


产品上手指引
Linux PC
CardputerZero
AI 加速卡
LLM-8850 Card
AI 智能体
实时 AI 语音助手
火山引擎语音助手
工业控制
Ethernet 摄像头
PoECAM
Wi-Fi 摄像头
Unit CamS3/-5MP
AI 摄像头
LoRa & LoRaWAN
电机驱动
恢复出厂固件教程
拨码开关&引脚切换
V-Training
准备工作
登录平台
通过M5Stack的V-Training(Ai模型训练服务),轻松构建自定义识别模型。使用手机或是其他摄像设备拍摄图片素材并保存至电脑,使用浏览器访问V-Training在线训练平台,注册登录账户(M5论坛用户账户可直接登录)

导入图片
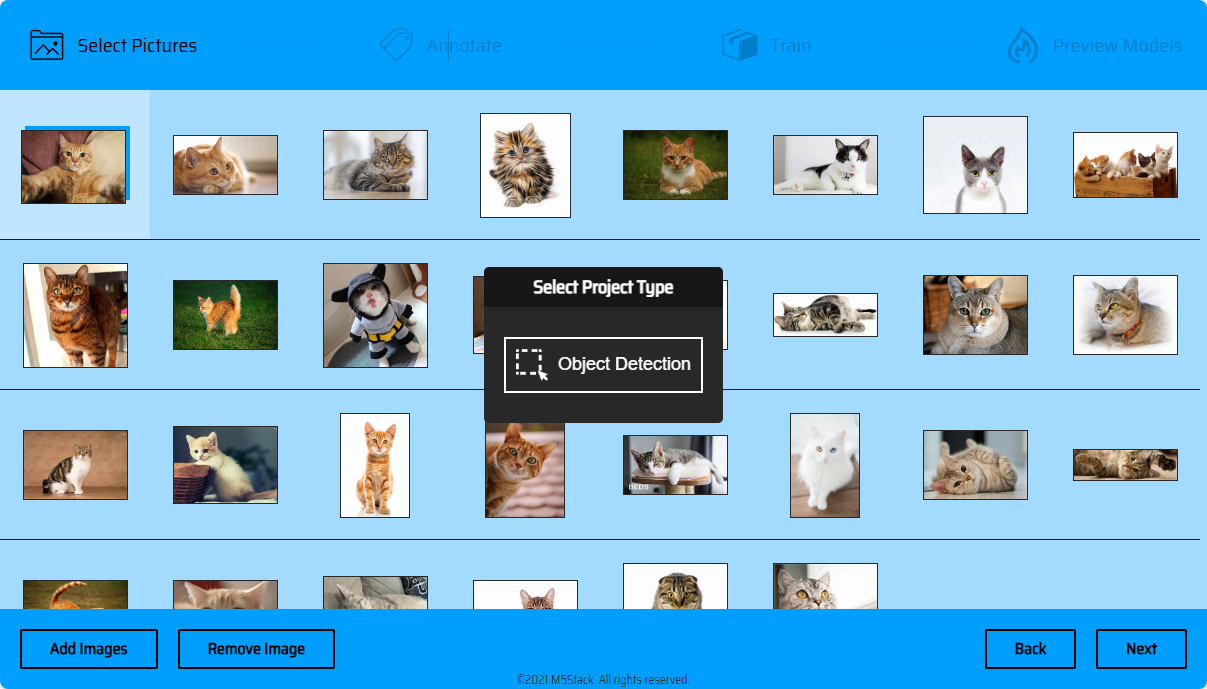
