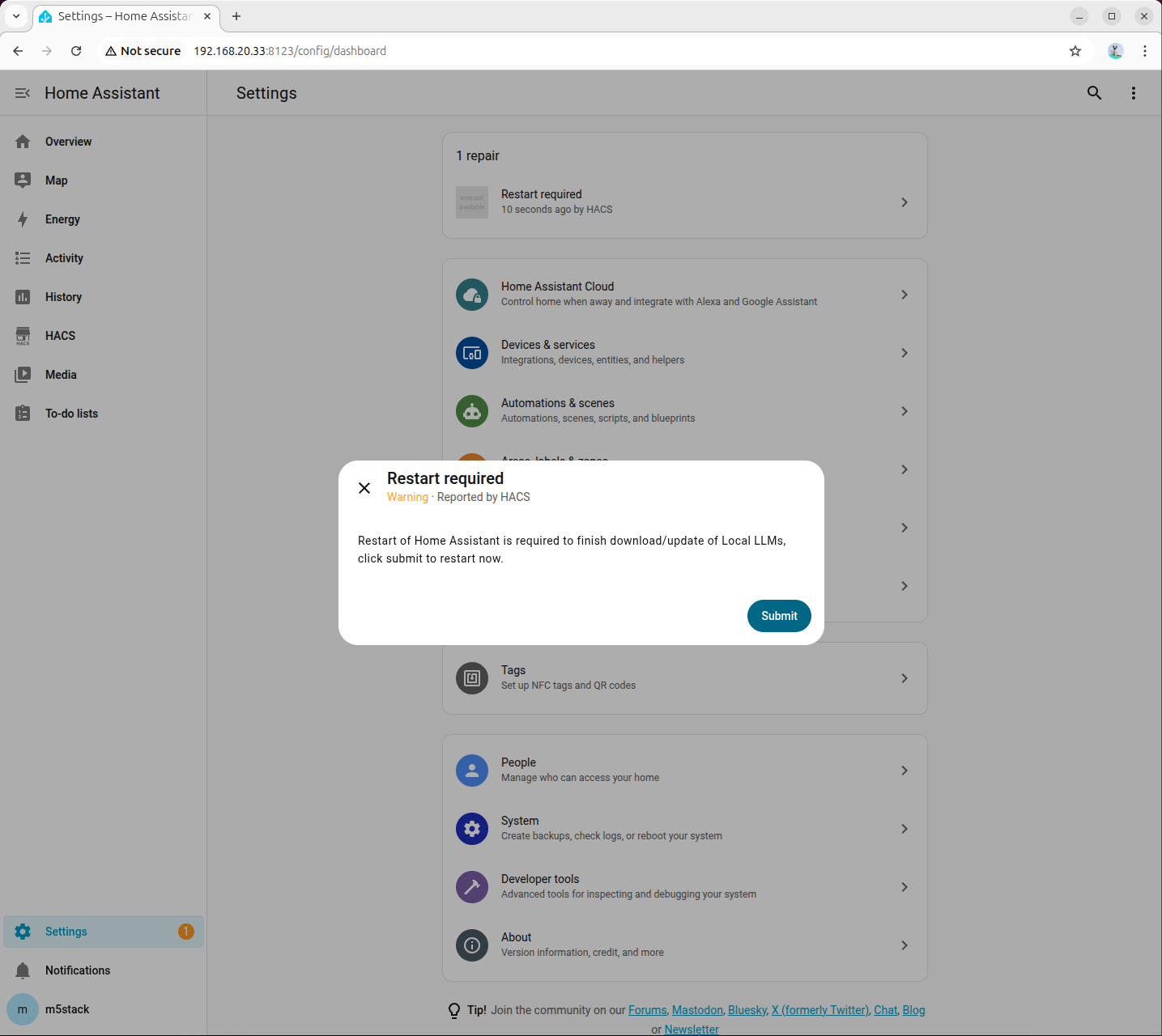
- 設定 → インテグレーションの追加 から Local LLMs を検索して追加します。
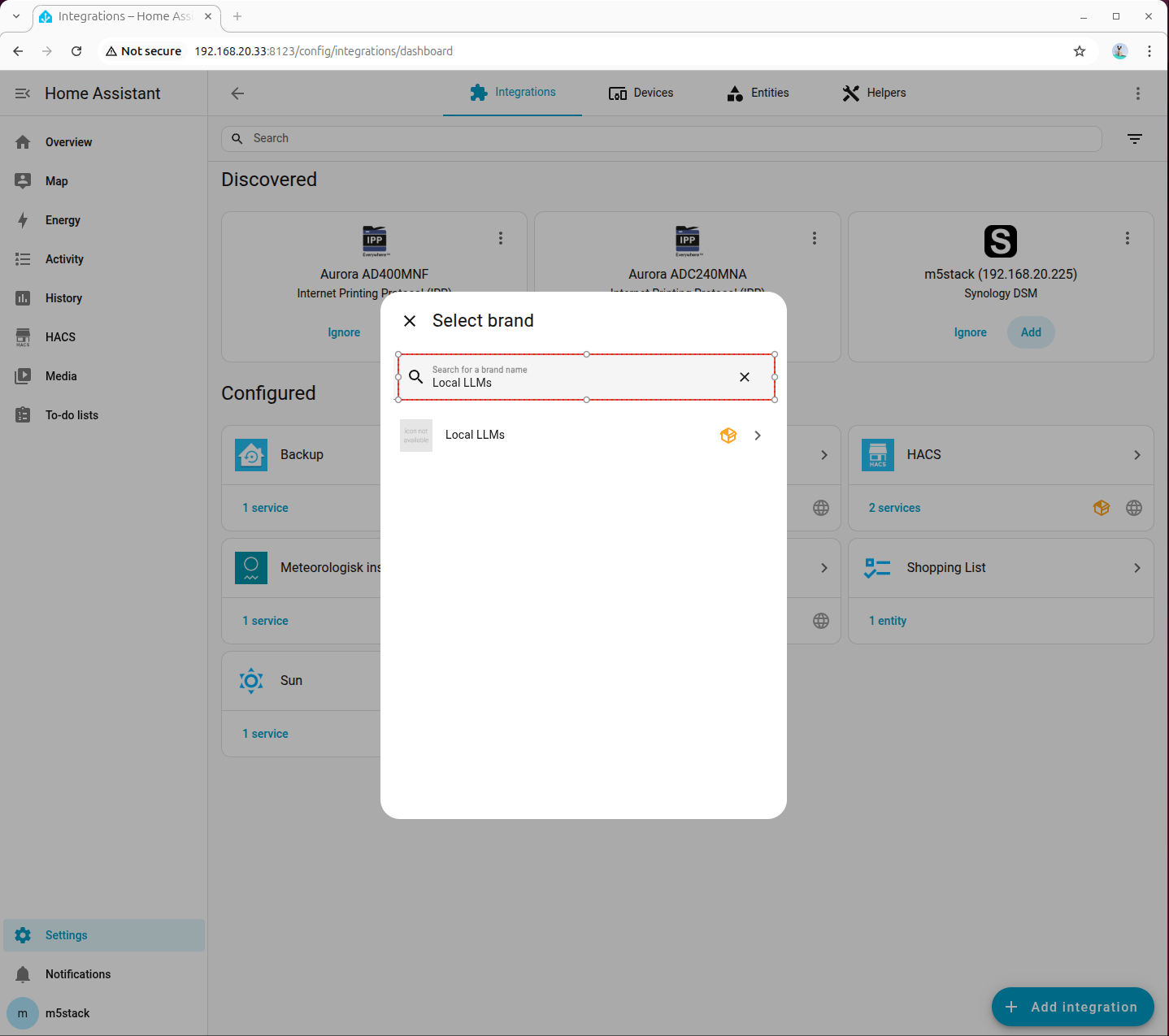
OpenAI Compatible API インテグレーションの設定
- ローカル LLM-HA サービスの設定
ステップ 1:依存パッケージとモデルのインストール
音声認識に必要な依存パッケージとモデルがシステムにインストールされていることを確認してください。
apt install lib-llm llm-sys llm-asr llm-openai-api llm-model-qwen2.5-ha-0.5b-ctx-ax650pip install fastapi httpx uvicornステップ 2:ローカル LLM-HA サービスの作成
AI Pyramid で新しいファイル ha_llm_proxy.py を作成し、以下のコードをコピーしてください。
#!/usr/bin/env python3
# SPDX-FileCopyrightText: 2026 M5Stack Technology CO LTD
#
# SPDX-License-Identifier: MIT
import time
import json
import uuid
import httpx
from fastapi import FastAPI, Request
from fastapi.responses import StreamingResponse, JSONResponse
UPSTREAM_URL = "http://127.0.0.1:8000/v1/chat/completions"
MODEL_NAME = "qwen2.5-HA-0.5B-ctx-ax650"