Start->新建项目->导入图片->NEXT->Object Detection。注意事项:训练集质量与数量将直接影响训练的模型质量,因此在进行训练集拍摄或收集时,请尽可能提供高质量训练素材。数量越多越好,素材拍摄场景要贴合实际识别的场景。注意:
图像训练集整体大小不允许超过200M
素材处理
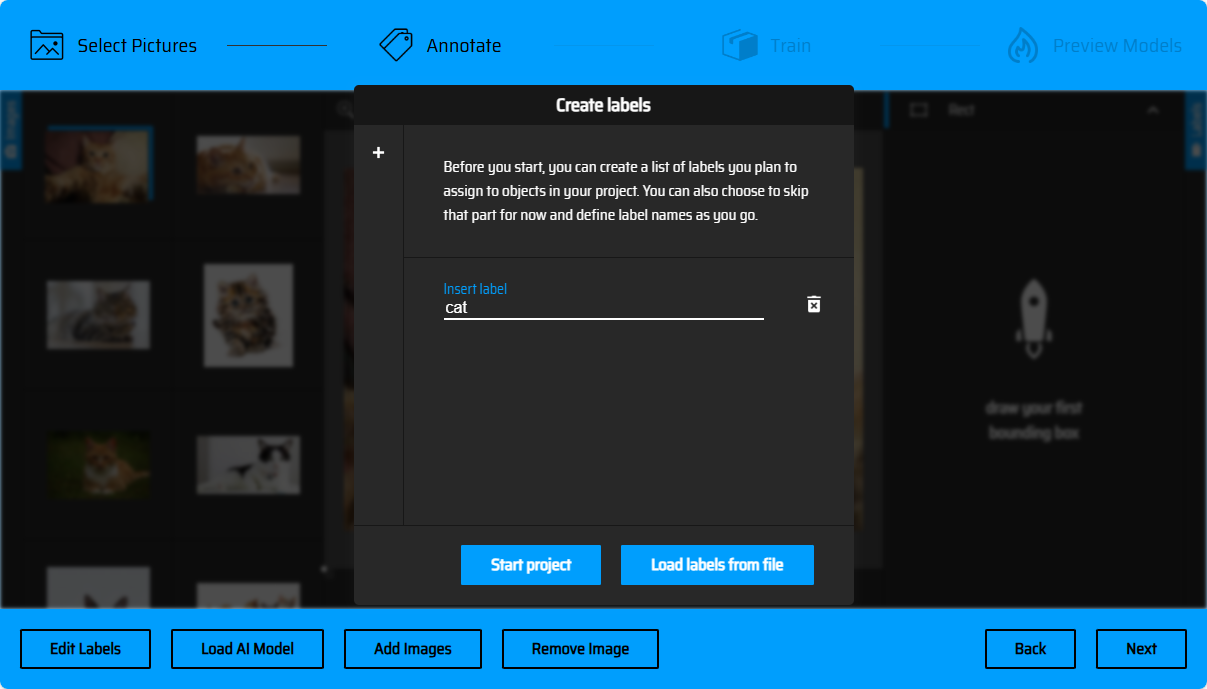
创建标签
在进行对象框选前,我们需要为识别的对象创建一个标签名,在后续的图像标记操作中,需要根据不同的对象,选择对应的标签进行框选。(可以点击弹窗左侧的+号创建多个标签)。 你也可以通过文本文件的形式批量导入标签(Load Labels from file),文件格式为txt,文件内容每一行为一个标签名。(如下方所示)
//Labels.txt
Dog
Cat
Bird
标记图像
创建完成标签后,接下来就是标记图像环节,我们需要将训练集素材中需要进行识别的对象框选出来。页面左侧为需要处理的图像列表,根据角标你可以知道有哪些图片已经处理。
手动标记
点击底栏的箭头可以切换图像(或是通过按下键盘<-左->右按键,进行图片切换),右侧菜单栏为标签列表,在进行框选后,你可以根据框选的对象指定响应的标签。
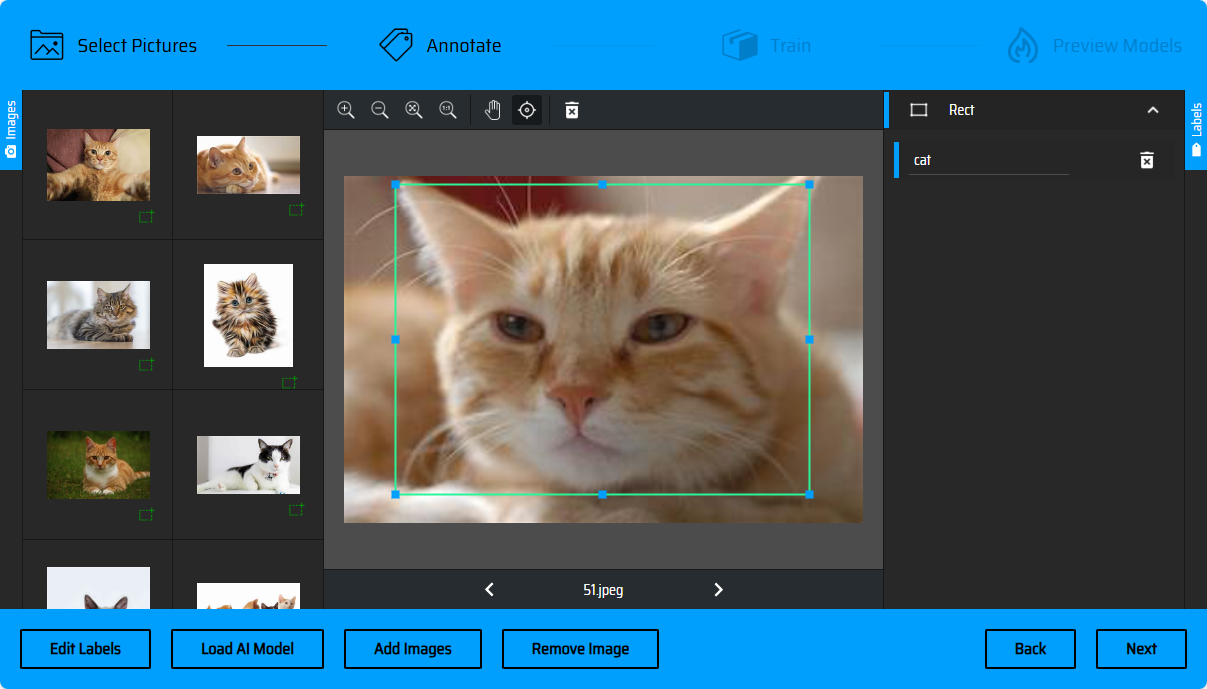
AI自动标记
批量处理素材时,你也可以尝试使用AI自动标记功能来提高标记效率。点击左下角的Load AI Model->勾选COCO SSD - object detection using rectangles->Use model!。等待框选模型载入完成后,页面颜色将变化为绿色。此时可以勾选上一步创建的标签名添加到列表中,用于后续的标记,点击Accept。
AI将会自动标记图片中能够识别到的对象,并进行框选,接下来你需要做的是,审核每一张图片的框选。当AI识别到某一类别的对象,将会弹出classs选择框,你可以勾选AI推荐的标签类别添加到标签列表中,或是直接点击Accept,进行下一步操作,使用标签列表中已有标签进行分类标记。