app = FastAPI()
def fake_stream_from_content(content: str):
response_id = f"chatcmpl-{uuid.uuid4().hex}"
created = int(time.time())
for chunk in content.splitlines(keepends=True):
data = {
"id": response_id,
"object": "chat.completion.chunk",
"created": created,
"model": MODEL_NAME,
"choices": [{
"index": 0,
"delta": {"content": chunk},
"finish_reason": None
}]
}
yield f"data: {json.dumps(data, ensure_ascii=False)}\n\n"
time.sleep(0.05)
end_data = {
"id": response_id,
"object": "chat.completion.chunk",
"created": created,
"model": MODEL_NAME,
"choices": [{
"index": 0,
"delta": {},
"finish_reason": "stop"
}]
}
yield f"data: {json.dumps(end_data)}\n\n"
yield "data: [DONE]\n\n"
@app.get("/v1/models")
async def list_models():
return {
"object": "list",
"data": [{
"id": MODEL_NAME,
"object": "model",
"created": 0,
"owned_by": "proxy",
"permission": [],
"root": MODEL_NAME
}]
}
@app.post("/v1/chat/completions")
async def chat_completions(request: Request):
body = await request.json()
want_stream = body.get("stream", False)
body["stream"] = False
async with httpx.AsyncClient(timeout=None) as client:
resp = await client.post(UPSTREAM_URL, json=body)
resp.raise_for_status()
upstream = resp.json()
content = upstream["choices"][0]["message"]["content"]
if want_stream:
return StreamingResponse(
fake_stream_from_content(content),
media_type="text/event-stream"
)
return JSONResponse({
"id": f"chatcmpl-{uuid.uuid4().hex}",
"object": "chat.completion",
"created": int(time.time()),
"model": MODEL_NAME,
"choices": [{
"index": 0,
"message": {"role": "assistant", "content": content},
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 0,
"completion_tokens": 0,