识别框选正确的则点击选框上的+进行添加。(或是按下Enter进行确认),识别框选错误的也可以点击选框上的删除按钮移除并手动框选。AI完成框选后,你也可以在右侧的标签栏中,将选框指定为其他的标签。
模型训练
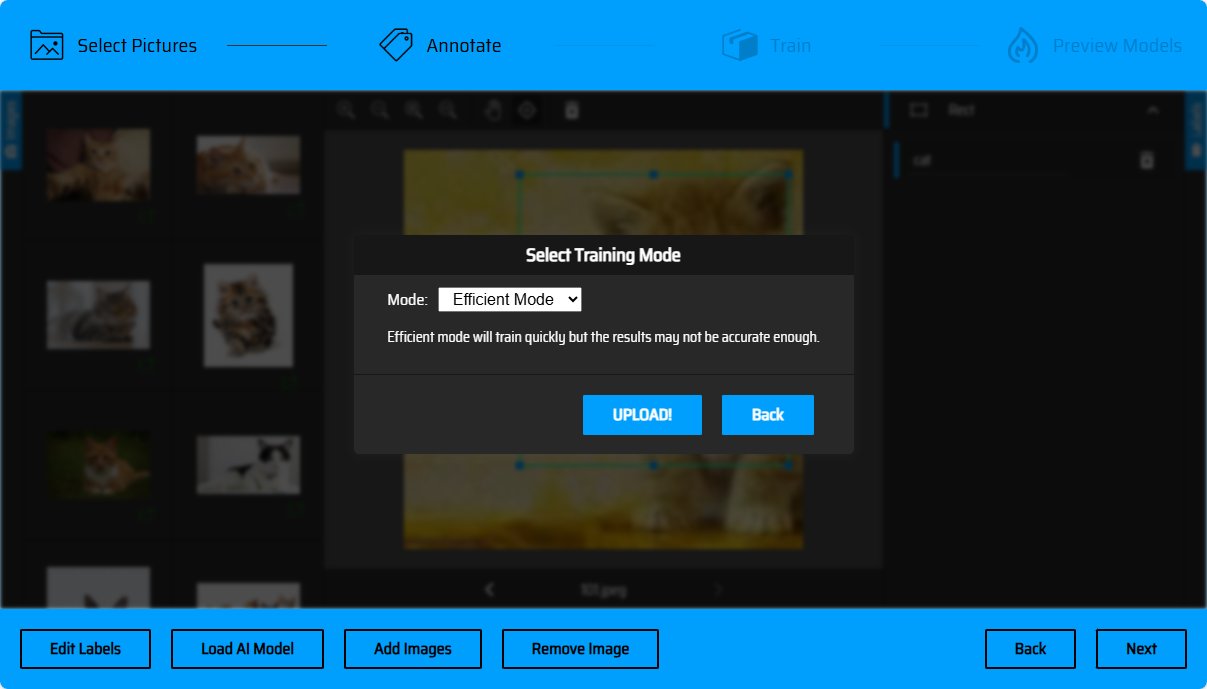
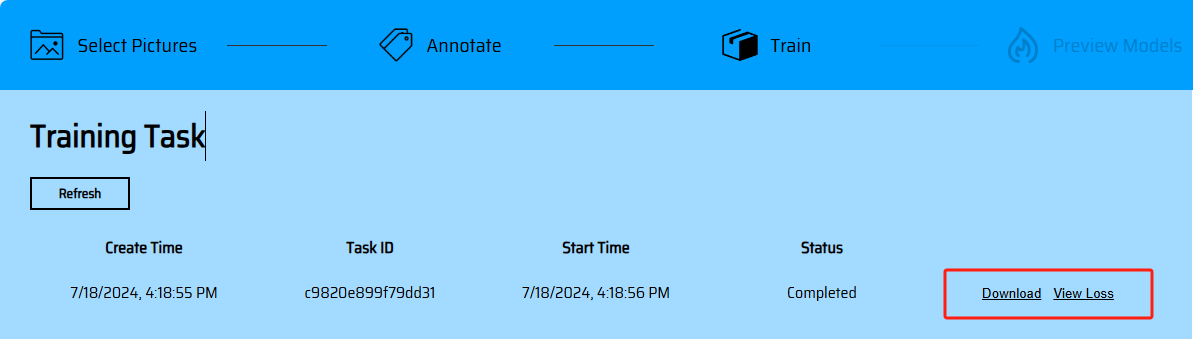
完成框选后,点击下一步上传素材(若存在未进行标记的素材,在该页面将进行提示),点击UPLOAD进行素材上传(目前支持的efficient高效率训练模式),将跳转到任务列表。点击Refresh可以刷新查看任务最新状态,训练完成后,将获得模型Download下载链接,以及损失曲线。
模型在线预览
模型在线预览功能还在开发阶段,目前用户可以通过程序加载模型体验识别效果。
程序加载模型
运行模型