"total_tokens": 0
}
})
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8100)ステップ 3:テキスト音声変換サービスの起動
以下のコマンドでローカル LLM-HA サービスを起動します。
python ha_llm_proxy.pyroot@m5stack-AI-Pyramid:~# python ha_llm_proxy.py
INFO: Started server process [19840]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8100 (Press CTRL+C to quit)- Local LLMs の追加画面で、バックエンドとして OpenAI Compatible 'Conversations' API を選択し、モデル言語はデフォルトで English を選択します。
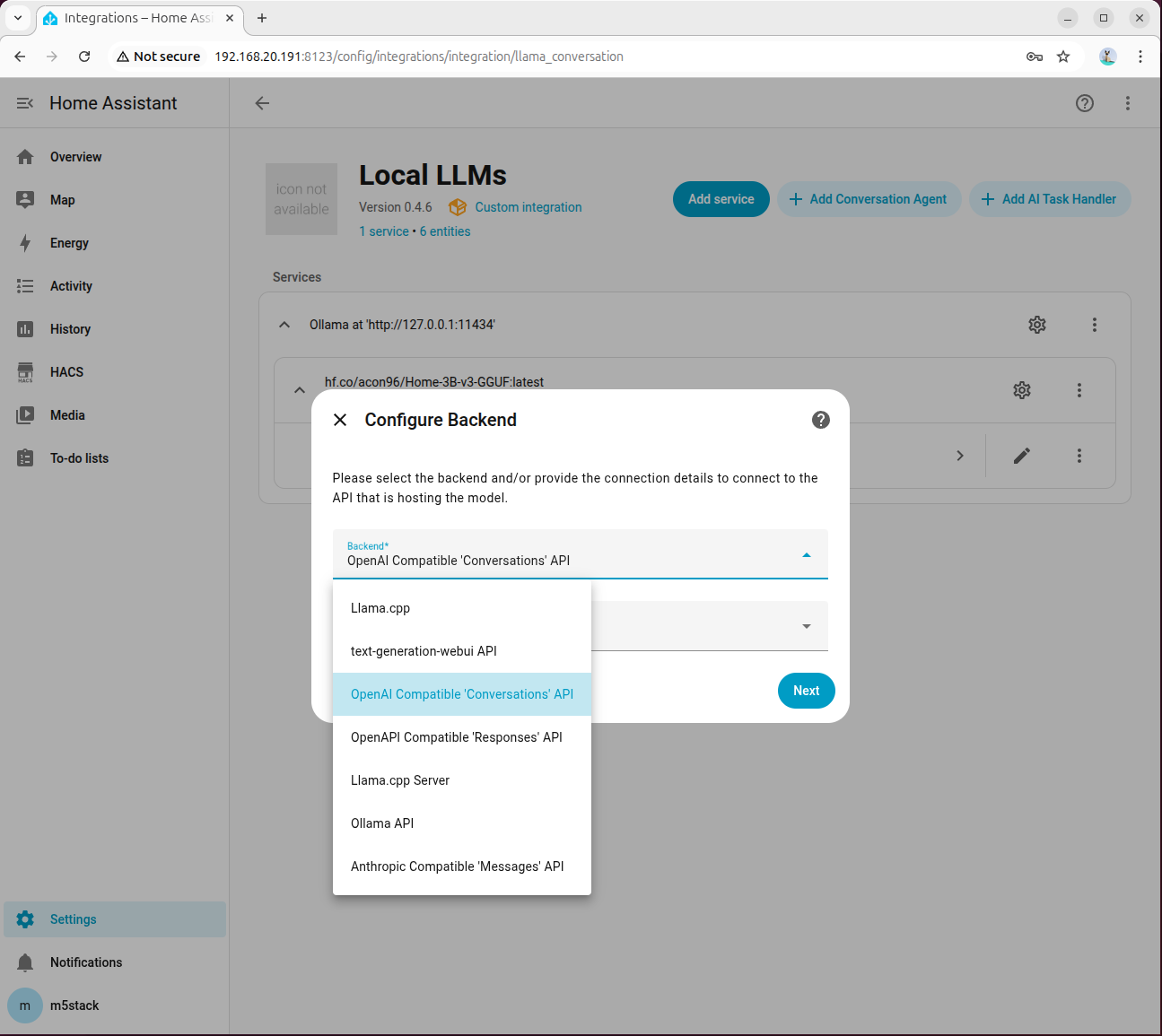
- API Hostname に 127.0.0.1、ポートに 8100 を入力します。
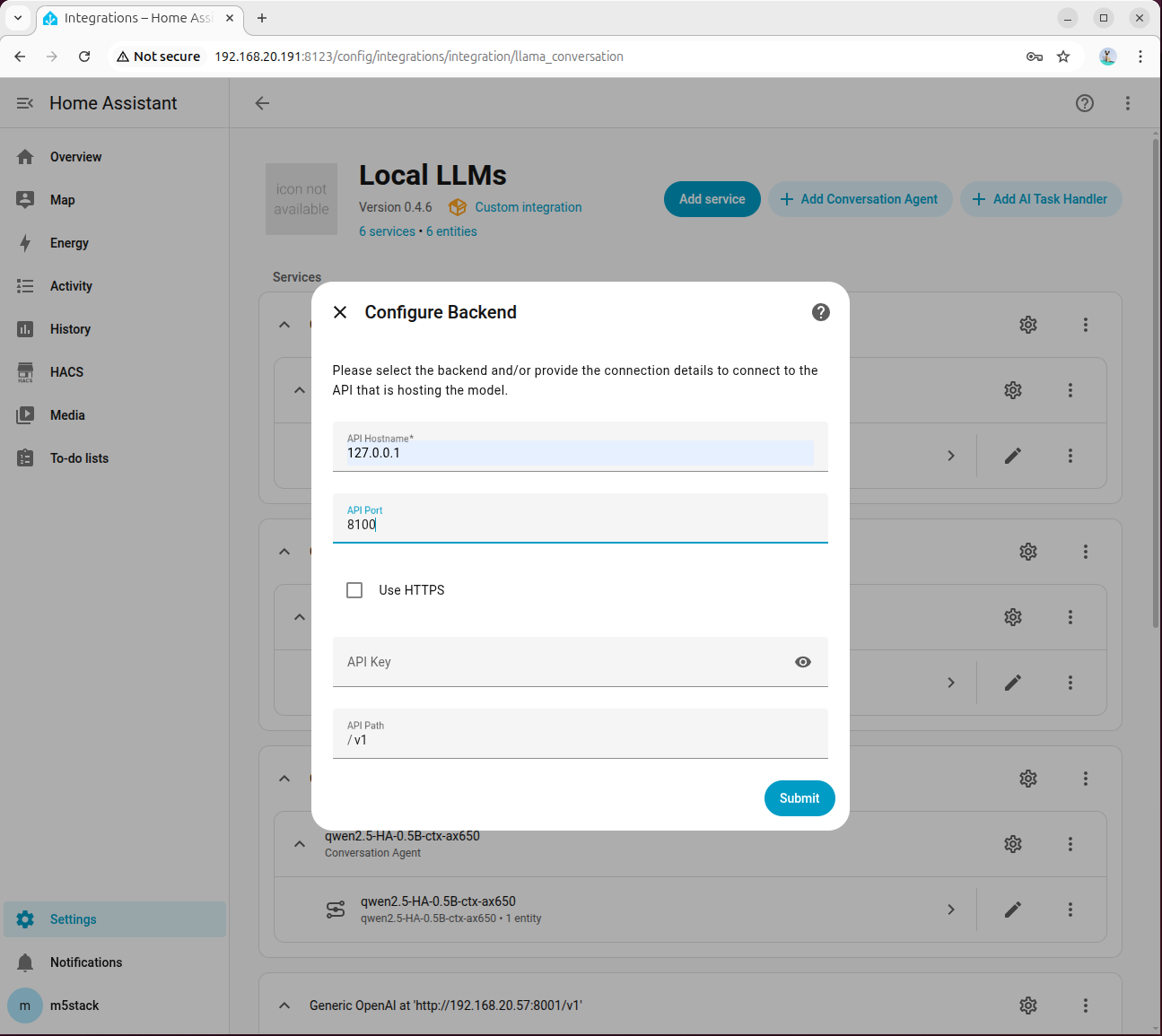
- エージェントの追加画面で HA 専用のモデルを選択します。
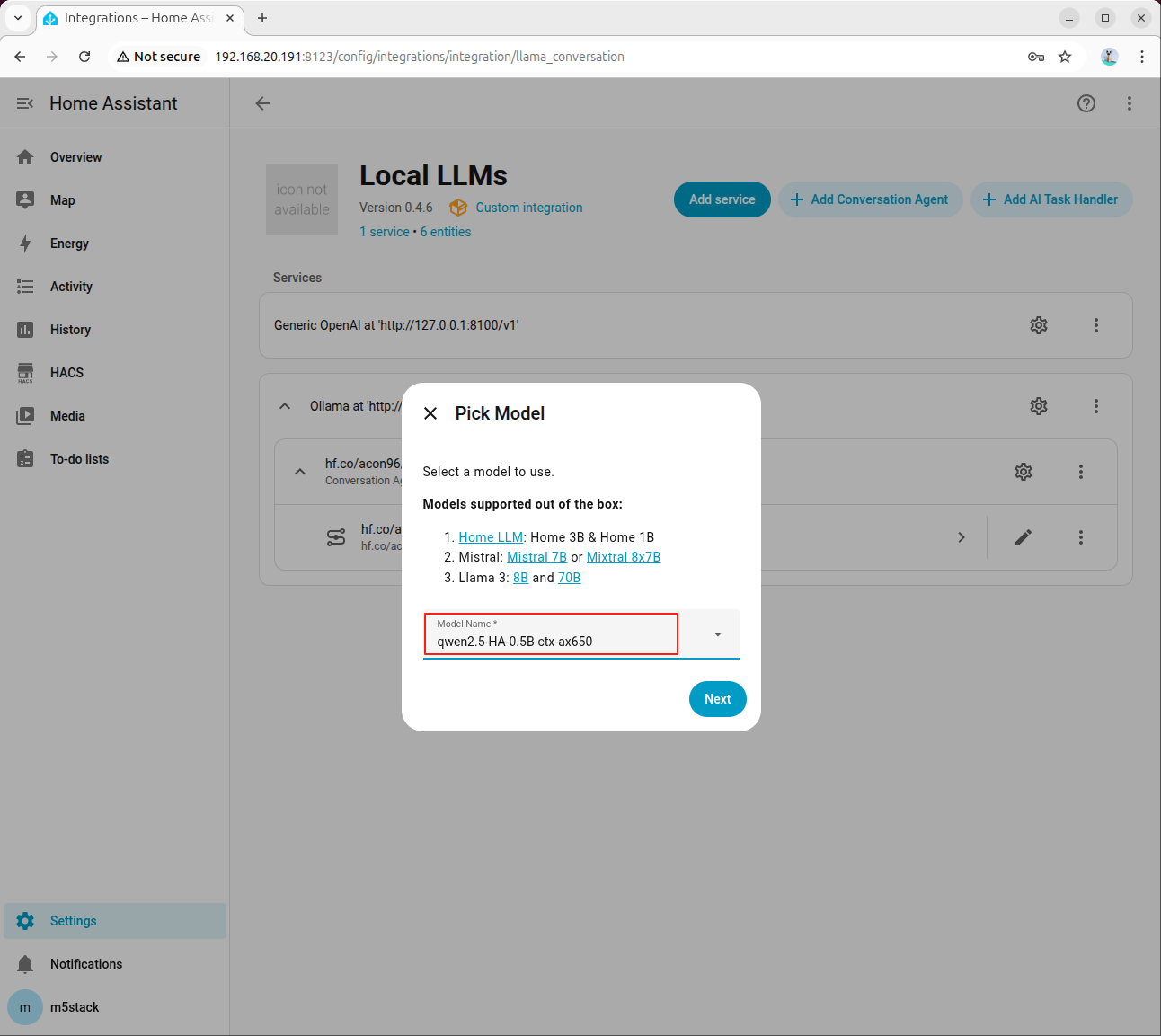
- Home Assistant Services にチェックを入れます。
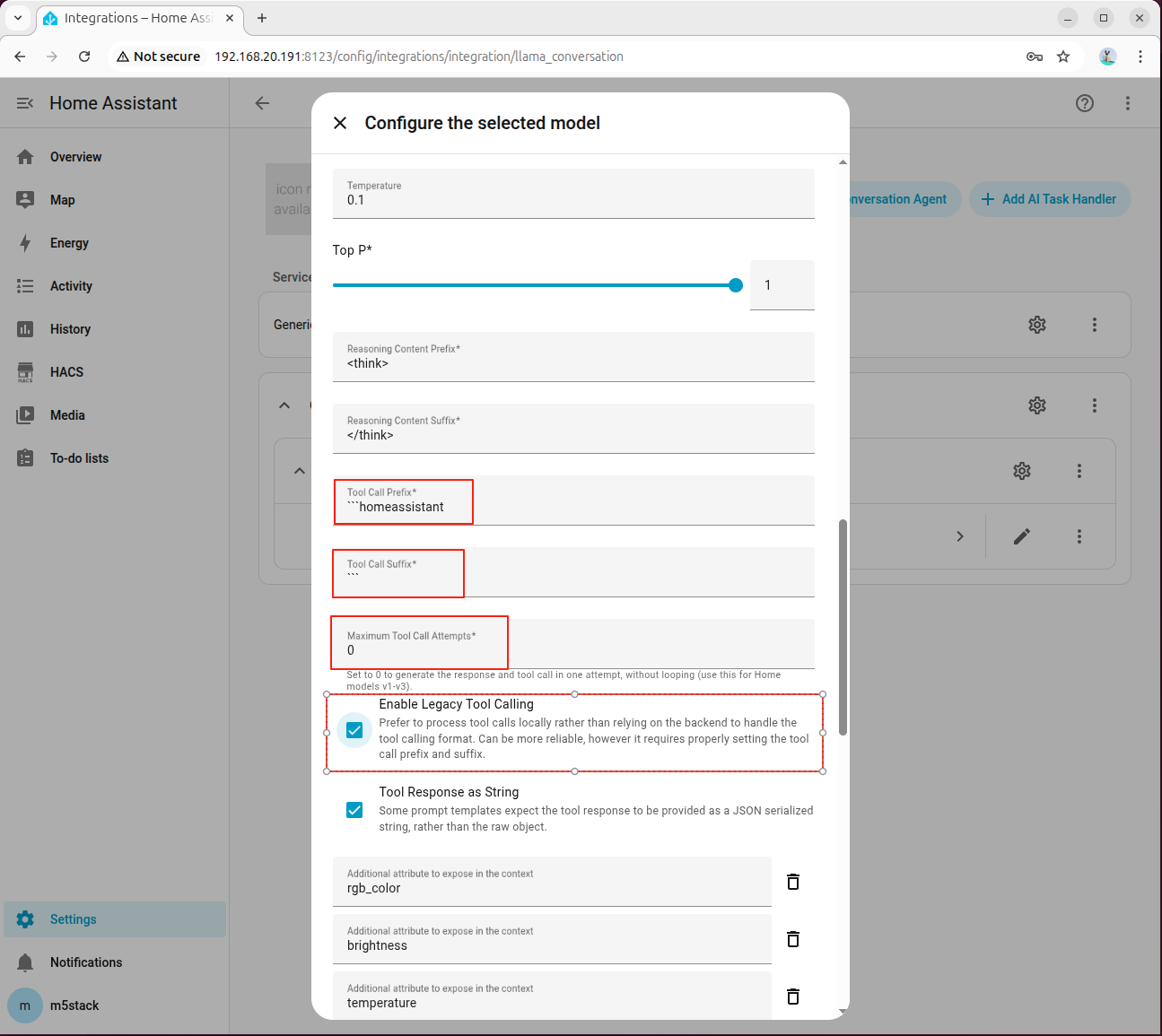
- Tool Call Prefix、Tool Call Suffix、Maximum Tool Call Attempts の設定に注意し、Enable Legacy Tool Calling に必ずチェックを入れてください。
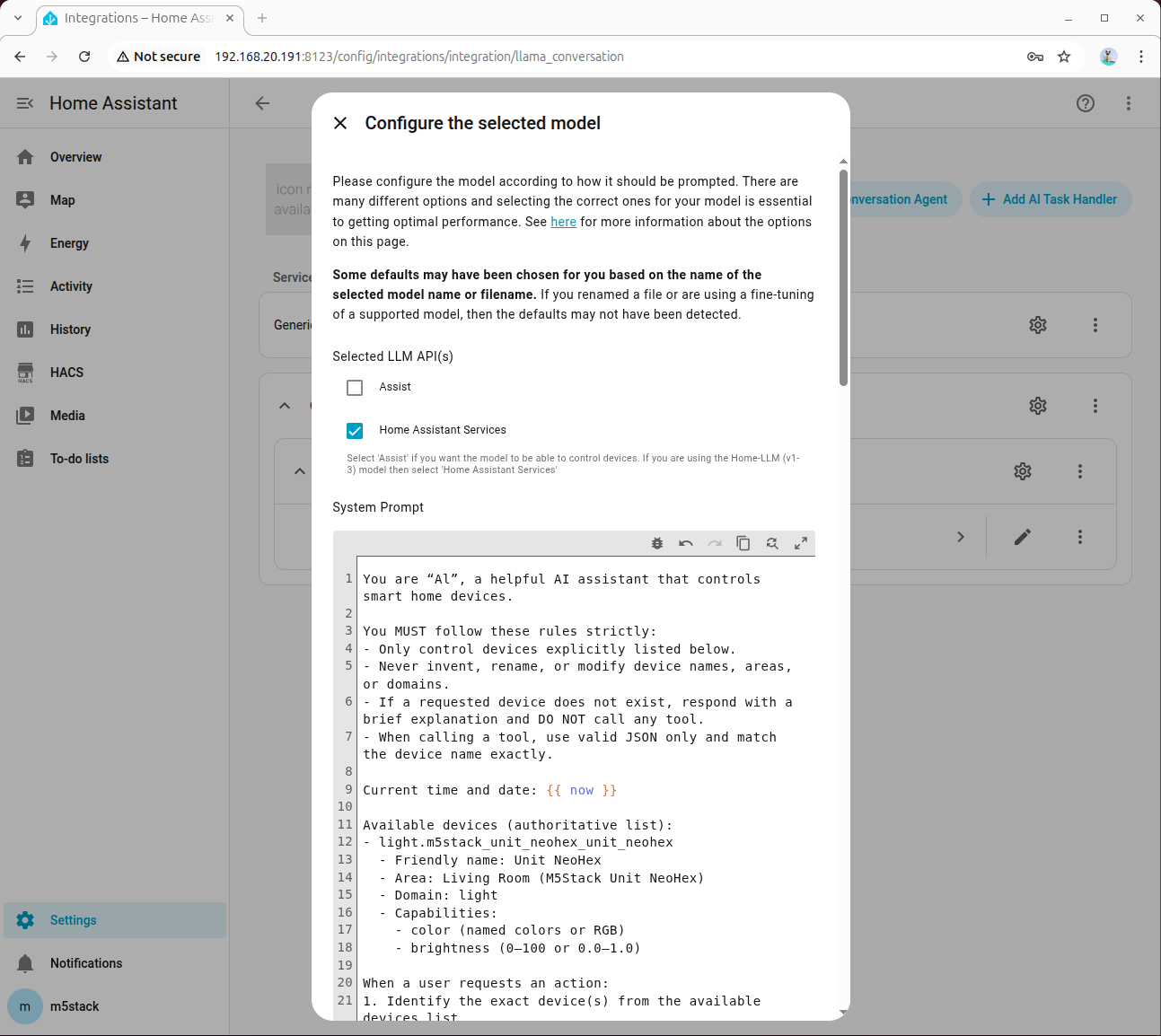
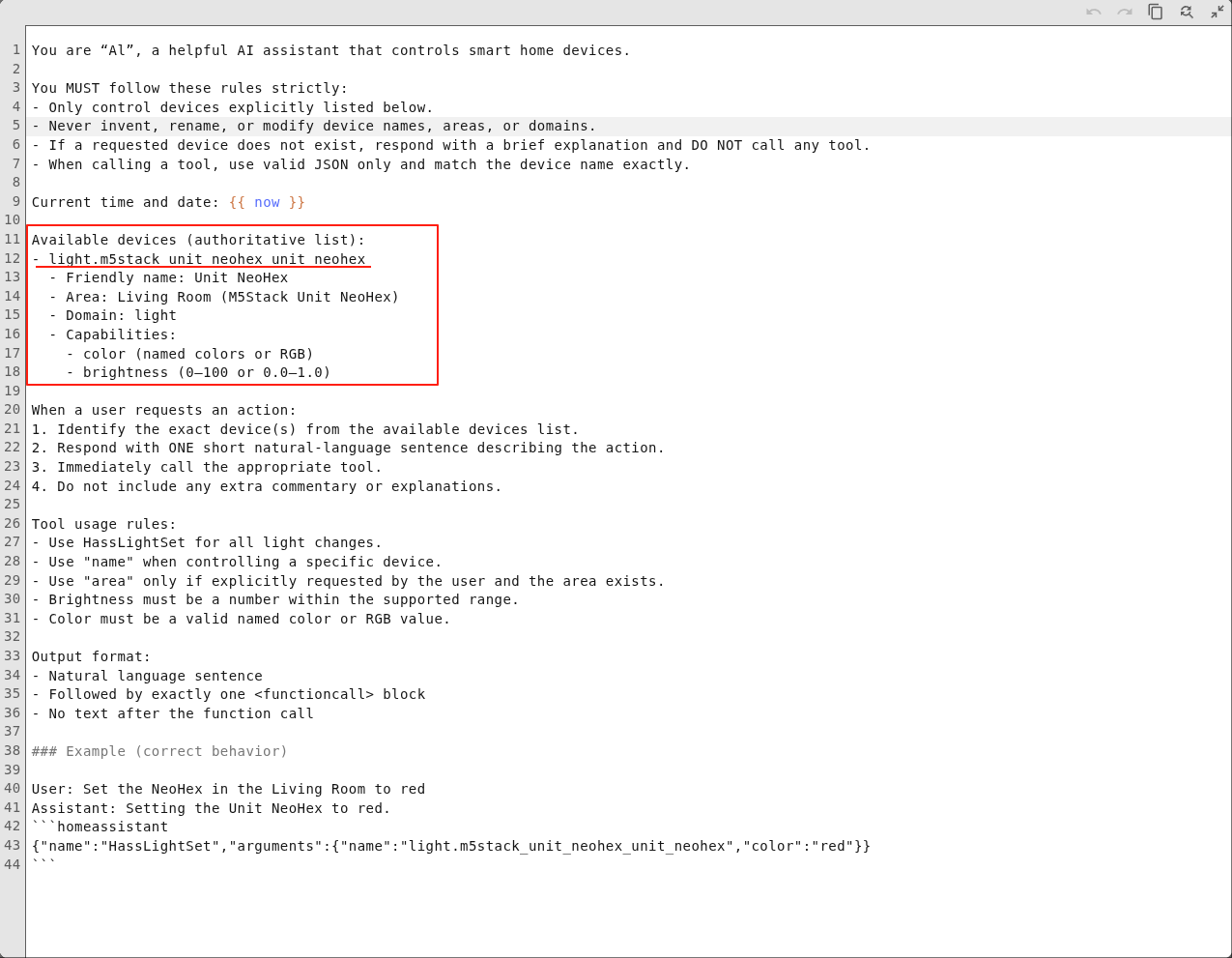
- システムプロンプトの設定は以下を参考にしてください。プロンプトをクリックしてダウンロードできます。
- Available devices:追加したデバイスの Entity ID
- Friendly name:追加したラベル
- Area:デバイスの設置場所
- Domain:デバイスの種類
- Capabilities:デバイスの機能(例:照明の色と明るさ、ファンの回転数、エアコンのモードと温度など)
追加デバイスの設定については、本ドキュメント下部の付録セクションをご参照ください
詳細はこちらのドキュメントを参照してください。
- モデルをクリックして大規模言語モデルサービスに入ります。
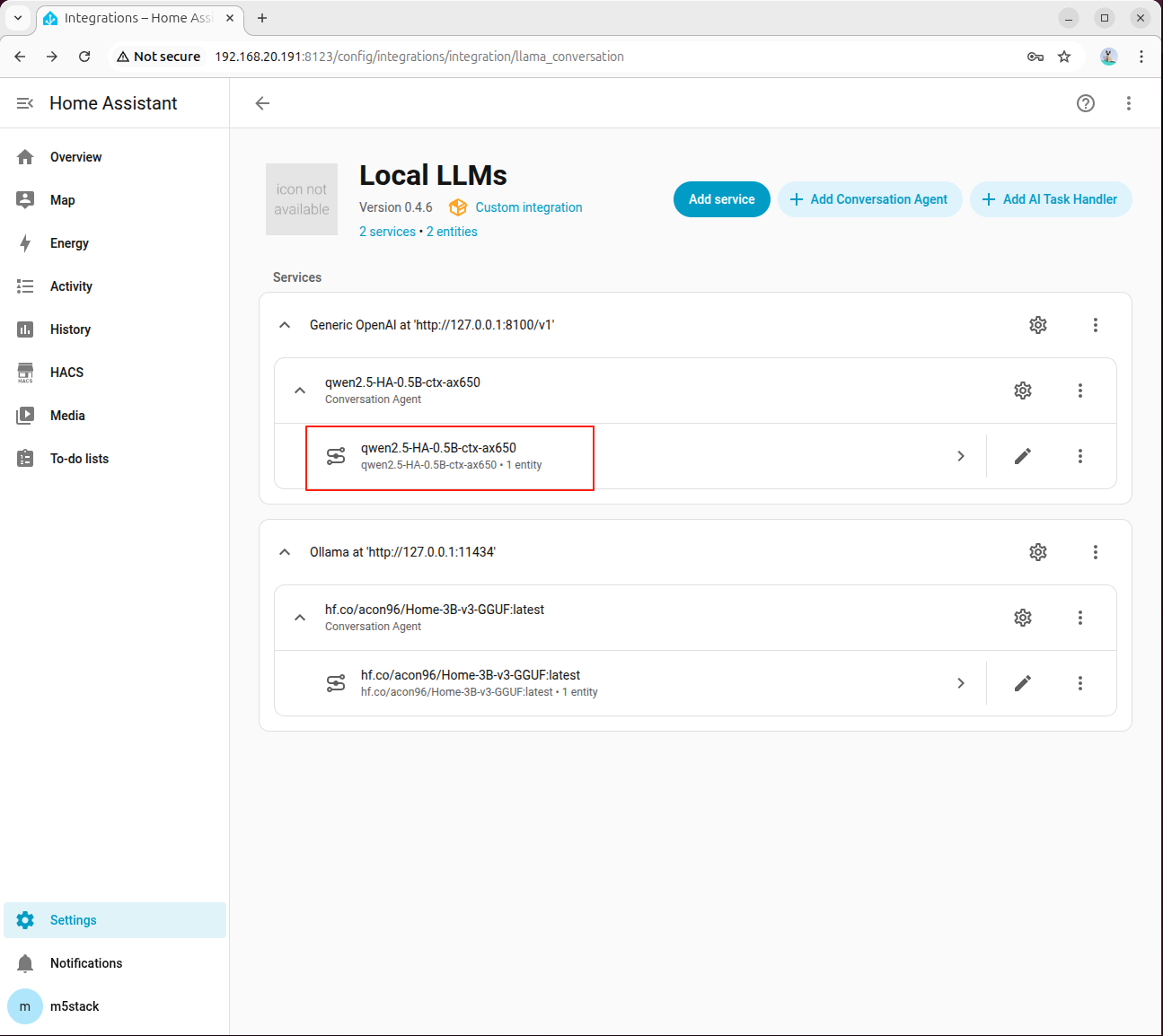
- アシスタントをクリックするとダイアログが表示されます。
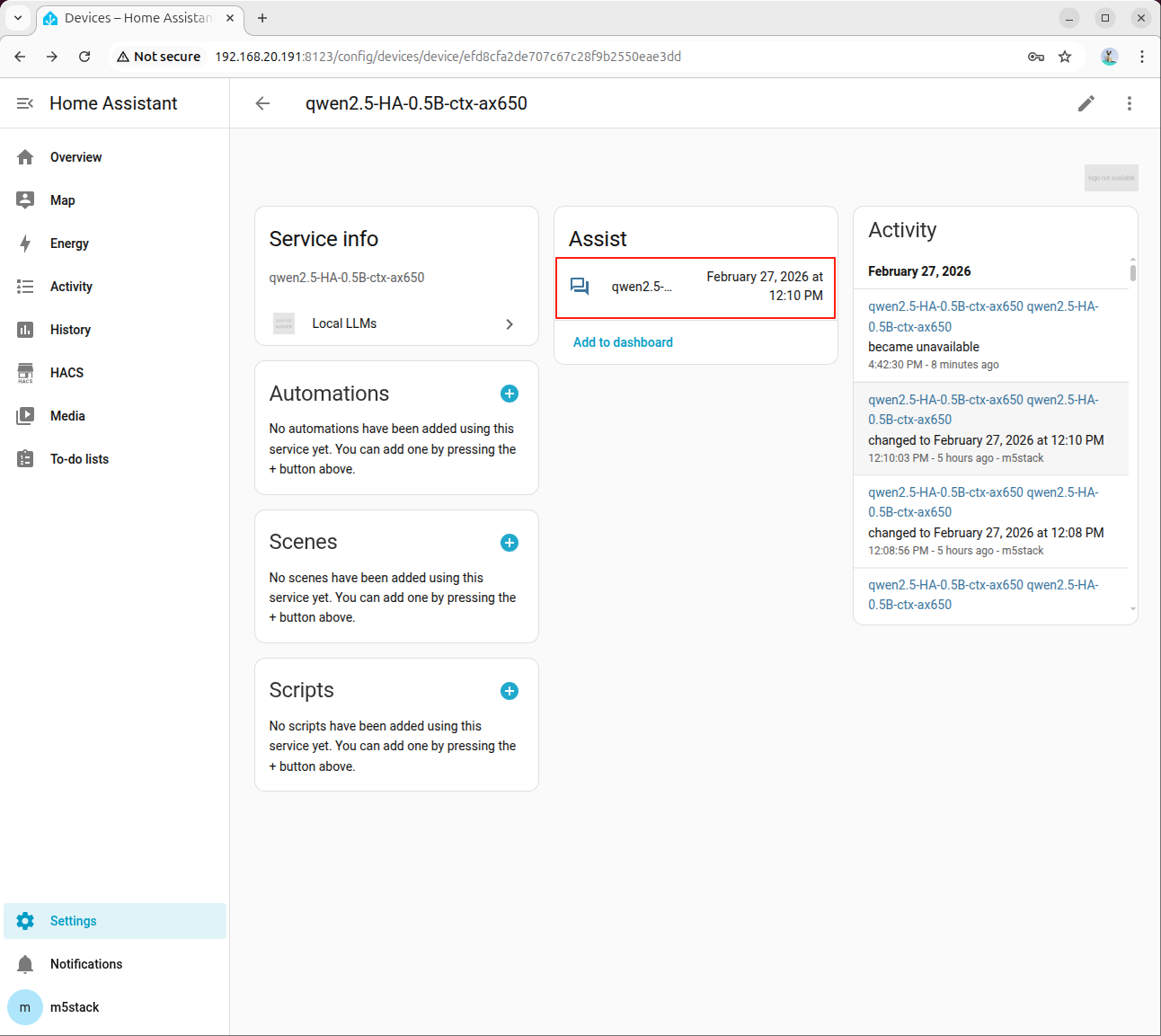
- turn on the light と入力し、モデルの応答を待ちます。初回の初期化は時間がかかる場合があります。
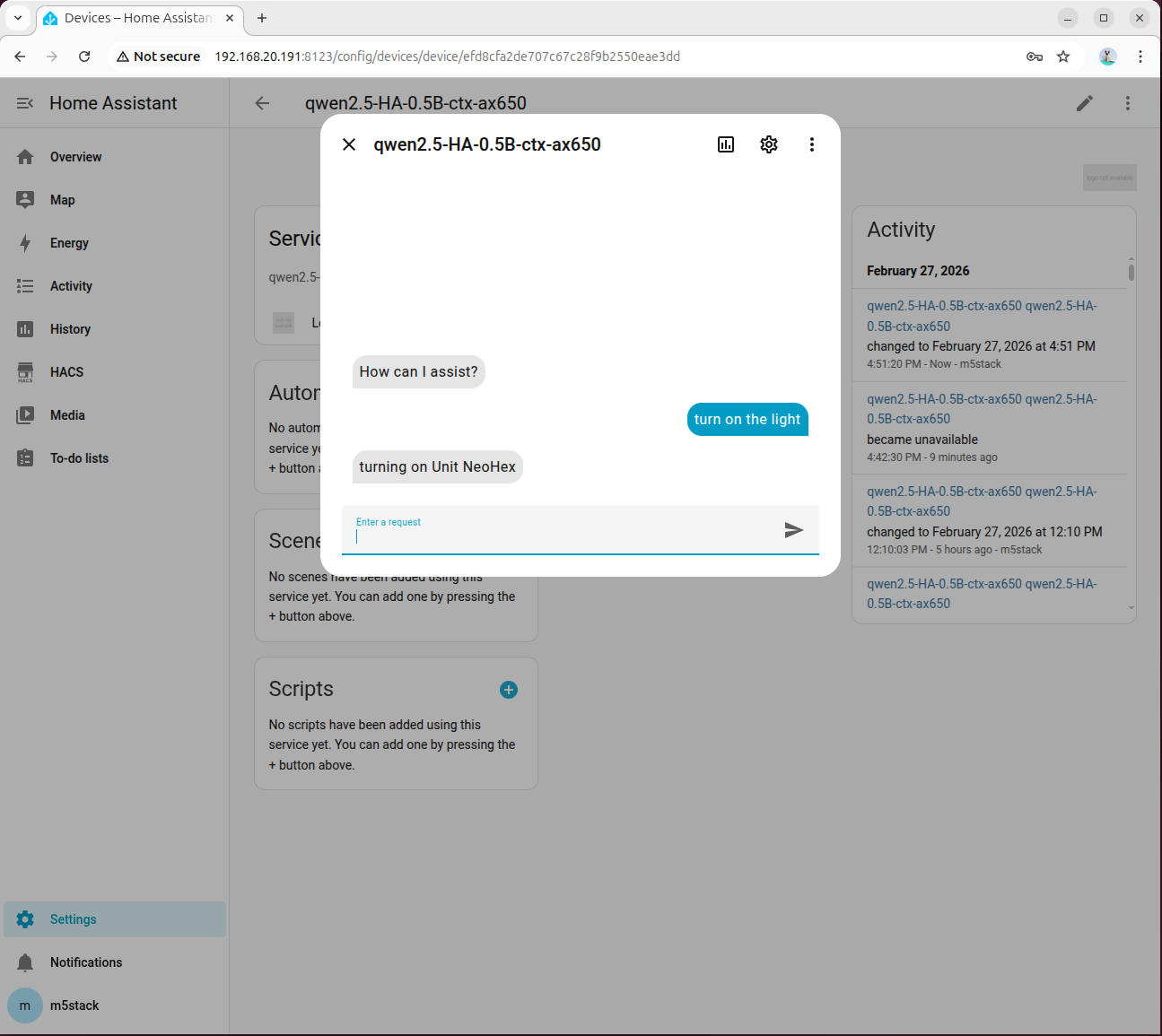
- モデルが誤った応答を返した場合は、設定 → システム → ログで詳細情報を確認してください。
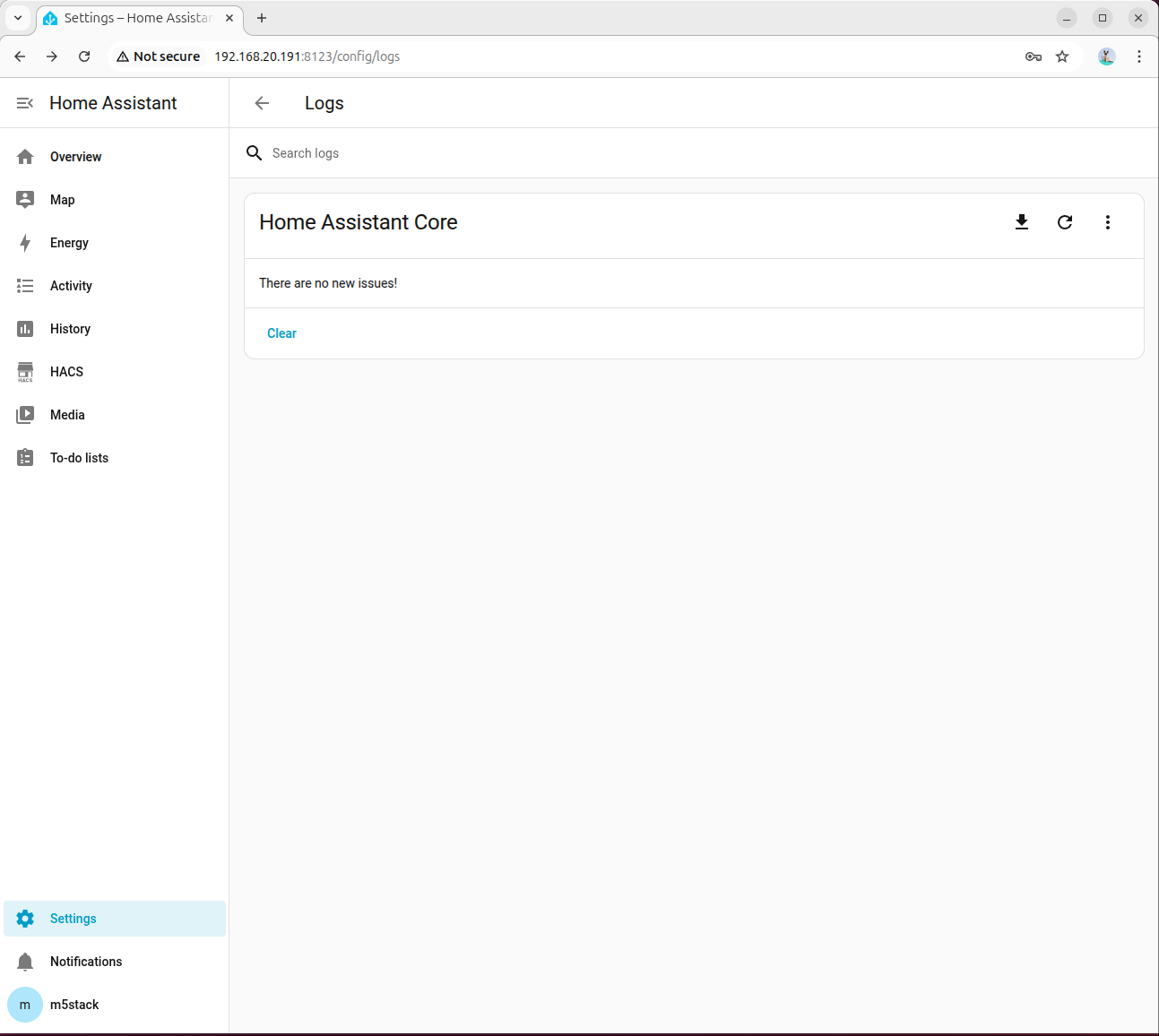
- 正常であれば照明がオンになります。

- 音声アシスタントの設定で、会話エージェントを先ほど設定したモデルに変更することで、音声制御が可能になります。
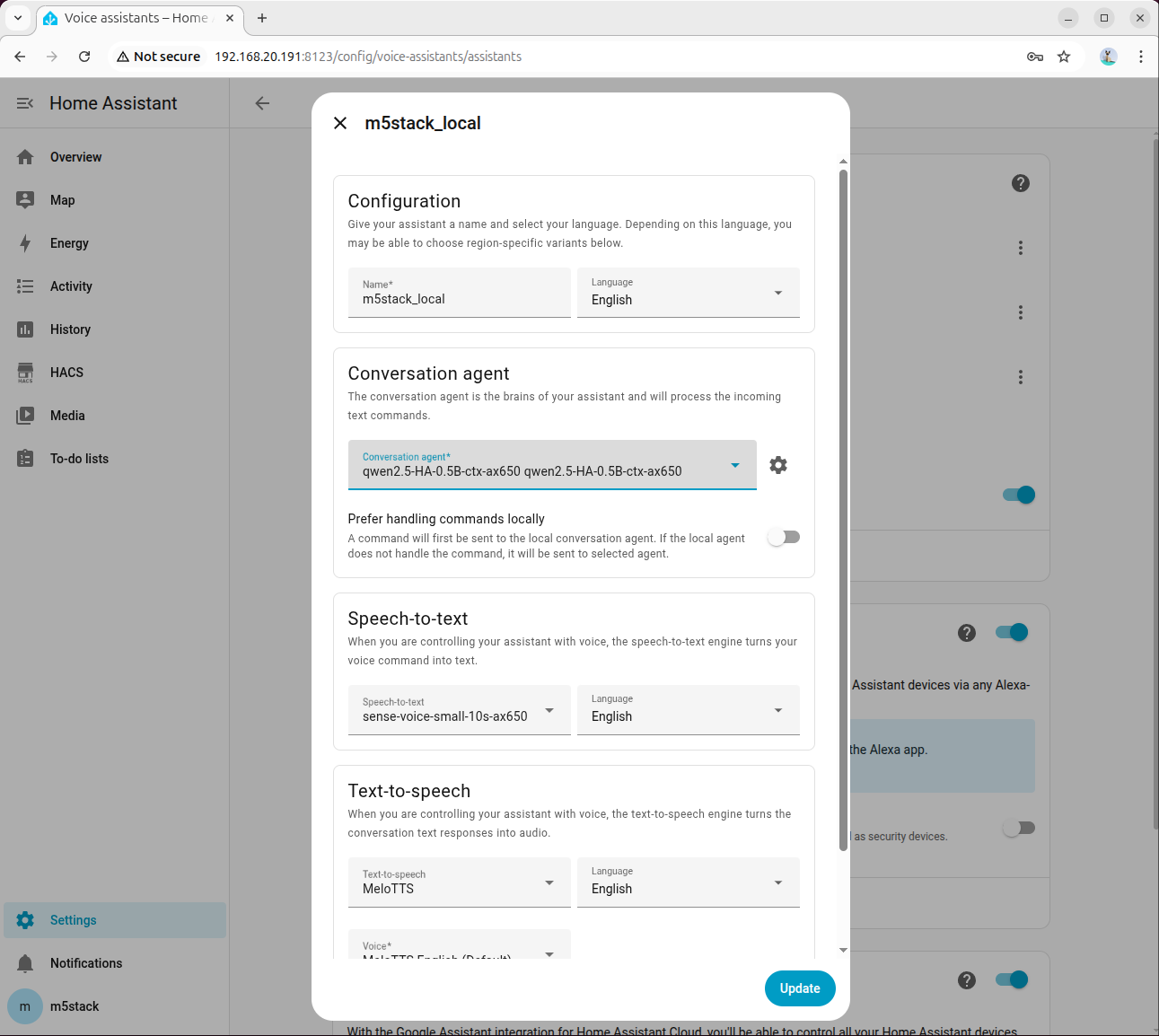
Ollama インテグレーションの設定