Ethernet模式连接: UnitV2内置了一张有线网卡, 当你通过Type-C接口连接PC时,将自动与UnitV2建立起网络连接。AP模式连接: UnitV2启动后,将默认开启AP热点(SSID: M5UV2_XXX: PWD:12345678),用户可以通过WiFi接入与UnitV2建立起网络连接。
通过以上两种模式之一连接到UnitV2设备,访问域名unitv2.py或IP:10.254.239.1访问通过识别功能的预览网页。切换功能至Object Recognition,点击add按键上传模型。注意: 使用前请安装SR9900驱动,详情安装步骤可参考,前面章节Jupyter notebook
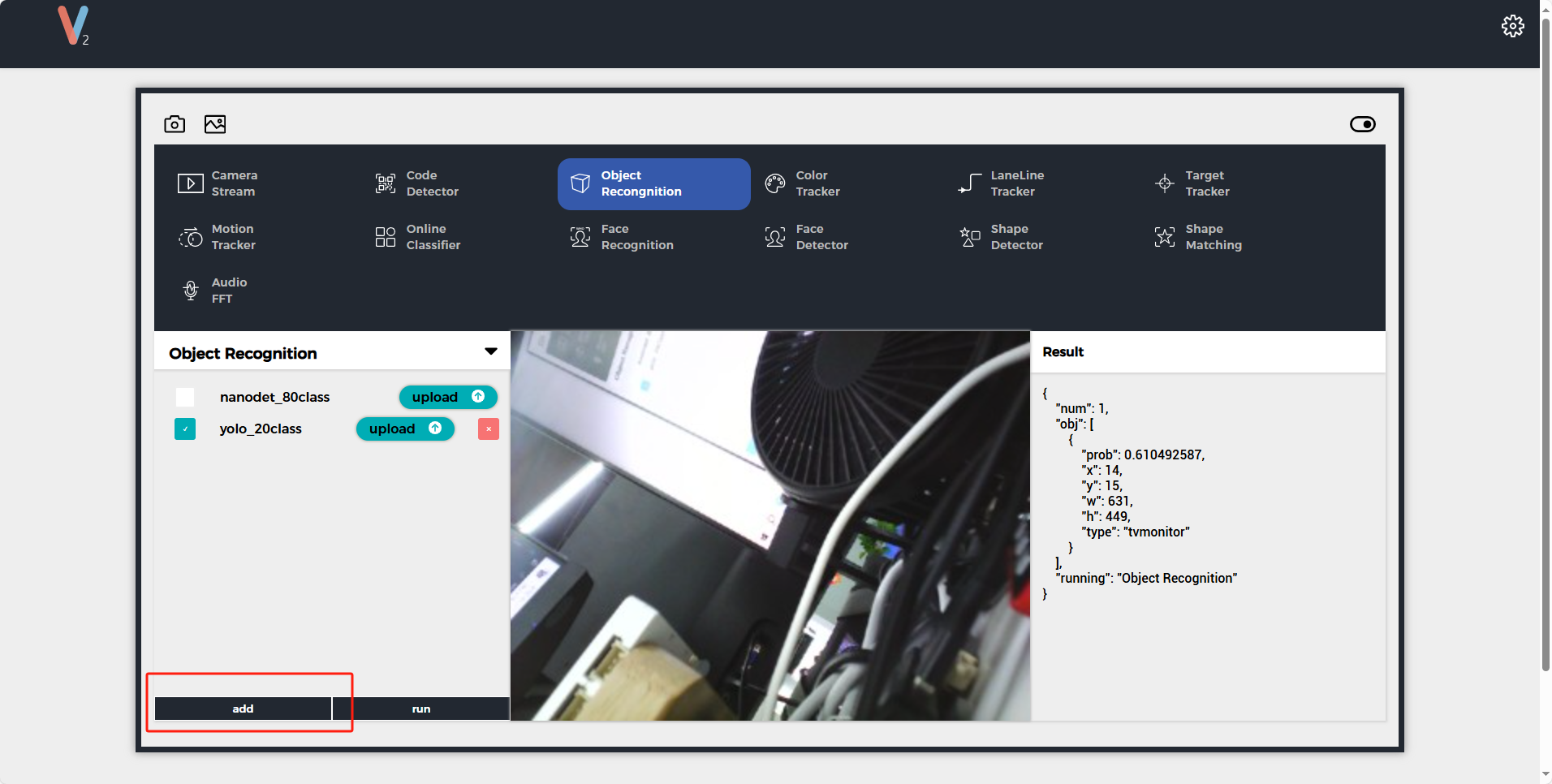
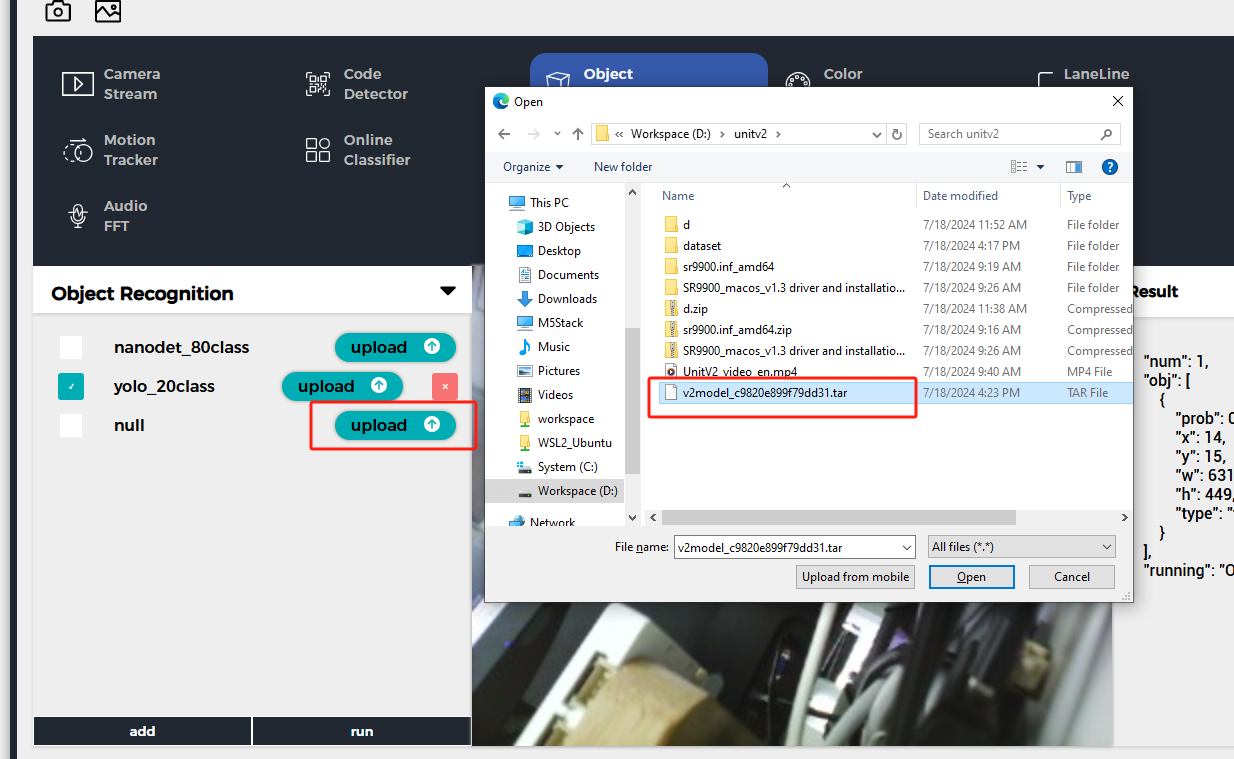