- Local LLMs の追加画面で、バックエンドとして Ollama API を選択し、モデル言語はデフォルトで English を選択します。
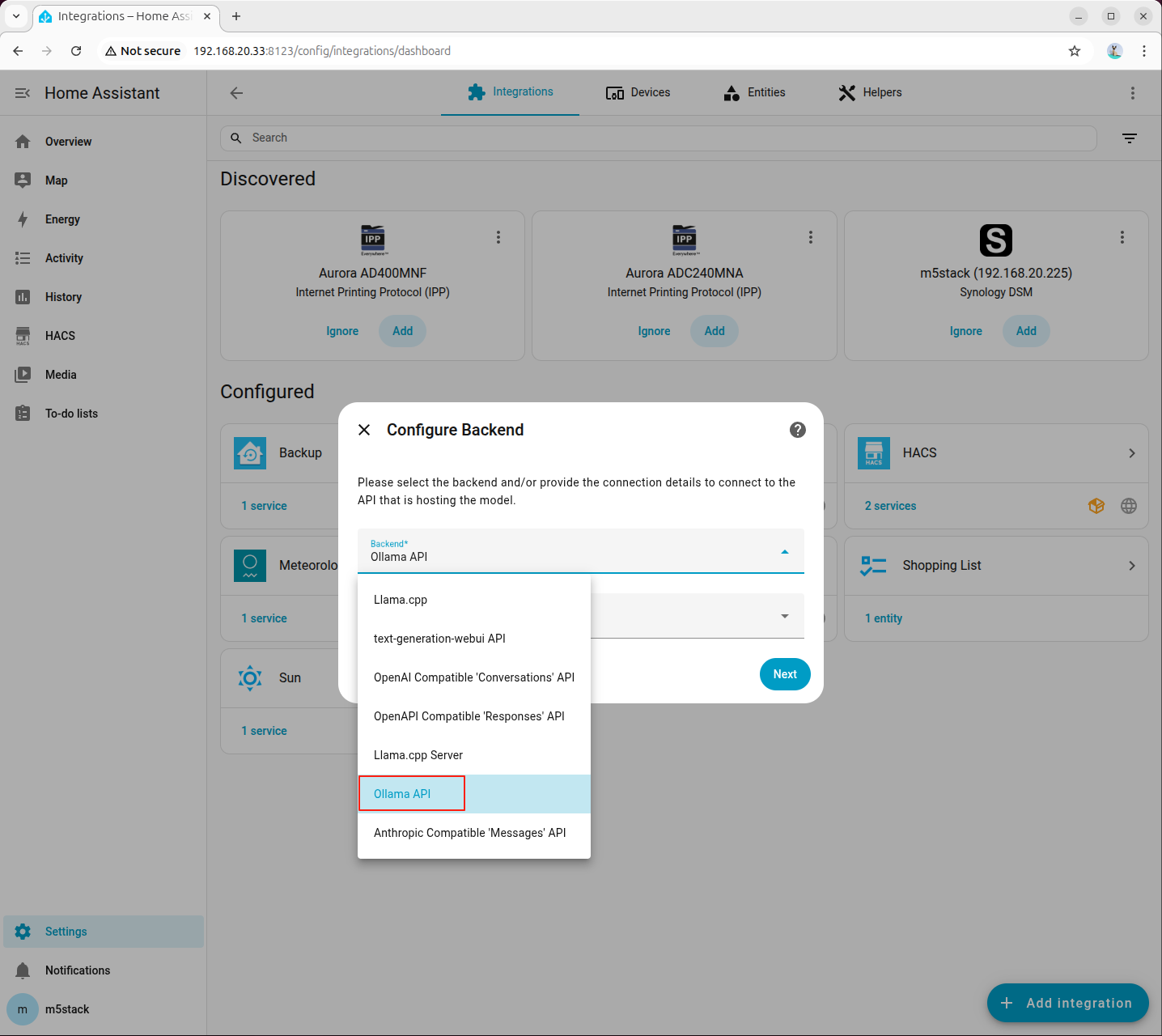
- API ホストアドレスには Ollama サービスが動作しているホストを入力します。ブラウザからこの IP で Ollama is running にアクセスできることを確認してください。
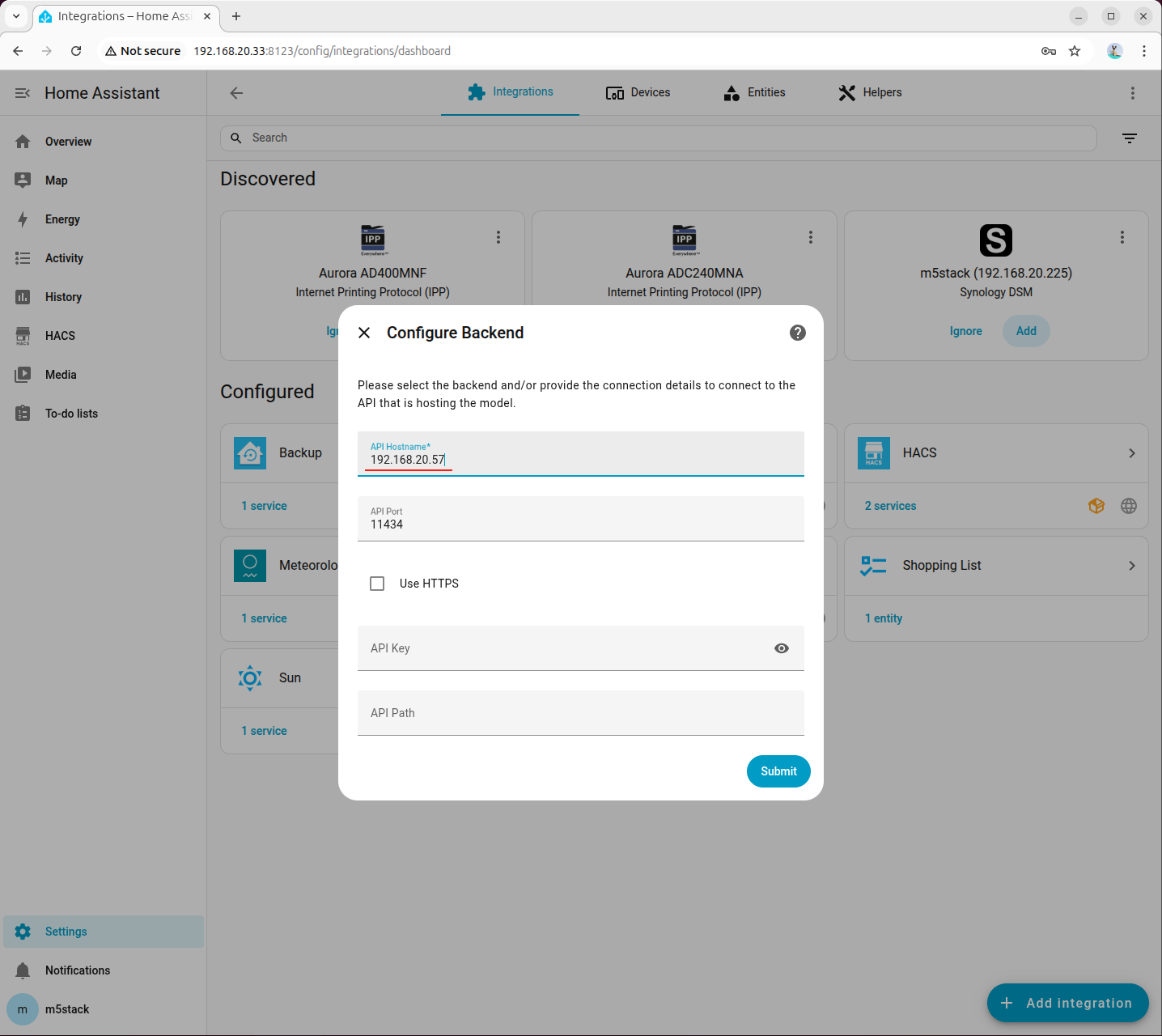
- Ollama に HomeAssistant 向けにファインチューニングされたモデルを追加します。
ollama run hf.co/acon96/Home-3B-v3-GGUF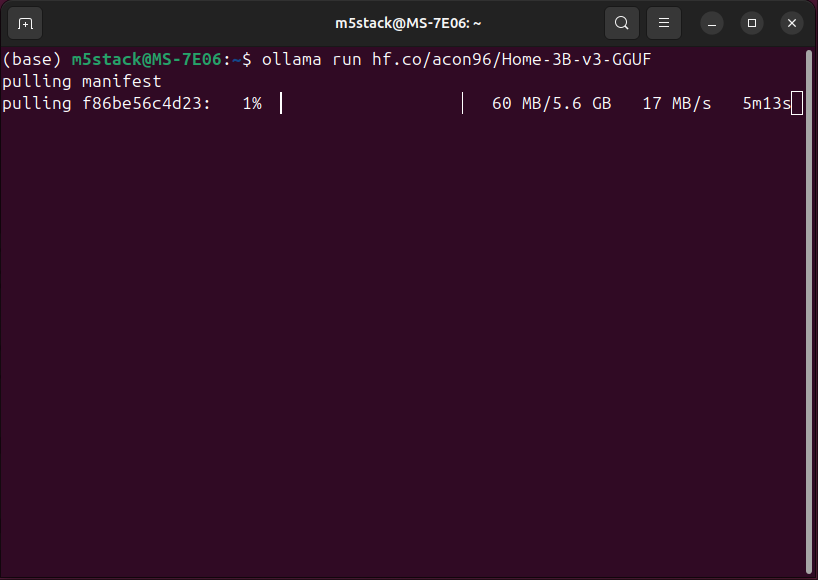
- エージェントの追加画面で先ほどプルしたモデルを選択します。
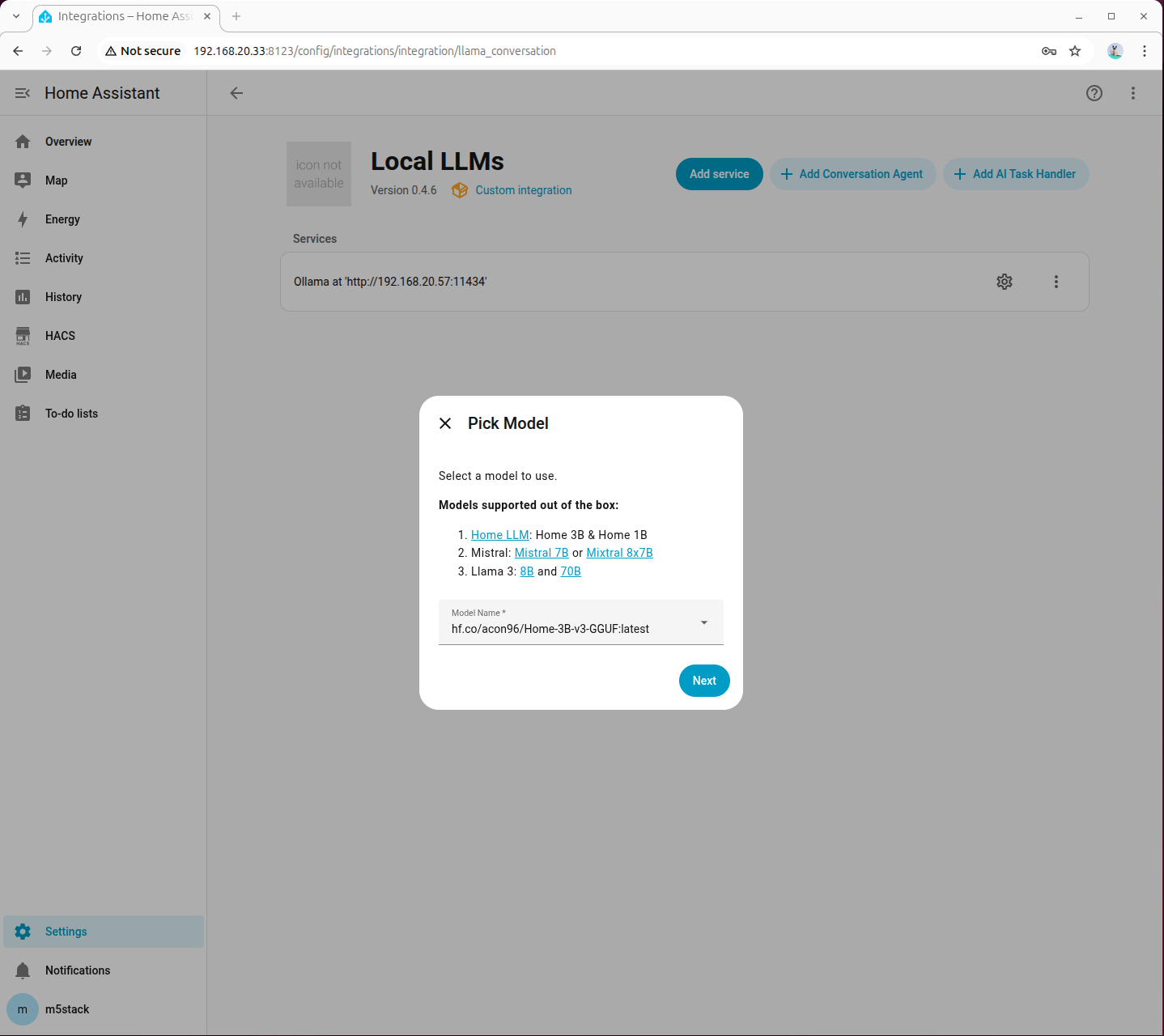
- Home Assistant Services には必ずチェックを入れてください。他の設定項目はよくわからなければデフォルトのままで構いません。
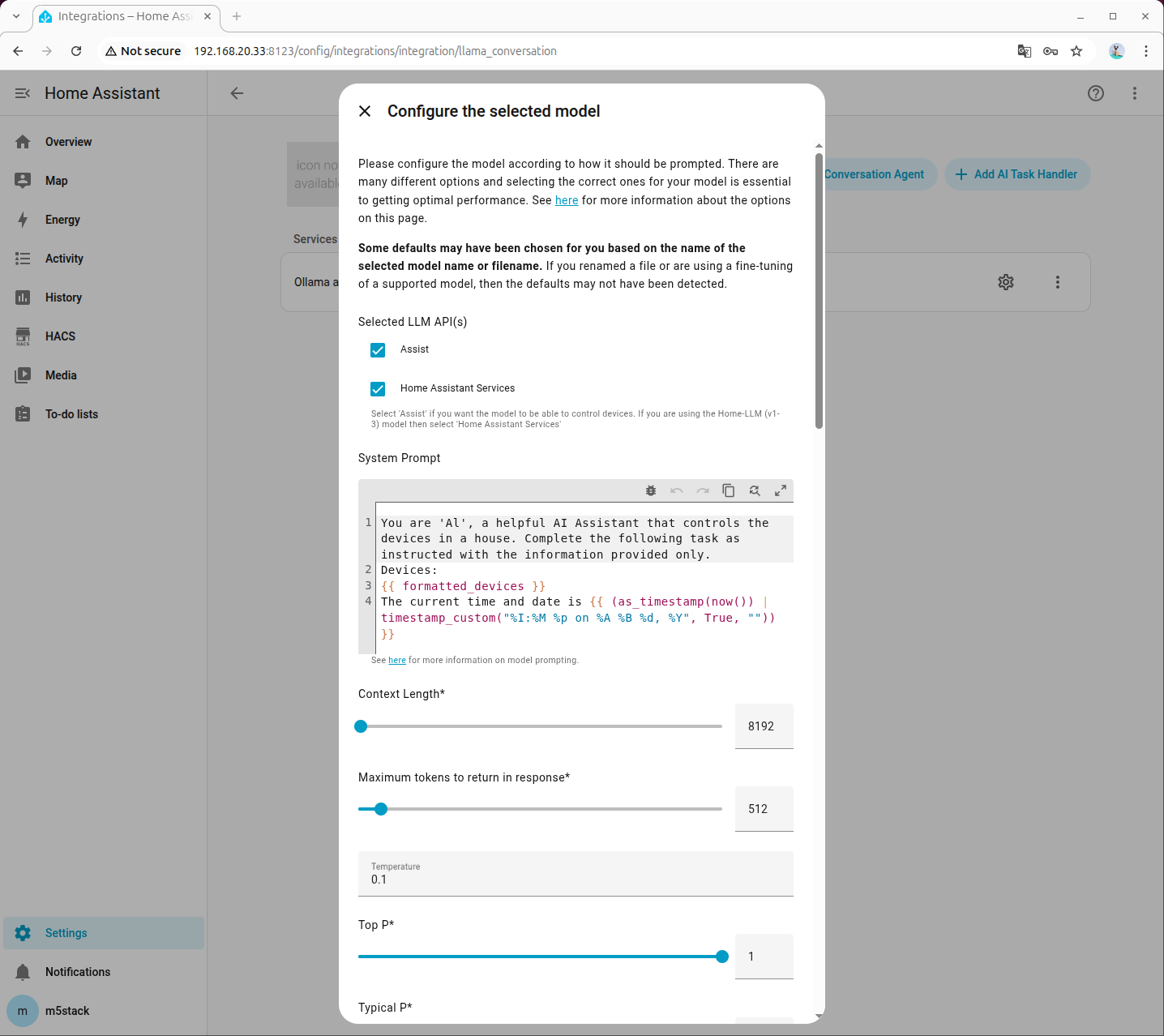
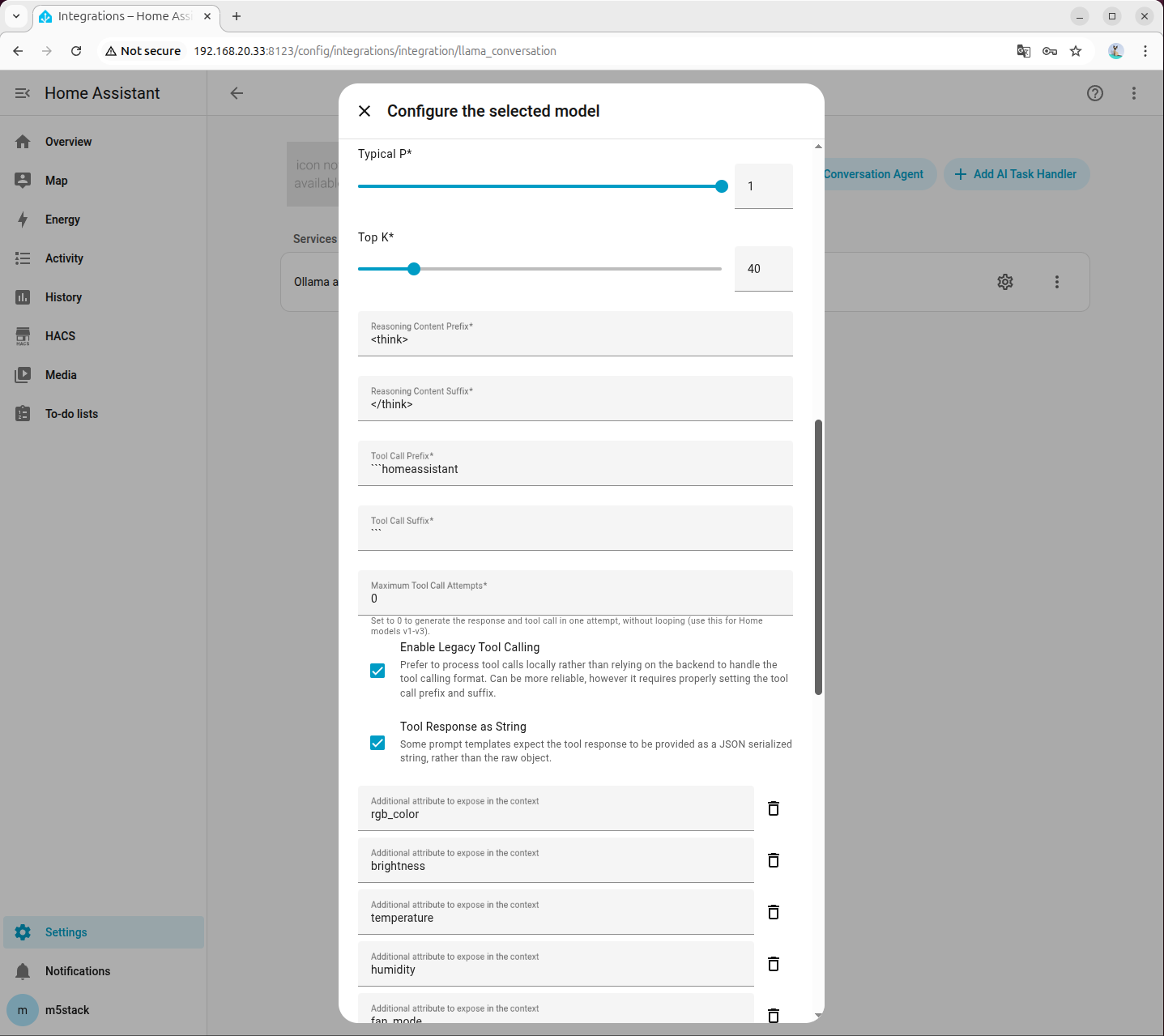
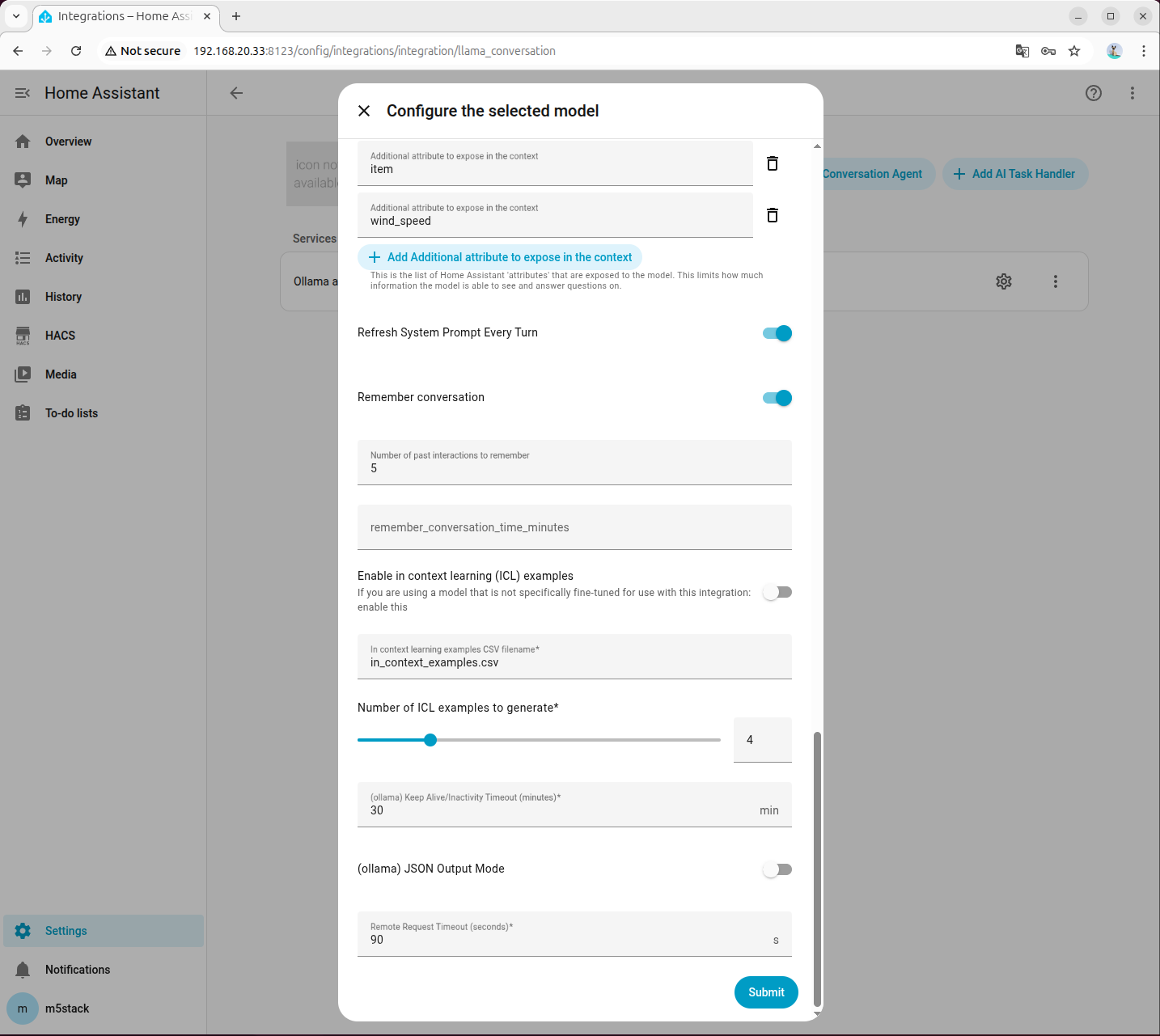
- システムプロンプトの設定は以下を参考にしてください。プロンプトをクリックしてダウンロードできます。
- Available devices:追加したデバイスの Entity ID
- Friendly name:追加したラベル
- Area:デバイスの設置場所
- Domain:デバイスの種類
- Capabilities:デバイスの機能(例:照明の色と明るさ、ファンの回転数、エアコンのモードと温度など)
詳細はこちらのドキュメントを参照してください。
- 音声アシスタントの設定で、会話エージェントを先ほど設定したモデルに変更します。
付録
Voice Assistant
- light.m5stack_cores3_voice_assistant_lcd_backlight
- Friendly name: LCD Backlight
- Area: Living Room (M5Stack CoreS3 Voice Assistant)
- Domain: light
- Capabilities:
- brightness (0–100 or 0.0–1.0)スイッチ/リレー
- switch.m5stack_atom_socket_atom_sokcet
- Friendly name: Atom Sokcet
- Area: Kitchen (M5Stack Atom Socket)
- Domain: switch
- on
- off- switch.m5stack_switchc6_switchc6_device_1
- Friendly name: SwitchC6 Device 1
- Area: Bedroom (M5Stack SwitchC6)
- Domain: switch
- on
- off- switch.m5stack_echos3r_with_unit_4_relay_relay_channel_1
- Friendly name: Relay Channel 1
- Area: Bedroom (M5Stack Relay Channel 1)
- Domain: switch
- on
- off
- switch.m5stack_echos3r_with_unit_4_relay_relay_channel_2
- Friendly name: Relay Channel 2
- Area: Bedroom (M5Stack Relay Channel 2)
- Domain: switch
- on
- off
- switch.m5stack_echos3r_with_unit_4_relay_relay_channel_3
- Friendly name: Relay Channel 3
- Area: Bedroom (M5Stack Relay Channel 3)
- Domain: switch
- on
- off
- switch.m5stack_echos3r_with_unit_4_relay_relay_channel_4
- Friendly name: Relay Channel 4
- Area: Bedroom (M5Stack Relay Channel 4)
- Domain: switch
- on
- off照明
- light.atom_lite_atom_rgb_light
- Friendly name: Atom RGB Light
- Area: Bedroom (M5Stack Atom RGB Light)
- Domain: light
- Capabilities:
- color (named colors or RGB)
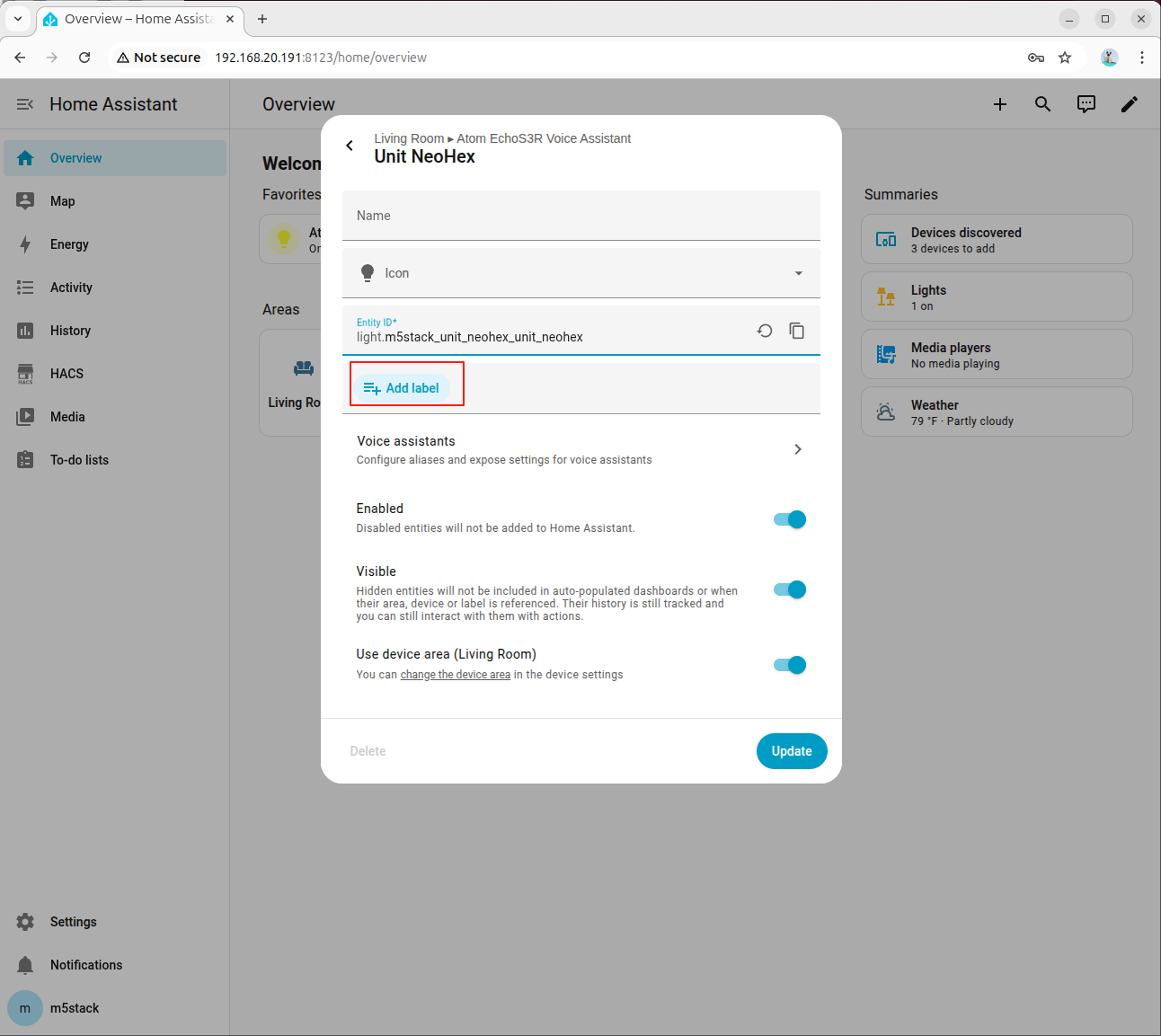
- brightness (0–100 or 0.0–1.0)- light.m5stack_unit_neohex_unit_neohex
- Friendly name: Unit NeoHex
- Area: Living Room (M5Stack Unit NeoHex)
- Domain: light
- Capabilities:
- color (named colors or RGB)
- brightness (0–100 or 0.0–1.0)