上传完成后点击run即可开始使用模型。识别过程中,UnitV2将通过串口(底部HY2.0-4P接口)不断输出识别样本数据(JSON格式,UART: 115200bps 8N1)
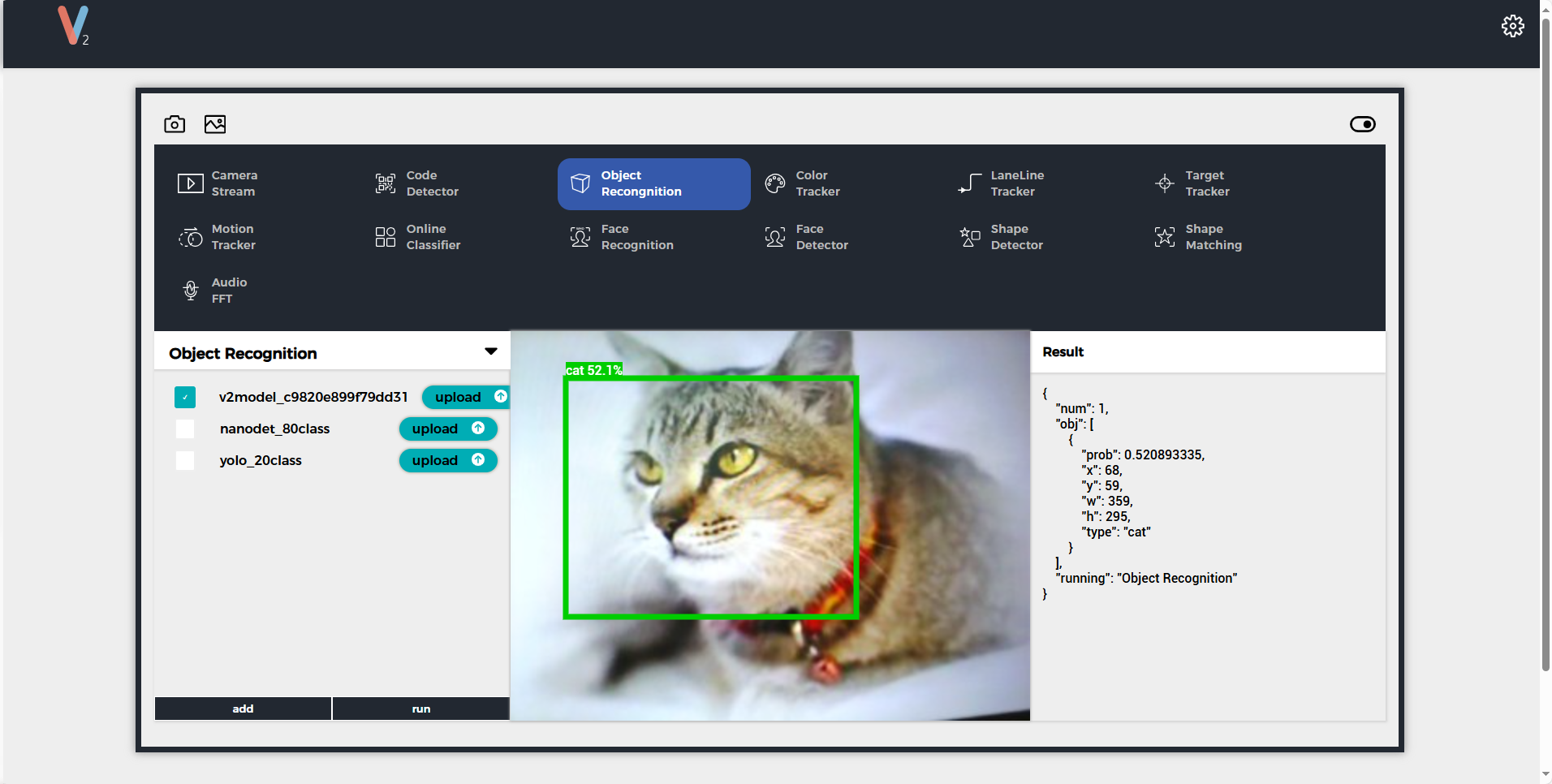
样例输出
{
"num": 1,
"obj": [
{
"prob": 0.938137174,
"x": 179,
"y": 186,
"w": 330,
"h": 273,
"type": "dog"
}
],
"running": "Object Recognition"
}
使用python调用模型文件
from json.decoder import JSONDecodeError
import subprocess
import json
import base64
reconizer = subprocess.Popen(['/home/m5stack/payload/bin/object_recognition', '/home/m5stack/payload/uploads/models/nanodet_80class'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
reconizer.stdin.write("_{\"stream\":1}\r\n".encode('utf-8'))
reconizer.stdin.flush()
img = b''
while 1:
doc = json.loads(reconizer.stdout.readline().decode('utf-8'))
print(doc)
if 'img' in doc:
byte_data = base64.b64decode(doc["img"])
img = bytes(byte_data)
elif 'num' in doc:
for obj in doc['obj']:
print(obj)